 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Dynamic Importance Weighting with Versatile Divergence-Minimizing Estimators
May 25, 2026Importance weighting (IW) is a golden solver for joint distribution shift, where the joint distributions differ between the training and test data. To solve this problem, IW estimates test-to-training density ratios as importance weights and reweights the training losses accordingly. Recent advances in dynamic IW (DIW) integrate weight estimation into model training, enabling scalable IW for deep models and achieving strong performance on large modern datasets. Despite its promise, DIW remains limited in two aspects. First, it incurs substantial computational overhead by solving a kernel mean matching (KMM)-induced optimization problem to convergence in every mini-batch. Second, it relies solely on KMM for weight estimation, whereas the IW literature contains diverse estimation methods based on different divergence measures. In this paper, we propose accelerated DIW (ADIW), a unified and efficient IW framework for deep learning under joint distribution shift. ADIW performs a few lightweight projected gradient descent updates that warm-start from previously updated weights, substantially improving efficiency. Moreover, ADIW generalizes DIW into a unified divergence-minimization framework that supports diverse weight-estimation methods in a plug-and-play manner, including those based on the Kullback-Leibler divergence, squared distance, and Wasserstein-1 distance. We establish convergence guarantees for ADIW under mild conditions, and empirical results demonstrate that ADIW achieves state-of-the-art IW performance while being substantially more efficient.
Flow Matching from Viewpoint of Proximal Operators
Feb 13, 2026We reformulate Optimal Transport Conditional Flow Matching (OT-CFM), a class of dynamical generative models, showing that it admits an exact proximal formulation via an extended Brenier potential, without assuming that the target distribution has a density. In particular, the mapping to recover the target point is exactly given by a proximal operator, which yields an explicit proximal expression of the vector field. We also discuss the convergence of minibatch OT-CFM to the population formulation as the batch size increases. Finally, using second epi-derivatives of convex potentials, we prove that, for manifold-supported targets, OT-CFM is terminally normally hyperbolic: after time rescaling, the dynamics contracts exponentially in directions normal to the data manifold while remaining neutral along tangential directions.
Fast Flow Matching based Conditional Independence Tests for Causal Discovery
Feb 09, 2026Constraint-based causal discovery methods require a large number of conditional independence (CI) tests, which severely limits their practical applicability due to high computational complexity. Therefore, it is crucial to design an algorithm that accelerates each individual test. To this end, we propose the Flow Matching-based Conditional Independence Test (FMCIT). The proposed test leverages the high computational efficiency of flow matching and requires the model to be trained only once throughout the entire causal discovery procedure, substantially accelerating causal discovery. According to numerical experiments, FMCIT effectively controls type-I error and maintains high testing power under the alternative hypothesis, even in the presence of high-dimensional conditioning sets. In addition, we further integrate FMCIT into a two-stage guided PC skeleton learning framework, termed GPC-FMCIT, which combines fast screening with guided, budgeted refinement using FMCIT. This design yields explicit bounds on the number of CI queries while maintaining high statistical power. Experiments on synthetic and real-world causal discovery tasks demonstrate favorable accuracy-efficiency trade-offs over existing CI testing methods and PC variants.
Omics-scale polymer computational database transferable to real-world artificial intelligence applications
Nov 07, 2025Developing large-scale foundational datasets is a critical milestone in advancing artificial intelligence (AI)-driven scientific innovation. However, unlike AI-mature fields such as natural language processing, materials science, particularly polymer research, has significantly lagged in developing extensive open datasets. This lag is primarily due to the high costs of polymer synthesis and property measurements, along with the vastness and complexity of the chemical space. This study presents PolyOmics, an omics-scale computational database generated through fully automated molecular dynamics simulation pipelines that provide diverse physical properties for over $10^5$ polymeric materials. The PolyOmics database is collaboratively developed by approximately 260 researchers from 48 institutions to bridge the gap between academia and industry. Machine learning models pretrained on PolyOmics can be efficiently fine-tuned for a wide range of real-world downstream tasks, even when only limited experimental data are available. Notably, the generalisation capability of these simulation-to-real transfer models improve significantly as the size of the PolyOmics database increases, exhibiting power-law scaling. The emergence of scaling laws supports the "more is better" principle, highlighting the significance of ultralarge-scale computational materials data for improving real-world prediction performance. This unprecedented omics-scale database reveals vast unexplored regions of polymer materials, providing a foundation for AI-driven polymer science.
Diffusion Models with Double Guidance: Generate with aggregated datasets
May 19, 2025Creating large-scale datasets for training high-performance generative models is often prohibitively expensive, especially when associated attributes or annotations must be provided. As a result, merging existing datasets has become a common strategy. However, the sets of attributes across datasets are often inconsistent, and their naive concatenation typically leads to block-wise missing conditions. This presents a significant challenge for conditional generative modeling when the multiple attributes are used jointly as conditions, thereby limiting the model's controllability and applicability. To address this issue, we propose a novel generative approach, Diffusion Model with Double Guidance, which enables precise conditional generation even when no training samples contain all conditions simultaneously. Our method maintains rigorous control over multiple conditions without requiring joint annotations. We demonstrate its effectiveness in molecular and image generation tasks, where it outperforms existing baselines both in alignment with target conditional distributions and in controllability under missing condition settings.
Simultaneous Learning of Optimal Transports for Training All-to-All Flow-Based Condition Transfer Model
Apr 04, 2025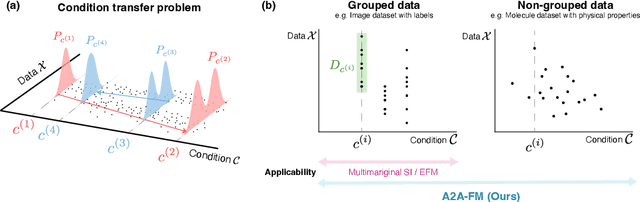

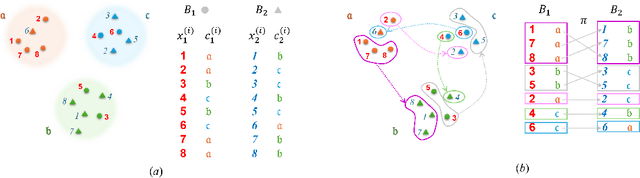

In this paper, we propose a flow-based method for learning all-to-all transfer maps among conditional distributions, approximating pairwise optimal transport. The proposed method addresses the challenge of handling continuous conditions, which often involve a large set of conditions with sparse empirical observations per condition. We introduce a novel cost function that enables simultaneous learning of optimal transports for all pairs of conditional distributions. Our method is supported by a theoretical guarantee that, in the limit, it converges to pairwise optimal transports among infinite pairs of conditional distributions. The learned transport maps are subsequently used to couple data points in conditional flow matching. We demonstrate the effectiveness of this method on synthetic and benchmark datasets, as well as on chemical datasets where continuous physical properties are defined as conditions.
Scalable Sobolev IPM for Probability Measures on a Graph
Feb 02, 2025We investigate the Sobolev IPM problem for probability measures supported on a graph metric space. Sobolev IPM is an important instance of integral probability metrics (IPM), and is obtained by constraining a critic function within a unit ball defined by the Sobolev norm. In particular, it has been used to compare probability measures and is crucial for several theoretical works in machine learning. However, to our knowledge, there are no efficient algorithmic approaches to compute Sobolev IPM effectively, which hinders its practical applications. In this work, we establish a relation between Sobolev norm and weighted $L^p$-norm, and leverage it to propose a \emph{novel regularization} for Sobolev IPM. By exploiting the graph structure, we demonstrate that the regularized Sobolev IPM provides a \emph{closed-form} expression for fast computation. This advancement addresses long-standing computational challenges, and paves the way to apply Sobolev IPM for practical applications, even in large-scale settings. Additionally, the regularized Sobolev IPM is negative definite. Utilizing this property, we design positive-definite kernels upon the regularized Sobolev IPM, and provide preliminary evidences of their advantages on document classification and topological data analysis for measures on a graph.
Orlicz-Sobolev Transport for Unbalanced Measures on a Graph
Feb 02, 2025



Moving beyond $L^p$ geometric structure, Orlicz-Wasserstein (OW) leverages a specific class of convex functions for Orlicz geometric structure. While OW remarkably helps to advance certain machine learning approaches, it has a high computational complexity due to its two-level optimization formula. Recently, Le et al. (2024) exploits graph structure to propose generalized Sobolev transport (GST), i.e., a scalable variant for OW. However, GST assumes that input measures have the same mass. Unlike optimal transport (OT), it is nontrivial to incorporate a mass constraint to extend GST for measures on a graph, possibly having different total mass. In this work, we propose to take a step back by considering the entropy partial transport (EPT) for nonnegative measures on a graph. By leveraging Caffarelli & McCann (2010)'s observations, EPT can be reformulated as a standard complete OT between two corresponding balanced measures. Consequently, we develop a novel EPT with Orlicz geometric structure, namely Orlicz-EPT, for unbalanced measures on a graph. Especially, by exploiting the dual EPT formulation and geometric structures of the graph-based Orlicz-Sobolev space, we derive a novel regularization to propose Orlicz-Sobolev transport (OST). The resulting distance can be efficiently computed by simply solving a univariate optimization problem, unlike the high-computational two-level optimization problem for Orlicz-EPT. Additionally, we derive geometric structures for the OST and draw its relations to other transport distances. We empirically show that OST is several-order faster than Orlicz-EPT. We further illustrate preliminary evidences on the advantages of OST for document classification, and several tasks in topological data analysis.
Compositional simulation-based inference for time series
Nov 05, 2024Amortized simulation-based inference (SBI) methods train neural networks on simulated data to perform Bayesian inference. While this approach avoids the need for tractable likelihoods, it often requires a large number of simulations and has been challenging to scale to time-series data. Scientific simulators frequently emulate real-world dynamics through thousands of single-state transitions over time. We propose an SBI framework that can exploit such Markovian simulators by locally identifying parameters consistent with individual state transitions. We then compose these local results to obtain a posterior over parameters that align with the entire time series observation. We focus on applying this approach to neural posterior score estimation but also show how it can be applied, e.g., to neural likelihood (ratio) estimation. We demonstrate that our approach is more simulation-efficient than directly estimating the global posterior on several synthetic benchmark tasks and simulators used in ecology and epidemiology. Finally, we validate scalability and simulation efficiency of our approach by applying it to a high-dimensional Kolmogorov flow simulator with around one million dimensions in the data domain.
Scaling Law of Sim2Real Transfer Learning in Expanding Computational Materials Databases for Real-World Predictions
Aug 07, 2024To address the challenge of limited experimental materials data, extensive physical property databases are being developed based on high-throughput computational experiments, such as molecular dynamics simulations. Previous studies have shown that fine-tuning a predictor pretrained on a computational database to a real system can result in models with outstanding generalization capabilities compared to learning from scratch. This study demonstrates the scaling law of simulation-to-real (Sim2Real) transfer learning for several machine learning tasks in materials science. Case studies of three prediction tasks for polymers and inorganic materials reveal that the prediction error on real systems decreases according to a power-law as the size of the computational data increases. Observing the scaling behavior offers various insights for database development, such as determining the sample size necessary to achieve a desired performance, identifying equivalent sample sizes for physical and computational experiments, and guiding the design of data production protocols for downstream real-world tasks.