 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Reconstruction of LiDAR Point Clouds under Jamming Attacks via Full-Waveform Representation and Simultaneous Laser Sensing
Apr 01, 2026LiDAR sensors are critical for autonomous driving perception, yet remain vulnerable to spoofing attacks. Jamming attacks inject high-frequency laser pulses that completely blind LiDAR sensors by overwhelming authentic returns with malicious signals. We discover that while point clouds become randomized, the underlying full-waveform data retains distinguishable signatures between attack and legitimate signals. In this work, we propose PULSAR-Net, capable of reconstructing authentic point clouds under jamming attacks by leveraging previously underutilized intermediate full-waveform representations and simultaneous laser sensing in modern LiDAR systems. PULSAR-Net adopts a novel U-Net architecture with axial spatial attention mechanisms specifically designed to identify attack-induced signals from authentic object returns in the full-waveform representation. To address the lack of full-waveform representations in existing LiDAR datasets under jamming attacks, we introduce a physics-aware dataset generation pipeline that synthesizes realistic full-waveform representations under jamming attacks. Despite being trained exclusively on synthetic data, PULSAR-Net achieves reconstruction rates of 92% and 73% for vehicles obscured by jamming attacks in real-world static and driving scenarios, respectively.
Omics-scale polymer computational database transferable to real-world artificial intelligence applications
Nov 07, 2025Developing large-scale foundational datasets is a critical milestone in advancing artificial intelligence (AI)-driven scientific innovation. However, unlike AI-mature fields such as natural language processing, materials science, particularly polymer research, has significantly lagged in developing extensive open datasets. This lag is primarily due to the high costs of polymer synthesis and property measurements, along with the vastness and complexity of the chemical space. This study presents PolyOmics, an omics-scale computational database generated through fully automated molecular dynamics simulation pipelines that provide diverse physical properties for over $10^5$ polymeric materials. The PolyOmics database is collaboratively developed by approximately 260 researchers from 48 institutions to bridge the gap between academia and industry. Machine learning models pretrained on PolyOmics can be efficiently fine-tuned for a wide range of real-world downstream tasks, even when only limited experimental data are available. Notably, the generalisation capability of these simulation-to-real transfer models improve significantly as the size of the PolyOmics database increases, exhibiting power-law scaling. The emergence of scaling laws supports the "more is better" principle, highlighting the significance of ultralarge-scale computational materials data for improving real-world prediction performance. This unprecedented omics-scale database reveals vast unexplored regions of polymer materials, providing a foundation for AI-driven polymer science.
Rethinking the Relationship between the Power Law and Hierarchical Structures
May 08, 2025Statistical analysis of corpora provides an approach to quantitatively investigate natural languages. This approach has revealed that several power laws consistently emerge across different corpora and languages, suggesting the universal principles underlying languages. Particularly, the power-law decay of correlation has been interpreted as evidence for underlying hierarchical structures in syntax, semantics, and discourse. This perspective has also been extended to child languages and animal signals. However, the argument supporting this interpretation has not been empirically tested. To address this problem, this study examines the validity of the argument for syntactic structures. Specifically, we test whether the statistical properties of parse trees align with the implicit assumptions in the argument. Using English corpora, we analyze the mutual information, deviations from probabilistic context-free grammars (PCFGs), and other properties in parse trees, as well as in the PCFG that approximates these trees. Our results indicate that the assumptions do not hold for syntactic structures and that it is difficult to apply the proposed argument to child languages and animal signals, highlighting the need to reconsider the relationship between the power law and hierarchical structures.
Bayesian Kernel Regression for Functional Data
Mar 17, 2025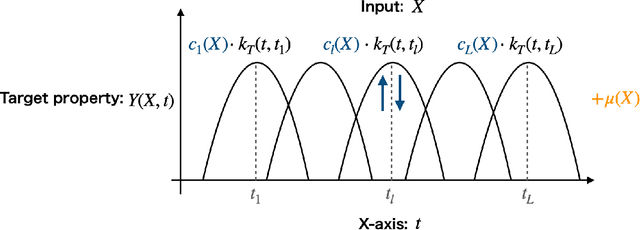



In supervised learning, the output variable to be predicted is often represented as a function, such as a spectrum or probability distribution. Despite its importance, functional output regression remains relatively unexplored. In this study, we propose a novel functional output regression model based on kernel methods. Unlike conventional approaches that independently train regressors with scalar outputs for each measurement point of the output function, our method leverages the covariance structure within the function values, akin to multitask learning, leading to enhanced learning efficiency and improved prediction accuracy. Compared with existing nonlinear function-on-scalar models in statistical functional data analysis, our model effectively handles high-dimensional nonlinearity while maintaining a simple model structure. Furthermore, the fully kernel-based formulation allows the model to be expressed within the framework of reproducing kernel Hilbert space (RKHS), providing an analytic form for parameter estimation and a solid foundation for further theoretical analysis. The proposed model delivers a functional output predictive distribution derived analytically from a Bayesian perspective, enabling the quantification of uncertainty in the predicted function. We demonstrate the model's enhanced prediction performance through experiments on artificial datasets and density of states prediction tasks in materials science.
If Attention Serves as a Cognitive Model of Human Memory Retrieval, What is the Plausible Memory Representation?
Feb 17, 2025Recent work in computational psycholinguistics has revealed intriguing parallels between attention mechanisms and human memory retrieval, focusing primarily on Transformer architectures that operate on token-level representations. However, computational psycholinguistic research has also established that syntactic structures provide compelling explanations for human sentence processing that word-level factors alone cannot fully account for. In this study, we investigate whether the attention mechanism of Transformer Grammar (TG), which uniquely operates on syntactic structures as representational units, can serve as a cognitive model of human memory retrieval, using Normalized Attention Entropy (NAE) as a linking hypothesis between model behavior and human processing difficulty. Our experiments demonstrate that TG's attention achieves superior predictive power for self-paced reading times compared to vanilla Transformer's, with further analyses revealing independent contributions from both models. These findings suggest that human sentence processing involves dual memory representations -- one based on syntactic structures and another on token sequences -- with attention serving as the general retrieval algorithm, while highlighting the importance of incorporating syntactic structures as representational units.
Developmentally-plausible Working Memory Shapes a Critical Period for Language Acquisition
Feb 07, 2025



Large language models exhibit general linguistic abilities but significantly differ from humans in their efficiency of language acquisition. This study proposes a method for integrating the developmental characteristics of working memory during the critical period, a stage when human language acquisition is particularly efficient, into language models. The proposed method introduces a mechanism that initially constrains working memory during the early stages of training and gradually relaxes this constraint in an exponential manner as learning progresses. Targeted syntactic evaluation shows that the proposed method outperforms conventional models without memory constraints or with static memory constraints. These findings not only provide new directions for designing data-efficient language models but also offer indirect evidence supporting the underlying mechanisms of the critical period hypothesis in human language acquisition.
Scaling Law of Sim2Real Transfer Learning in Expanding Computational Materials Databases for Real-World Predictions
Aug 07, 2024To address the challenge of limited experimental materials data, extensive physical property databases are being developed based on high-throughput computational experiments, such as molecular dynamics simulations. Previous studies have shown that fine-tuning a predictor pretrained on a computational database to a real system can result in models with outstanding generalization capabilities compared to learning from scratch. This study demonstrates the scaling law of simulation-to-real (Sim2Real) transfer learning for several machine learning tasks in materials science. Case studies of three prediction tasks for polymers and inorganic materials reveal that the prediction error on real systems decreases according to a power-law as the size of the computational data increases. Observing the scaling behavior offers various insights for database development, such as determining the sample size necessary to achieve a desired performance, identifying equivalent sample sizes for physical and computational experiments, and guiding the design of data production protocols for downstream real-world tasks.
Tree-Planted Transformers: Large Language Models with Implicit Syntactic Supervision
Feb 20, 2024Large Language Models (LLMs) have achieved remarkable success thanks to scalability on large text corpora, but have some drawback in training efficiency. In contrast, Syntactic Language Models (SLMs) can be trained efficiently to reach relatively high performance thanks to syntactic supervision, but have trouble with scalability. Thus, given these complementary advantages of LLMs and SLMs, it is necessary to develop an architecture that integrates the scalability of LLMs with the training efficiency of SLMs, namely Syntactic Large Language Models (SLLM). In this paper, we propose a novel method dubbed tree-planting: implicitly "plant" trees into attention weights of Transformer LMs to reflect syntactic structures of natural language. Specifically, Transformer LMs trained with tree-planting will be called Tree-Planted Transformers (TPT), which learn syntax on small treebanks via tree-planting and then scale on large text corpora via continual learning with syntactic scaffolding. Targeted syntactic evaluations on the SyntaxGym benchmark demonstrated that TPTs, despite the lack of explicit syntactic supervision, significantly outperformed various SLMs with explicit syntactic supervision that generate hundreds of syntactic structures in parallel, suggesting that tree-planting and TPTs are the promising foundation for SLLMs.
Emergent Word Order Universals from Cognitively-Motivated Language Models
Feb 19, 2024



The world's languages exhibit certain so-called typological or implicational universals; for example, Subject-Object-Verb (SOV) word order typically employs postpositions. Explaining the source of such biases is a key goal in linguistics. We study the word-order universals through a computational simulation with language models (LMs). Our experiments show that typologically typical word orders tend to have lower perplexity estimated by LMs with cognitively plausible biases: syntactic biases, specific parsing strategies, and memory limitations. This suggests that the interplay of these cognitive biases and predictability (perplexity) can explain many aspects of word-order universals. This also showcases the advantage of cognitively-motivated LMs, which are typically employed in cognitive modeling, in the computational simulation of language universals.
Shotgun crystal structure prediction using machine-learned formation energies
May 07, 2023Stable or metastable crystal structures of assembled atoms can be predicted by finding the global or local minima of the energy surface with respect to the atomic configurations. Generally, this requires repeated first-principles energy calculations that are impractical for large systems, such as those containing more than 30 atoms in the unit cell. Here, we have made significant progress in solving the crystal structure prediction problem with a simple but powerful machine-learning workflow; using a machine-learning surrogate for first-principles energy calculations, we performed non-iterative, single-shot screening using a large library of virtually created crystal structures. The present method relies on two key technical components: transfer learning, which enables a highly accurate energy prediction of pre-relaxed crystalline states given only a small set of training samples from first-principles calculations, and generative models to create promising and diverse crystal structures for screening. Here, first-principles calculations were performed only to generate the training samples, and for the optimization of a dozen or fewer finally narrowed-down crystal structures. Our shotgun method was more than 5--10 times less computationally demanding and achieved an outstanding prediction accuracy that was 2--6 times higher than that of the conventional methods that rely heavily on iterative first-principles calculations.