 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Single-Index Bandits: Estimation, Inference, and Learning
Mar 19, 2026We study contextual bandits with finitely many actions in which the reward of each arm follows a single-index model with an arm-specific index parameter and an unknown nonparametric link function. We consider a regime in which arms correspond to stable decision options and covariates evolve adaptively under the bandit policy. This setting creates significant statistical challenges: the sampling distribution depends on the allocation rule, observations are dependent over time, and inverse-propensity weighting induces variance inflation. We propose a kernelized $\varepsilon$-greedy algorithm that combines Stein-based estimation of the index parameters with inverse-propensity-weighted kernel ridge regression for the reward functions. This approach enables flexible semiparametric learning while retaining interpretability. Our analysis develops new tools for inference with adaptively collected data. We establish asymptotic normality for the single-index estimator under adaptive sampling, yielding valid confidence regions, and derive a directional functional central limit theorem for the RKHS estimator, which provides asymptotically valid pointwise confidence intervals. The analysis relies on concentration bounds for inverse-weighted Gram matrices together with martingale central limit theorems. We further obtain finite-time regret guarantees, including $\tilde{O}(\sqrt{T})$ rates under common-link Lipschitz conditions, showing that semiparametric structure can be exploited without sacrificing statistical efficiency. These results provide a unified framework for simultaneous learning and inference in single-index contextual bandits.
Minimax Optimal Kernel Two-Sample Tests with Random Features
Feb 28, 2025Reproducing Kernel Hilbert Space (RKHS) embedding of probability distributions has proved to be an effective approach, via MMD (maximum mean discrepancy) for nonparametric hypothesis testing problems involving distributions defined over general (non-Euclidean) domains. While a substantial amount of work has been done on this topic, only recently, minimax optimal two-sample tests have been constructed that incorporate, unlike MMD, both the mean element and a regularized version of the covariance operator. However, as with most kernel algorithms, the computational complexity of the optimal test scales cubically in the sample size, limiting its applicability. In this paper, we propose a spectral regularized two-sample test based on random Fourier feature (RFF) approximation and investigate the trade-offs between statistical optimality and computational efficiency. We show the proposed test to be minimax optimal if the approximation order of RFF (which depends on the smoothness of the likelihood ratio and the decay rate of the eigenvalues of the integral operator) is sufficiently large. We develop a practically implementable permutation-based version of the proposed test with a data-adaptive strategy for selecting the regularization parameter and the kernel. Finally, through numerical experiments on simulated and benchmark datasets, we demonstrate that the proposed RFF-based test is computationally efficient and performs almost similar (with a small drop in power) to the exact test.
Uniform Kernel Prober
Feb 11, 2025

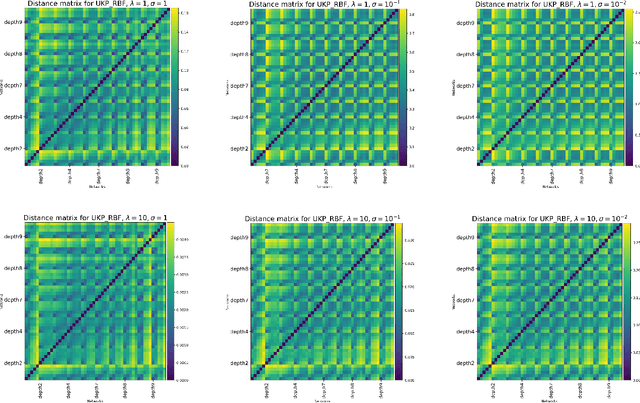
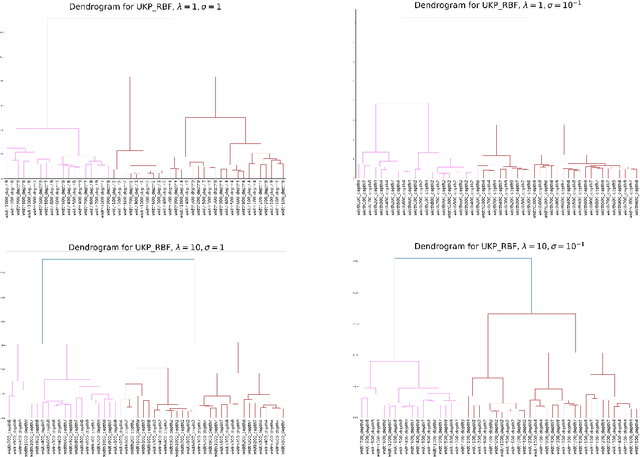
The ability to identify useful features or representations of the input data based on training data that achieves low prediction error on test data across multiple prediction tasks is considered the key to multitask learning success. In practice, however, one faces the issue of the choice of prediction tasks and the availability of test data from the chosen tasks while comparing the relative performance of different features. In this work, we develop a class of pseudometrics called Uniform Kernel Prober (UKP) for comparing features or representations learned by different statistical models such as neural networks when the downstream prediction tasks involve kernel ridge regression. The proposed pseudometric, UKP, between any two representations, provides a uniform measure of prediction error on test data corresponding to a general class of kernel ridge regression tasks for a given choice of a kernel without access to test data. Additionally, desired invariances in representations can be successfully captured by UKP only through the choice of the kernel function and the pseudometric can be efficiently estimated from $n$ input data samples with $O(\frac{1}{\sqrt{n}})$ estimation error. We also experimentally demonstrate the ability of UKP to discriminate between different types of features or representations based on their generalization performance on downstream kernel ridge regression tasks.
Gradient Flows and Riemannian Structure in the Gromov-Wasserstein Geometry
Jul 16, 2024



The Wasserstein space of probability measures is known for its intricate Riemannian structure, which underpins the Wasserstein geometry and enables gradient flow algorithms. However, the Wasserstein geometry may not be suitable for certain tasks or data modalities. Motivated by scenarios where the global structure of the data needs to be preserved, this work initiates the study of gradient flows and Riemannian structure in the Gromov-Wasserstein (GW) geometry, which is particularly suited for such purposes. We focus on the inner product GW (IGW) distance between distributions on $\mathbb{R}^d$. Given a functional $\mathsf{F}:\mathcal{P}_2(\mathbb{R}^d)\to\mathbb{R}$ to optimize, we present an implicit IGW minimizing movement scheme that generates a sequence of distributions $\{\rho_i\}_{i=0}^n$, which are close in IGW and aligned in the 2-Wasserstein sense. Taking the time step to zero, we prove that the discrete solution converges to an IGW generalized minimizing movement (GMM) $(\rho_t)_t$ that follows the continuity equation with a velocity field $v_t\in L^2(\rho_t;\mathbb{R}^d)$, specified by a global transformation of the Wasserstein gradient of $\mathsf{F}$. The transformation is given by a mobility operator that modifies the Wasserstein gradient to encode not only local information, but also global structure. Our gradient flow analysis leads us to identify the Riemannian structure that gives rise to the intrinsic IGW geometry, using which we establish a Benamou-Brenier-like formula for IGW. We conclude with a formal derivation, akin to the Otto calculus, of the IGW gradient as the inverse mobility acting on the Wasserstein gradient. Numerical experiments validating our theory and demonstrating the global nature of IGW interpolations are provided.
Nyström Kernel Stein Discrepancy
Jun 12, 2024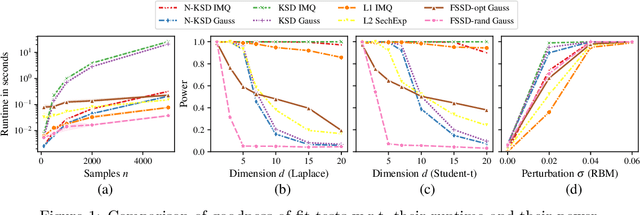
Kernel methods underpin many of the most successful approaches in data science and statistics, and they allow representing probability measures as elements of a reproducing kernel Hilbert space without loss of information. Recently, the kernel Stein discrepancy (KSD), which combines Stein's method with kernel techniques, gained considerable attention. Through the Stein operator, KSD allows the construction of powerful goodness-of-fit tests where it is sufficient to know the target distribution up to a multiplicative constant. However, the typical U- and V-statistic-based KSD estimators suffer from a quadratic runtime complexity, which hinders their application in large-scale settings. In this work, we propose a Nystr\"om-based KSD acceleration -- with runtime $\mathcal O\!\left(mn+m^3\right)$ for $n$ samples and $m\ll n$ Nystr\"om points -- , show its $\sqrt{n}$-consistency under the null with a classical sub-Gaussian assumption, and demonstrate its applicability for goodness-of-fit testing on a suite of benchmarks.
Spectral Regularized Kernel Goodness-of-Fit Tests
Aug 08, 2023



Maximum mean discrepancy (MMD) has enjoyed a lot of success in many machine learning and statistical applications, including non-parametric hypothesis testing, because of its ability to handle non-Euclidean data. Recently, it has been demonstrated in Balasubramanian et al.(2021) that the goodness-of-fit test based on MMD is not minimax optimal while a Tikhonov regularized version of it is, for an appropriate choice of the regularization parameter. However, the results in Balasubramanian et al. (2021) are obtained under the restrictive assumptions of the mean element being zero, and the uniform boundedness condition on the eigenfunctions of the integral operator. Moreover, the test proposed in Balasubramanian et al. (2021) is not practical as it is not computable for many kernels. In this paper, we address these shortcomings and extend the results to general spectral regularizers that include Tikhonov regularization.
Kernel $ε$-Greedy for Contextual Bandits
Jun 29, 2023

We consider a kernelized version of the $\epsilon$-greedy strategy for contextual bandits. More precisely, in a setting with finitely many arms, we consider that the mean reward functions lie in a reproducing kernel Hilbert space (RKHS). We propose an online weighted kernel ridge regression estimator for the reward functions. Under some conditions on the exploration probability sequence, $\{\epsilon_t\}_t$, and choice of the regularization parameter, $\{\lambda_t\}_t$, we show that the proposed estimator is consistent. We also show that for any choice of kernel and the corresponding RKHS, we achieve a sub-linear regret rate depending on the intrinsic dimensionality of the RKHS. Furthermore, we achieve the optimal regret rate of $\sqrt{T}$ under a margin condition for finite-dimensional RKHS.
Spectral Regularized Kernel Two-Sample Tests
Dec 19, 2022



Over the last decade, an approach that has gained a lot of popularity to tackle non-parametric testing problems on general (i.e., non-Euclidean) domains is based on the notion of reproducing kernel Hilbert space (RKHS) embedding of probability distributions. The main goal of our work is to understand the optimality of two-sample tests constructed based on this approach. First, we show that the popular MMD (maximum mean discrepancy) two-sample test is not optimal in terms of the separation boundary measured in Hellinger distance. Second, we propose a modification to the MMD test based on spectral regularization by taking into account the covariance information (which is not captured by the MMD test) and prove the proposed test to be minimax optimal with a smaller separation boundary than that achieved by the MMD test. Third, we propose an adaptive version of the above test which involves a data-driven strategy to choose the regularization parameter and show the adaptive test to be almost minimax optimal up to a logarithmic factor. Moreover, our results hold for the permutation variant of the test where the test threshold is chosen elegantly through the permutation of the samples. Through numerical experiments on synthetic and real-world data, we demonstrate the superior performance of the proposed test in comparison to the MMD test.
Regularized Stein Variational Gradient Flow
Nov 15, 2022


The Stein Variational Gradient Descent (SVGD) algorithm is an deterministic particle method for sampling. However, a mean-field analysis reveals that the gradient flow corresponding to the SVGD algorithm (i.e., the Stein Variational Gradient Flow) only provides a constant-order approximation to the Wasserstein Gradient Flow corresponding to the KL-divergence minimization. In this work, we propose the Regularized Stein Variational Gradient Flow which interpolates between the Stein Variational Gradient Flow and the Wasserstein Gradient Flow. We establish various theoretical properties of the Regularized Stein Variational Gradient Flow (and its time-discretization) including convergence to equilibrium, existence and uniqueness of weak solutions, and stability of the solutions. We provide preliminary numerical evidence of the improved performance offered by the regularization.
Shrinkage Estimation of Higher Order Bochner Integrals
Jul 21, 2022We consider shrinkage estimation of higher order Hilbert space valued Bochner integrals in a non-parametric setting. We propose estimators that shrink the $U$-statistic estimator of the Bochner integral towards a pre-specified target element in the Hilbert space. Depending on the degeneracy of the kernel of the $U$-statistic, we construct consistent shrinkage estimators with fast rates of convergence, and develop oracle inequalities comparing the risks of the the $U$-statistic estimator and its shrinkage version. Surprisingly, we show that the shrinkage estimator designed by assuming complete degeneracy of the kernel of the $U$-statistic is a consistent estimator even when the kernel is not complete degenerate. This work subsumes and improves upon Krikamol et al., 2016, JMLR and Zhou et al., 2019, JMVA, which only handle mean element and covariance operator estimation in a reproducing kernel Hilbert space. We also specialize our results to normal mean estimation and show that for $d\ge 3$, the proposed estimator strictly improves upon the sample mean in terms of the mean squared error.