 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyLM Challenge: Exploring the Effect of Variation Sets on Language Model Training Efficiency
Nov 14, 2024
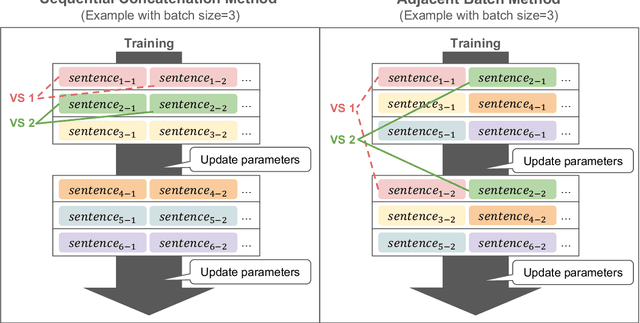


While current large language models have achieved a remarkable success, their data efficiency remains a challenge to overcome. Recently it has been suggested that child-directed speech (CDS) can improve training data efficiency of modern language models based on Transformer neural networks. However, it is not yet understood which specific properties of CDS are effective for training these models. In the context of the BabyLM Challenge, we focus on Variation Sets (VSs), sets of consecutive utterances expressing a similar intent with slightly different words and structures, which are ubiquitous in CDS. To assess the impact of VSs on training data efficiency, we augment CDS data with different proportions of artificial VSs and use these datasets to train an auto-regressive model, GPT-2. We find that the best proportion of VSs depends on the evaluation benchmark: BLiMP and GLUE scores benefit from the presence of VSs, but EWOK scores do not. Additionally, the results vary depending on multiple factors such as the number of epochs and the order of utterance presentation. Taken together, these findings suggest that VSs can have a beneficial influence on language models, while leaving room for further investigation.
Can Language Models Induce Grammatical Knowledge from Indirect Evidence?
Oct 08, 2024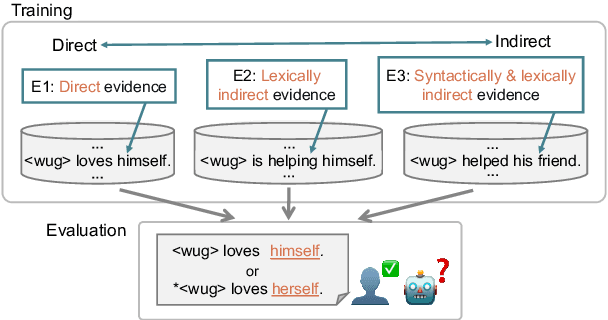
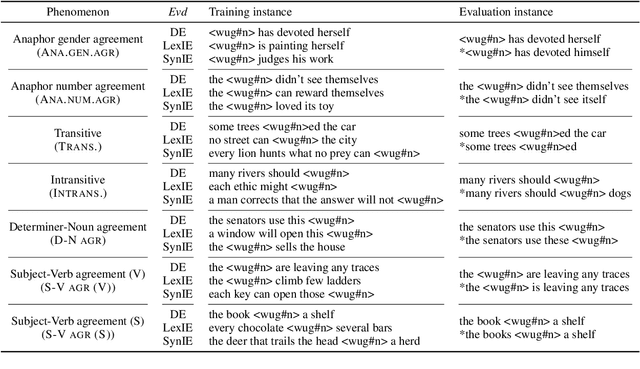

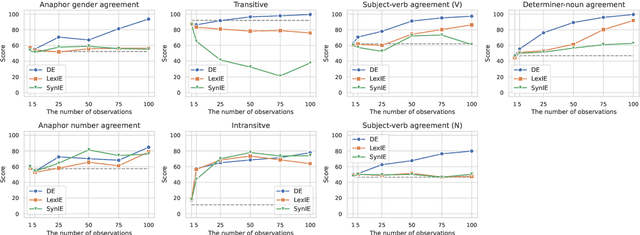
What kinds of and how much data is necessary for language models to induce grammatical knowledge to judge sentence acceptability? Recent language models still have much room for improvement in their data efficiency compared to humans. This paper investigates whether language models efficiently use indirect data (indirect evidence), from which they infer sentence acceptability. In contrast, humans use indirect evidence efficiently, which is considered one of the inductive biases contributing to efficient language acquisition. To explore this question, we introduce the Wug InDirect Evidence Test (WIDET), a dataset consisting of training instances inserted into the pre-training data and evaluation instances. We inject synthetic instances with newly coined wug words into pretraining data and explore the model's behavior on evaluation data that assesses grammatical acceptability regarding those words. We prepare the injected instances by varying their levels of indirectness and quantity. Our experiments surprisingly show that language models do not induce grammatical knowledge even after repeated exposure to instances with the same structure but differing only in lexical items from evaluation instances in certain language phenomena. Our findings suggest a potential direction for future research: developing models that use latent indirect evidence to induce grammatical knowledge.