 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Relationship between the Power Law and Hierarchical Structures
May 08, 2025Statistical analysis of corpora provides an approach to quantitatively investigate natural languages. This approach has revealed that several power laws consistently emerge across different corpora and languages, suggesting the universal principles underlying languages. Particularly, the power-law decay of correlation has been interpreted as evidence for underlying hierarchical structures in syntax, semantics, and discourse. This perspective has also been extended to child languages and animal signals. However, the argument supporting this interpretation has not been empirically tested. To address this problem, this study examines the validity of the argument for syntactic structures. Specifically, we test whether the statistical properties of parse trees align with the implicit assumptions in the argument. Using English corpora, we analyze the mutual information, deviations from probabilistic context-free grammars (PCFGs), and other properties in parse trees, as well as in the PCFG that approximates these trees. Our results indicate that the assumptions do not hold for syntactic structures and that it is difficult to apply the proposed argument to child languages and animal signals, highlighting the need to reconsider the relationship between the power law and hierarchical structures.
Ratio Divergence Learning Using Target Energy in Restricted Boltzmann Machines: Beyond Kullback--Leibler Divergence Learning
Sep 12, 2024



We propose ratio divergence (RD) learning for discrete energy-based models, a method that utilizes both training data and a tractable target energy function. We apply RD learning to restricted Boltzmann machines (RBMs), which are a minimal model that satisfies the universal approximation theorem for discrete distributions. RD learning combines the strength of both forward and reverse Kullback-Leibler divergence (KLD) learning, effectively addressing the "notorious" issues of underfitting with the forward KLD and mode-collapse with the reverse KLD. Since the summation of forward and reverse KLD seems to be sufficient to combine the strength of both approaches, we include this learning method as a direct baseline in numerical experiments to evaluate its effectiveness. Numerical experiments demonstrate that RD learning significantly outperforms other learning methods in terms of energy function fitting, mode-covering, and learning stability across various discrete energy-based models. Moreover, the performance gaps between RD learning and the other learning methods become more pronounced as the dimensions of target models increase.
Statistical Mechanics of Min-Max Problems
Sep 09, 2024
Min-max optimization problems, also known as saddle point problems, have attracted significant attention due to their applications in various fields, such as fair beamforming, generative adversarial networks (GANs), and adversarial learning. However, understanding the properties of these min-max problems has remained a substantial challenge. This study introduces a statistical mechanical formalism for analyzing the equilibrium values of min-max problems in the high-dimensional limit, while appropriately addressing the order of operations for min and max. As a first step, we apply this formalism to bilinear min-max games and simple GANs, deriving the relationship between the amount of training data and generalization error and indicating the optimal ratio of fake to real data for effective learning. This formalism provides a groundwork for a deeper theoretical analysis of the equilibrium properties in various machine learning methods based on min-max problems and encourages the development of new algorithms and architectures.
Critical Phase Transition in a Large Language Model
Jun 08, 2024



The performance of large language models (LLMs) strongly depends on the \textit{temperature} parameter. Empirically, at very low temperatures, LLMs generate sentences with clear repetitive structures, while at very high temperatures, generated sentences are often incomprehensible. In this study, using GPT-2, we numerically demonstrate that the difference between the two regimes is not just a smooth change but a phase transition with singular, divergent statistical quantities. Our extensive analysis shows that critical behaviors, such as a power-law decay of correlation in a text, emerge in the LLM at the transition temperature as well as in a natural language dataset. We also discuss that several statistical quantities characterizing the criticality should be useful to evaluate the performance of LLMs.
Learning Dynamics in Linear VAE: Posterior Collapse Threshold, Superfluous Latent Space Pitfalls, and Speedup with KL Annealing
Oct 24, 2023


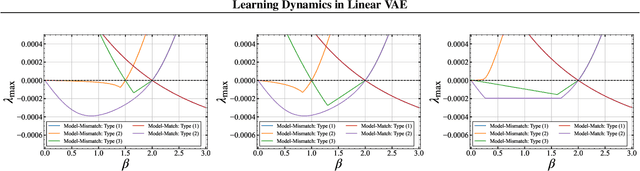
Variational autoencoders (VAEs) face a notorious problem wherein the variational posterior often aligns closely with the prior, a phenomenon known as posterior collapse, which hinders the quality of representation learning. To mitigate this problem, an adjustable hyperparameter $\beta$ and a strategy for annealing this parameter, called KL annealing, are proposed. This study presents a theoretical analysis of the learning dynamics in a minimal VAE. It is rigorously proved that the dynamics converge to a deterministic process within the limit of large input dimensions, thereby enabling a detailed dynamical analysis of the generalization error. Furthermore, the analysis shows that the VAE initially learns entangled representations and gradually acquires disentangled representations. A fixed-point analysis of the deterministic process reveals that when $\beta$ exceeds a certain threshold, posterior collapse becomes inevitable regardless of the learning period. Additionally, the superfluous latent variables for the data-generative factors lead to overfitting of the background noise; this adversely affects both generalization and learning convergence. The analysis further unveiled that appropriately tuned KL annealing can accelerate convergence.
Dataset Size Dependence of Rate-Distortion Curve and Threshold of Posterior Collapse in Linear VAE
Sep 14, 2023


In the Variational Autoencoder (VAE), the variational posterior often aligns closely with the prior, which is known as posterior collapse and hinders the quality of representation learning. To mitigate this problem, an adjustable hyperparameter beta has been introduced in the VAE. This paper presents a closed-form expression to assess the relationship between the beta in VAE, the dataset size, the posterior collapse, and the rate-distortion curve by analyzing a minimal VAE in a high-dimensional limit. These results clarify that a long plateau in the generalization error emerges with a relatively larger beta. As the beta increases, the length of the plateau extends and then becomes infinite beyond a certain beta threshold. This implies that the choice of beta, unlike the usual regularization parameters, can induce posterior collapse regardless of the dataset size. Thus, beta is a risky parameter that requires careful tuning. Furthermore, considering the dataset-size dependence on the rate-distortion curve, a relatively large dataset is required to obtain a rate-distortion curve with high rates. Extensive numerical experiments support our analysis.
Data-driven determination of the spin Hamiltonian parameters and their uncertainties: The case of the zigzag-chain compound KCu$_4$P$_3$O$_{12}$
Jun 13, 2020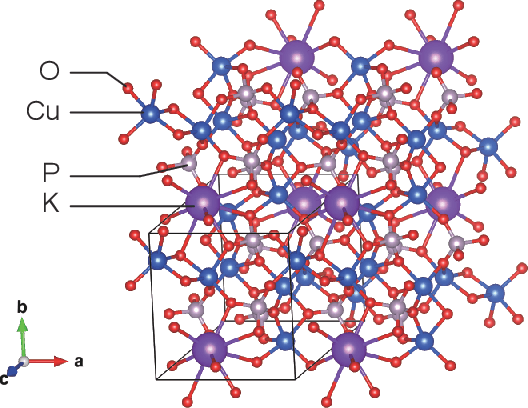
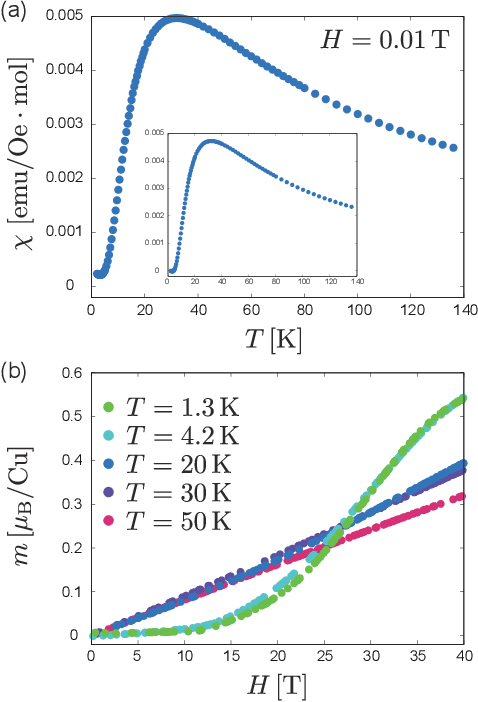
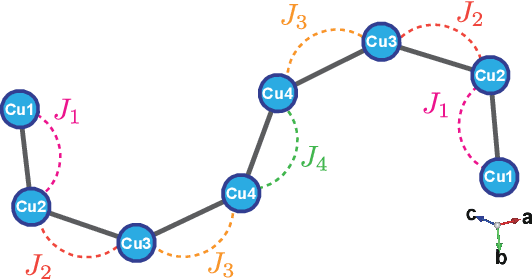
We propose a data-driven technique to estimate the spin Hamiltonian, including uncertainty, from multiple physical quantities. Using our technique, an effective model of KCu$_4$P$_3$O$_{12}$ is determined from the experimentally observed magnetic susceptibility and magnetization curves with various temperatures under high magnetic fields. An effective model, which is the quantum Heisenberg model on a zigzag chain with eight spins having $J_1= -8.54 \pm 0.51 \{\rm meV}$, $J_2 = -2.67 \pm 1.13 \{\rm meV}$, $J_3 = -3.90 \pm 0.15 \{\rm meV}$, and $J_4 = 6.24 \pm 0.95 \{\rm meV}$, describes these measured results well. These uncertainties are successfully determined by the noise estimation. The relations among the estimated magnetic interactions or physical quantities are also discussed. The obtained effective model is useful to predict hard-to-measure properties such as spin gap, spin configuration at the ground state, magnetic specific heat, and magnetic entropy.
On-line Learning of an Unlearnable True Teacher through Mobile Ensemble Teachers
May 10, 2008



On-line learning of a hierarchical learning model is studied by a method from statistical mechanics. In our model a student of a simple perceptron learns from not a true teacher directly, but ensemble teachers who learn from the true teacher with a perceptron learning rule. Since the true teacher and the ensemble teachers are expressed as non-monotonic perceptron and simple ones, respectively, the ensemble teachers go around the unlearnable true teacher with the distance between them fixed in an asymptotic steady state. The generalization performance of the student is shown to exceed that of the ensemble teachers in a transient state, as was shown in similar ensemble-teachers models. Further, it is found that moving the ensemble teachers even in the steady state, in contrast to the fixed ensemble teachers, is efficient for the performance of the student.