 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Optimal Kernel Two-Sample Tests with Random Features
Feb 28, 2025Reproducing Kernel Hilbert Space (RKHS) embedding of probability distributions has proved to be an effective approach, via MMD (maximum mean discrepancy) for nonparametric hypothesis testing problems involving distributions defined over general (non-Euclidean) domains. While a substantial amount of work has been done on this topic, only recently, minimax optimal two-sample tests have been constructed that incorporate, unlike MMD, both the mean element and a regularized version of the covariance operator. However, as with most kernel algorithms, the computational complexity of the optimal test scales cubically in the sample size, limiting its applicability. In this paper, we propose a spectral regularized two-sample test based on random Fourier feature (RFF) approximation and investigate the trade-offs between statistical optimality and computational efficiency. We show the proposed test to be minimax optimal if the approximation order of RFF (which depends on the smoothness of the likelihood ratio and the decay rate of the eigenvalues of the integral operator) is sufficiently large. We develop a practically implementable permutation-based version of the proposed test with a data-adaptive strategy for selecting the regularization parameter and the kernel. Finally, through numerical experiments on simulated and benchmark datasets, we demonstrate that the proposed RFF-based test is computationally efficient and performs almost similar (with a small drop in power) to the exact test.
Uniform Kernel Prober
Feb 11, 2025

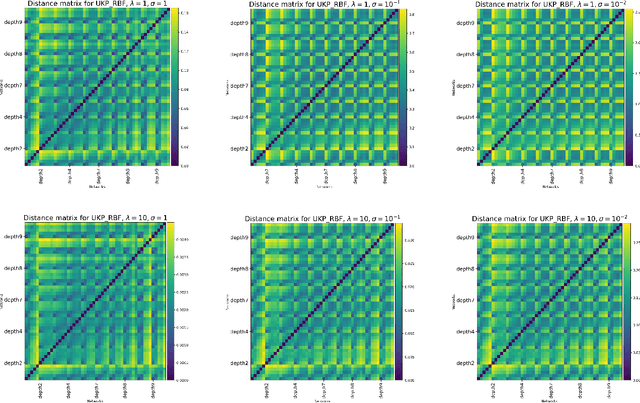
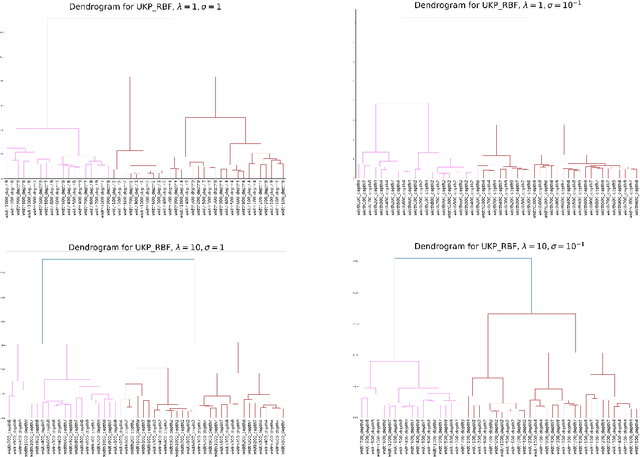
The ability to identify useful features or representations of the input data based on training data that achieves low prediction error on test data across multiple prediction tasks is considered the key to multitask learning success. In practice, however, one faces the issue of the choice of prediction tasks and the availability of test data from the chosen tasks while comparing the relative performance of different features. In this work, we develop a class of pseudometrics called Uniform Kernel Prober (UKP) for comparing features or representations learned by different statistical models such as neural networks when the downstream prediction tasks involve kernel ridge regression. The proposed pseudometric, UKP, between any two representations, provides a uniform measure of prediction error on test data corresponding to a general class of kernel ridge regression tasks for a given choice of a kernel without access to test data. Additionally, desired invariances in representations can be successfully captured by UKP only through the choice of the kernel function and the pseudometric can be efficiently estimated from $n$ input data samples with $O(\frac{1}{\sqrt{n}})$ estimation error. We also experimentally demonstrate the ability of UKP to discriminate between different types of features or representations based on their generalization performance on downstream kernel ridge regression tasks.