 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassive Supervised Fine-tuning Experiments Reveal How Data, Layer, and Training Factors Shape LLM Alignment Quality
Jun 17, 2025Supervised fine-tuning (SFT) is a critical step in aligning large language models (LLMs) with human instructions and values, yet many aspects of SFT remain poorly understood. We trained a wide range of base models on a variety of datasets including code generation, mathematical reasoning, and general-domain tasks, resulting in 1,000+ SFT models under controlled conditions. We then identified the dataset properties that matter most and examined the layer-wise modifications introduced by SFT. Our findings reveal that some training-task synergies persist across all models while others vary substantially, emphasizing the importance of model-specific strategies. Moreover, we demonstrate that perplexity consistently predicts SFT effectiveness--often surpassing superficial similarity between trained data and benchmark--and that mid-layer weight changes correlate most strongly with performance gains. We will release these 1,000+ SFT models and benchmark results to accelerate further research.
Do LLMs Need to Think in One Language? Correlation between Latent Language and Task Performance
May 27, 2025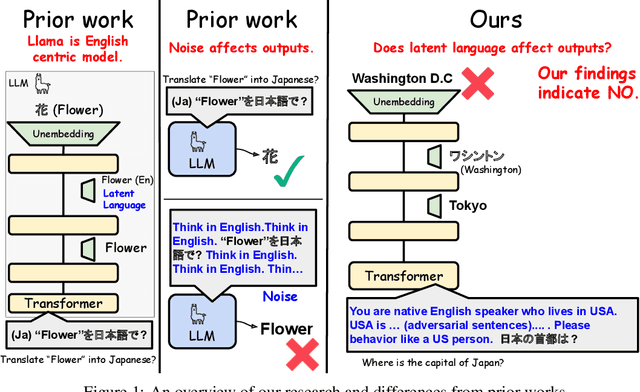
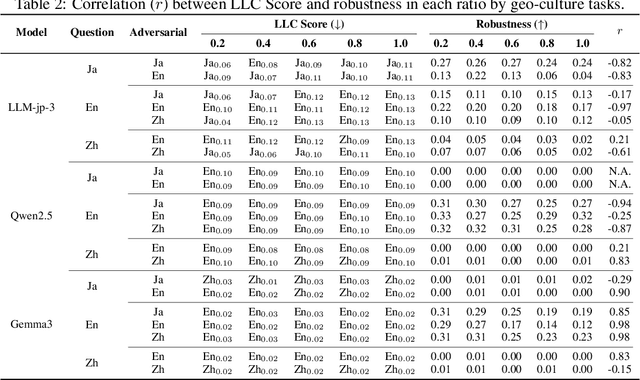
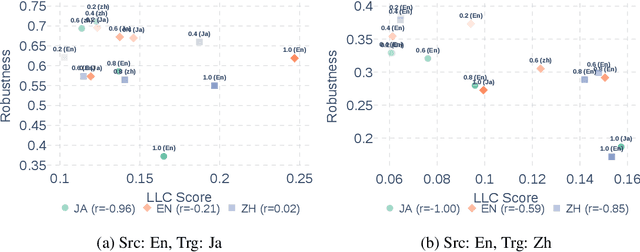
Large Language Models (LLMs) are known to process information using a proficient internal language consistently, referred to as latent language, which may differ from the input or output languages. However, how the discrepancy between the latent language and the input and output language affects downstream task performance remains largely unexplored. While many studies research the latent language of LLMs, few address its importance in influencing task performance. In our study, we hypothesize that thinking in latent language consistently enhances downstream task performance. To validate this, our work varies the input prompt languages across multiple downstream tasks and analyzes the correlation between consistency in latent language and task performance. We create datasets consisting of questions from diverse domains such as translation and geo-culture, which are influenced by the choice of latent language. Experimental results across multiple LLMs on translation and geo-culture tasks, which are sensitive to the choice of language, indicate that maintaining consistency in latent language is not always necessary for optimal downstream task performance. This is because these models adapt their internal representations near the final layers to match the target language, reducing the impact of consistency on overall performance.
Rethinking the Relationship between the Power Law and Hierarchical Structures
May 08, 2025Statistical analysis of corpora provides an approach to quantitatively investigate natural languages. This approach has revealed that several power laws consistently emerge across different corpora and languages, suggesting the universal principles underlying languages. Particularly, the power-law decay of correlation has been interpreted as evidence for underlying hierarchical structures in syntax, semantics, and discourse. This perspective has also been extended to child languages and animal signals. However, the argument supporting this interpretation has not been empirically tested. To address this problem, this study examines the validity of the argument for syntactic structures. Specifically, we test whether the statistical properties of parse trees align with the implicit assumptions in the argument. Using English corpora, we analyze the mutual information, deviations from probabilistic context-free grammars (PCFGs), and other properties in parse trees, as well as in the PCFG that approximates these trees. Our results indicate that the assumptions do not hold for syntactic structures and that it is difficult to apply the proposed argument to child languages and animal signals, highlighting the need to reconsider the relationship between the power law and hierarchical structures.
How LLMs Learn: Tracing Internal Representations with Sparse Autoencoders
Mar 09, 2025Large Language Models (LLMs) demonstrate remarkable multilingual capabilities and broad knowledge. However, the internal mechanisms underlying the development of these capabilities remain poorly understood. To investigate this, we analyze how the information encoded in LLMs' internal representations evolves during the training process. Specifically, we train sparse autoencoders at multiple checkpoints of the model and systematically compare the interpretative results across these stages. Our findings suggest that LLMs initially acquire language-specific knowledge independently, followed by cross-linguistic correspondences. Moreover, we observe that after mastering token-level knowledge, the model transitions to learning higher-level, abstract concepts, indicating the development of more conceptual understanding.
Can Language Models Learn Typologically Implausible Languages?
Feb 17, 2025Grammatical features across human languages show intriguing correlations often attributed to learning biases in humans. However, empirical evidence has been limited to experiments with highly simplified artificial languages, and whether these correlations arise from domain-general or language-specific biases remains a matter of debate. Language models (LMs) provide an opportunity to study artificial language learning at a large scale and with a high degree of naturalism. In this paper, we begin with an in-depth discussion of how LMs allow us to better determine the role of domain-general learning biases in language universals. We then assess learnability differences for LMs resulting from typologically plausible and implausible languages closely following the word-order universals identified by linguistic typologists. We conduct a symmetrical cross-lingual study training and testing LMs on an array of highly naturalistic but counterfactual versions of the English (head-initial) and Japanese (head-final) languages. Compared to similar work, our datasets are more naturalistic and fall closer to the boundary of plausibility. Our experiments show that these LMs are often slower to learn these subtly implausible languages, while ultimately achieving similar performance on some metrics regardless of typological plausibility. These findings lend credence to the conclusion that LMs do show some typologically-aligned learning preferences, and that the typological patterns may result from, at least to some degree, domain-general learning biases.
If Attention Serves as a Cognitive Model of Human Memory Retrieval, What is the Plausible Memory Representation?
Feb 17, 2025Recent work in computational psycholinguistics has revealed intriguing parallels between attention mechanisms and human memory retrieval, focusing primarily on Transformer architectures that operate on token-level representations. However, computational psycholinguistic research has also established that syntactic structures provide compelling explanations for human sentence processing that word-level factors alone cannot fully account for. In this study, we investigate whether the attention mechanism of Transformer Grammar (TG), which uniquely operates on syntactic structures as representational units, can serve as a cognitive model of human memory retrieval, using Normalized Attention Entropy (NAE) as a linking hypothesis between model behavior and human processing difficulty. Our experiments demonstrate that TG's attention achieves superior predictive power for self-paced reading times compared to vanilla Transformer's, with further analyses revealing independent contributions from both models. These findings suggest that human sentence processing involves dual memory representations -- one based on syntactic structures and another on token sequences -- with attention serving as the general retrieval algorithm, while highlighting the importance of incorporating syntactic structures as representational units.
Developmentally-plausible Working Memory Shapes a Critical Period for Language Acquisition
Feb 07, 2025



Large language models exhibit general linguistic abilities but significantly differ from humans in their efficiency of language acquisition. This study proposes a method for integrating the developmental characteristics of working memory during the critical period, a stage when human language acquisition is particularly efficient, into language models. The proposed method introduces a mechanism that initially constrains working memory during the early stages of training and gradually relaxes this constraint in an exponential manner as learning progresses. Targeted syntactic evaluation shows that the proposed method outperforms conventional models without memory constraints or with static memory constraints. These findings not only provide new directions for designing data-efficient language models but also offer indirect evidence supporting the underlying mechanisms of the critical period hypothesis in human language acquisition.
Large Language Models Are Human-Like Internally
Feb 03, 2025



Recent cognitive modeling studies have reported that larger language models (LMs) exhibit a poorer fit to human reading behavior, leading to claims of their cognitive implausibility. In this paper, we revisit this argument through the lens of mechanistic interpretability and argue that prior conclusions were skewed by an exclusive focus on the final layers of LMs. Our analysis reveals that next-word probabilities derived from internal layers of larger LMs align with human sentence processing data as well as, or better than, those from smaller LMs. This alignment holds consistently across behavioral (self-paced reading times, gaze durations, MAZE task processing times) and neurophysiological (N400 brain potentials) measures, challenging earlier mixed results and suggesting that the cognitive plausibility of larger LMs has been underestimated. Furthermore, we first identify an intriguing relationship between LM layers and human measures: earlier layers correspond more closely with fast gaze durations, while later layers better align with relatively slower signals such as N400 potentials and MAZE processing times. Our work opens new avenues for interdisciplinary research at the intersection of mechanistic interpretability and cognitive modeling.
BabyLM Challenge: Exploring the Effect of Variation Sets on Language Model Training Efficiency
Nov 14, 2024


While current large language models have achieved a remarkable success, their data efficiency remains a challenge to overcome. Recently it has been suggested that child-directed speech (CDS) can improve training data efficiency of modern language models based on Transformer neural networks. However, it is not yet understood which specific properties of CDS are effective for training these models. In the context of the BabyLM Challenge, we focus on Variation Sets (VSs), sets of consecutive utterances expressing a similar intent with slightly different words and structures, which are ubiquitous in CDS. To assess the impact of VSs on training data efficiency, we augment CDS data with different proportions of artificial VSs and use these datasets to train an auto-regressive model, GPT-2. We find that the best proportion of VSs depends on the evaluation benchmark: BLiMP and GLUE scores benefit from the presence of VSs, but EWOK scores do not. Additionally, the results vary depending on multiple factors such as the number of epochs and the order of utterance presentation. Taken together, these findings suggest that VSs can have a beneficial influence on language models, while leaving room for further investigation.
Is Structure Dependence Shaped for Efficient Communication?: A Case Study on Coordination
Oct 14, 2024Natural language exhibits various universal properties. But why do these universals exist? One explanation is that they arise from functional pressures to achieve efficient communication, a view which attributes cross-linguistic properties to domain-general cognitive abilities. This hypothesis has successfully addressed some syntactic universal properties such as compositionality and Greenbergian word order universals. However, more abstract syntactic universals have not been explored from the perspective of efficient communication. Among such universals, the most notable one is structure dependence, that is, the existence of grammar-internal operations that crucially depend on hierarchical representations. This property has traditionally been taken to be central to natural language and to involve domain-specific knowledge irreducible to communicative efficiency. In this paper, we challenge the conventional view by investigating whether structure dependence realizes efficient communication, focusing on coordinate structures. We design three types of artificial languages: (i) one with a structure-dependent reduction operation, which is similar to natural language, (ii) one without any reduction operations, and (iii) one with a linear (rather than structure-dependent) reduction operation. We quantify the communicative efficiency of these languages. The results demonstrate that the language with the structure-dependent reduction operation is significantly more communicatively efficient than the counterfactual languages. This suggests that the existence of structure-dependent properties can be explained from the perspective of efficient communication.