 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Human-AI-Interaction Trust for Mental Health Support: Survey and Position for Multi-Stakeholders
Apr 22, 2026Building trustworthy AI systems for mental health support is a shared priority across stakeholders from multiple disciplines. However, "trustworthy" remains loosely defined and inconsistently operationalized. AI research often focuses on technical criteria (e.g., robustness, explainability, and safety), while therapeutic practitioners emphasize therapeutic fidelity (e.g., appropriateness, empathy, and long-term user outcomes). To bridge the fragmented landscape, we propose a three-layer trust framework, covering human-oriented, AI-oriented, and interaction-oriented trust, integrating the viewpoints of key stakeholders (e.g., practitioners, researchers, regulators). Using this framework, we systematically review existing AI-driven research in mental health domain and examine evaluation practices for ``trustworthy'' ranging from automatic metrics to clinically validated approaches. We highlight critical gaps between what NLP currently measures and what real-world mental health contexts require, and outline a research agenda for building socio-technically aligned and genuinely trustworthy AI for mental health support.
C2: Scalable Rubric-Augmented Reward Modeling from Binary Preferences
Apr 15, 2026Rubric-augmented verification guides reward models with explicit evaluation criteria, yielding more reliable judgments than single-model verification. However, most existing methods require costly rubric annotations, limiting scalability. Moreover, we find that rubric generation is vulnerable to a failure of cooperation; low-quality rubrics actively mislead reward models rather than help. Inspired by the principle of cooperative communication, we propose Cooperative yet Critical reward modeling (C2), a framework that significantly improves reward model judgments by having the reward model critically collaborate with a rubric generator trained solely from binary preferences. In C2, we synthesize helpful and misleading rubric pairs by measuring how each rubric shifts the reward model toward or away from the correct preference. Using these contrastive pairs, we train a cooperative rubric generator to propose helpful rubrics, and a critical verifier to assess rubric validity before making its judgment, following only rubrics it deems helpful at inference time. C2 outperforms reasoning reward models trained on the same binary preferences, with gains of up to 6.5 points on RM-Bench and 6.0 points length-controlled win rate on AlpacaEval 2.0. Without external rubric annotations, C2 enables an 8B reward model to match performance achieved with rubrics from a 4$\times$ larger model. Overall, our work demonstrates that eliciting deliberate cooperation in rubric-augmented verification makes reward models more trustworthy in a scalable way.
Label Effects: Shared Heuristic Reliance in Trust Assessment by Humans and LLM-as-a-Judge
Apr 07, 2026Large language models (LLMs) are increasingly used as automated evaluators (LLM-as-a-Judge). This work challenges its reliability by showing that trust judgments by LLMs are biased by disclosed source labels. Using a counterfactual design, we find that both humans and LLM judges assign higher trust to information labeled as human-authored than to the same content labeled as AI-generated. Eye-tracking data reveal that humans rely heavily on source labels as heuristic cues for judgments. We analyze LLM internal states during judgment. Across label conditions, models allocate denser attention to the label region than the content region, and this label dominance is stronger under Human labels than AI labels, consistent with the human gaze patterns. Besides, decision uncertainty measured by logits is higher under AI labels than Human labels. These results indicate that the source label is a salient heuristic cue for both humans and LLMs. It raises validity concerns for label-sensitive LLM-as-a-Judge evaluation, and we cautiously raise that aligning models with human preferences may propagate human heuristic reliance into models, motivating debiased evaluation and alignment.
CxMP: A Linguistic Minimal-Pair Benchmark for Evaluating Constructional Understanding in Language Models
Feb 25, 2026Recent work has examined language models from a linguistic perspective to better understand how they acquire language. Most existing benchmarks focus on judging grammatical acceptability, whereas the ability to interpret meanings conveyed by grammatical forms has received much less attention. We introduce the Linguistic Minimal-Pair Benchmark for Evaluating Constructional Understanding in Language Models (CxMP), a benchmark grounded in Construction Grammar that treats form-meaning pairings, or constructions, as fundamental linguistic units. CxMP evaluates whether models can interpret the semantic relations implied by constructions, using a controlled minimal-pair design across nine construction types, including the let-alone, caused motion, and ditransitive constructions. Our results show that while syntactic competence emerges early, constructional understanding develops more gradually and remains limited even in large language models (LLMs). CxMP thus reveals persistent gaps in how language models integrate form and meaning, providing a framework for studying constructional understanding and learning trajectories in language models.
Which Feedback Works for Whom? Differential Effects of LLM-Generated Feedback Elements Across Learner Profiles
Feb 12, 2026Large language models (LLMs) show promise for automatically generating feedback in education settings. However, it remains unclear how specific feedback elements, such as tone and information coverage, contribute to learning outcomes and learner acceptance, particularly across learners with different personality traits. In this study, we define six feedback elements and generate feedback for multiple-choice biology questions using GPT-5. We conduct a learning experiment with 321 first-year high school students and evaluate feedback effectiveness using two learning outcomes measures and subjective evaluations across six criteria. We further analyze differences in how feedback acceptance varies across learners based on Big Five personality traits. Our results show that effective feedback elements share common patterns supporting learning outcomes, while learners' subjective preferences differ across personality-based clusters. These findings highlight the importance of selecting and adapting feedback elements according to learners' personality traits when we design LLM-generated feedback, and provide practical implications for personalized feedback design in education.
Are Checklists Really Useful for Automatic Evaluation of Generative Tasks?
Aug 21, 2025Automatic evaluation of generative tasks using large language models faces challenges due to ambiguous criteria. Although automatic checklist generation is a potentially promising approach, its usefulness remains underexplored. We investigate whether checklists should be used for all questions or selectively, generate them using six methods, evaluate their effectiveness across eight model sizes, and identify checklist items that correlate with human evaluations. Through experiments on pairwise comparison and direct scoring tasks, we find that selective checklist use tends to improve evaluation performance in pairwise settings, while its benefits are less consistent in direct scoring. Our analysis also shows that even checklist items with low correlation to human scores often reflect human-written criteria, indicating potential inconsistencies in human evaluation. These findings highlight the need to more clearly define objective evaluation criteria to guide both human and automatic evaluations. \footnote{Our code is available at~https://github.com/momo0817/checklist-effectiveness-study
Automatic Feedback Generation for Short Answer Questions using Answer Diagnostic Graphs
Jan 27, 2025
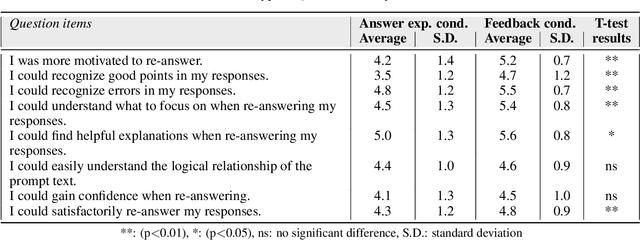
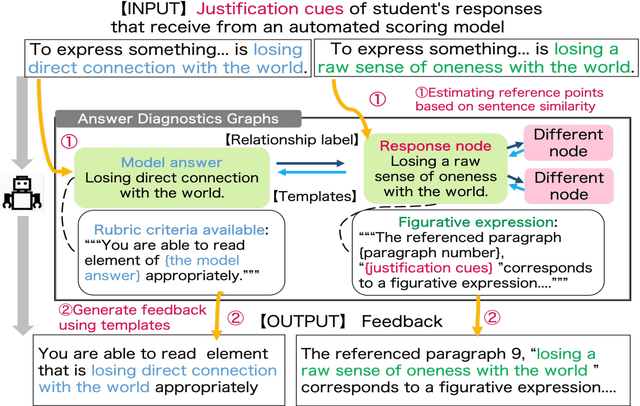
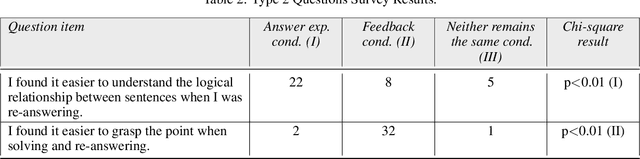
Short-reading comprehension questions help students understand text structure but lack effective feedback. Students struggle to identify and correct errors, while manual feedback creation is labor-intensive. This highlights the need for automated feedback linking responses to a scoring rubric for deeper comprehension. Despite advances in Natural Language Processing (NLP), research has focused on automatic grading, with limited work on feedback generation. To address this, we propose a system that generates feedback for student responses. Our contributions are twofold. First, we introduce the first system for feedback on short-answer reading comprehension. These answers are derived from the text, requiring structural understanding. We propose an "answer diagnosis graph," integrating the text's logical structure with feedback templates. Using this graph and NLP techniques, we estimate students' comprehension and generate targeted feedback. Second, we evaluate our feedback through an experiment with Japanese high school students (n=39). They answered two 70-80 word questions and were divided into two groups with minimal academic differences. One received a model answer, the other system-generated feedback. Both re-answered the questions, and we compared score changes. A questionnaire assessed perceptions and motivation. Results showed no significant score improvement between groups, but system-generated feedback helped students identify errors and key points in the text. It also significantly increased motivation. However, further refinement is needed to enhance text structure understanding.
Can Language Models Induce Grammatical Knowledge from Indirect Evidence?
Oct 08, 2024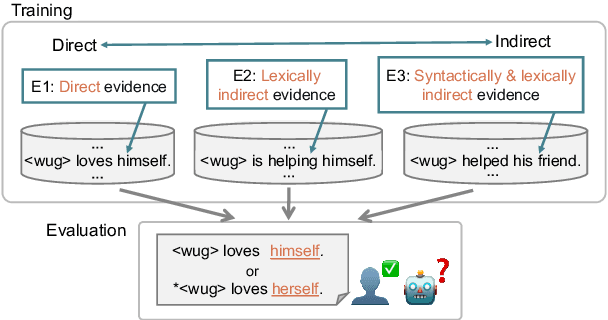
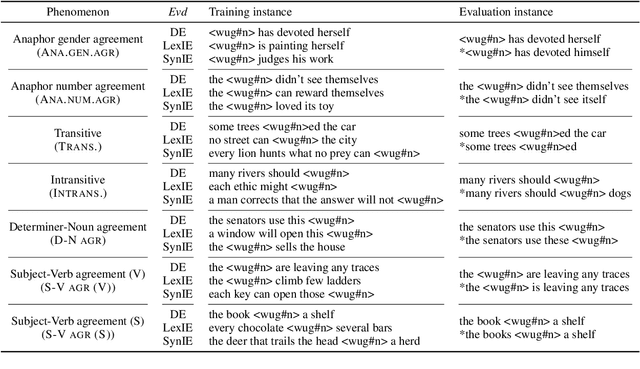

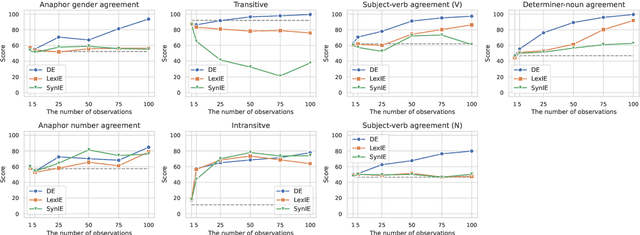
What kinds of and how much data is necessary for language models to induce grammatical knowledge to judge sentence acceptability? Recent language models still have much room for improvement in their data efficiency compared to humans. This paper investigates whether language models efficiently use indirect data (indirect evidence), from which they infer sentence acceptability. In contrast, humans use indirect evidence efficiently, which is considered one of the inductive biases contributing to efficient language acquisition. To explore this question, we introduce the Wug InDirect Evidence Test (WIDET), a dataset consisting of training instances inserted into the pre-training data and evaluation instances. We inject synthetic instances with newly coined wug words into pretraining data and explore the model's behavior on evaluation data that assesses grammatical acceptability regarding those words. We prepare the injected instances by varying their levels of indirectness and quantity. Our experiments surprisingly show that language models do not induce grammatical knowledge even after repeated exposure to instances with the same structure but differing only in lexical items from evaluation instances in certain language phenomena. Our findings suggest a potential direction for future research: developing models that use latent indirect evidence to induce grammatical knowledge.
Rationale-Aware Answer Verification by Pairwise Self-Evaluation
Oct 07, 2024Answer verification identifies correct solutions among candidates generated by large language models (LLMs). Current approaches typically train verifier models by labeling solutions as correct or incorrect based solely on whether the final answer matches the gold answer. However, this approach neglects any flawed rationale in the solution yielding the correct answer, undermining the verifier's ability to distinguish between sound and flawed rationales. We empirically show that in StrategyQA, only 19% of LLM-generated solutions with correct answers have valid rationales, thus leading to an unreliable verifier. Furthermore, we demonstrate that training a verifier on valid rationales significantly improves its ability to distinguish valid and flawed rationale. To make a better verifier without extra human supervision, we introduce REPS (Rationale Enhancement through Pairwise Selection), a method for selecting valid rationales from candidates by iteratively applying pairwise self-evaluation using the same LLM that generates the solutions. Verifiers trained on solutions selected by REPS outperform those trained using conventional training methods on three reasoning benchmarks (ARC-Challenge, DROP, and StrategyQA). Our results suggest that training reliable verifiers requires ensuring the validity of rationales in addition to the correctness of the final answers, which would be critical for models assisting humans in solving complex reasoning tasks.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.