 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoded but Not Routed: Explaining the Table-Chart Gap in Scientific Claim Verification
Jun 01, 2026Multimodal LLMs are increasingly used to assist scientific peer review, where a core requirement is verifying whether claims in a paper are supported by its evidence. Prior work has shown that models perform substantially better at this task when the evidence is a table than when it is a chart of the same underlying data. This raises the question of whether models fail to extract information from charts, or do they extract it but fail to use it when forming their prediction? We study this question through layer-wise linear probing and attention analysis on three open-weight VLMs over table and chart evidence, representing the same underlying data. We find consistent evidence for the latter. Chart information is encoded in the models' intermediate representations but does not reach the prediction position, a gap that is absent for tables and holds across all conditions tested. Attention analysis further reveals that this disconnect takes two architecturally distinct forms across model families. These findings reframe the table-chart gap as a failure of how encoded visual information is routed at prediction time, rather than a failure of encoding itself.
EarlySciRev: A Dataset of Early-Stage Scientific Revisions Extracted from LaTeX Writing Traces
Mar 30, 2026Scientific writing is an iterative process that generates rich revision traces, yet publicly available resources typically expose only final or near-final versions of papers. This limits empirical study of revision behaviour and evaluation of large language models (LLMs) for scientific writing. We introduce EarlySciRev, a dataset of early-stage scientific text revisions automatically extracted from arXiv LaTeX source files. Our key observation is that commented-out text in LaTeX often preserves discarded or alternative formulations written by the authors themselves. By aligning commented segments with nearby final text, we extract paragraph-level candidate revision pairs and apply LLM-based filtering to retain genuine revisions. Starting from 1.28M candidate pairs, our pipeline yields 578k validated revision pairs, grounded in authentic early drafting traces. We additionally provide a human-annotated benchmark for revision detection. EarlySciRev complements existing resources focused on late-stage revisions or synthetic rewrites and supports research on scientific writing dynamics, revision modelling, and LLM-assisted editing.
Evaluating the Homogeneity of Keyphrase Prediction Models
Feb 13, 2026Keyphrases which are useful in several NLP and IR applications are either extracted from text or predicted by generative models. Contrarily to keyphrase extraction approaches, keyphrase generation models can predict keyphrases that do not appear in a document's text called `absent keyphrases`. This ability means that keyphrase generation models can associate a document to a notion that is not explicitly mentioned in its text. Intuitively, this suggests that for two documents treating the same subjects, a keyphrase generation model is more likely to be homogeneous in their indexing i.e. predict the same keyphrase for both documents, regardless of those keyphrases appearing in their respective text or not; something a keyphrase extraction model would fail to do. Yet, homogeneity of keyphrase prediction models is not covered by current benchmarks. In this work, we introduce a method to evaluate the homogeneity of keyphrase prediction models and study if absent keyphrase generation capabilities actually help the model to be more homogeneous. To our surprise, we show that keyphrase extraction methods are competitive with generative models, and that the ability to generate absent keyphrases can actually have a negative impact on homogeneity. Our data, code and prompts are available on huggingface and github.
SciClaimEval: Cross-modal Claim Verification in Scientific Papers
Feb 07, 2026We present SciClaimEval, a new scientific dataset for the claim verification task. Unlike existing resources, SciClaimEval features authentic claims, including refuted ones, directly extracted from published papers. To create refuted claims, we introduce a novel approach that modifies the supporting evidence (figures and tables), rather than altering the claims or relying on large language models (LLMs) to fabricate contradictions. The dataset provides cross-modal evidence with diverse representations: figures are available as images, while tables are provided in multiple formats, including images, LaTeX source, HTML, and JSON. SciClaimEval contains 1,664 annotated samples from 180 papers across three domains, machine learning, natural language processing, and medicine, validated through expert annotation. We benchmark 11 multimodal foundation models, both open-source and proprietary, across the dataset. Results show that figure-based verification remains particularly challenging for all models, as a substantial performance gap remains between the best system and human baseline.
FC-CONAN: An Exhaustively Paired Dataset for Robust Evaluation of Retrieval Systems
Jan 04, 2026Hate speech (HS) is a critical issue in online discourse, and one promising strategy to counter it is through the use of counter-narratives (CNs). Datasets linking HS with CNs are essential for advancing counterspeech research. However, even flagship resources like CONAN (Chung et al., 2019) annotate only a sparse subset of all possible HS-CN pairs, limiting evaluation. We introduce FC-CONAN (Fully Connected CONAN), the first dataset created by exhaustively considering all combinations of 45 English HS messages and 129 CNs. A two-stage annotation process involving nine annotators and four validators produces four partitions-Diamond, Gold, Silver, and Bronze-that balance reliability and scale. None of the labeled pairs overlap with CONAN, uncovering hundreds of previously unlabelled positives. FC-CONAN enables more faithful evaluation of counterspeech retrieval systems and facilitates detailed error analysis. The dataset is publicly available.
Format Matters: The Robustness of Multimodal LLMs in Reviewing Evidence from Tables and Charts
Nov 13, 2025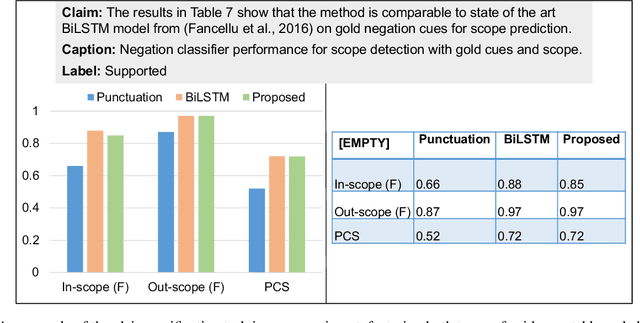
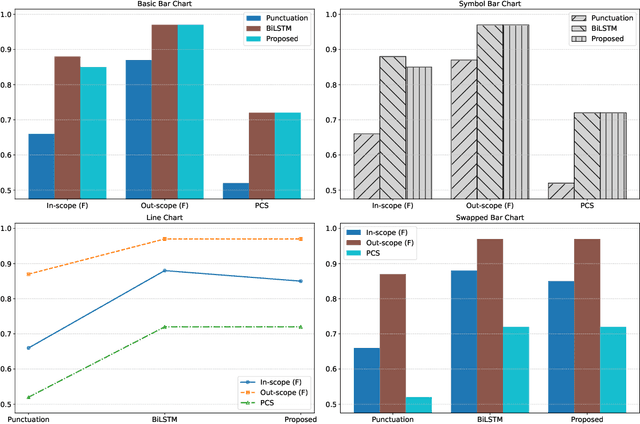
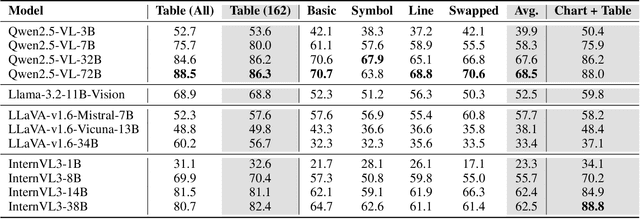
With the growing number of submitted scientific papers, there is an increasing demand for systems that can assist reviewers in evaluating research claims. Experimental results are a core component of scientific work, often presented in varying formats such as tables or charts. Understanding how robust current multimodal large language models (multimodal LLMs) are at verifying scientific claims across different evidence formats remains an important and underexplored challenge. In this paper, we design and conduct a series of experiments to assess the ability of multimodal LLMs to verify scientific claims using both tables and charts as evidence. To enable this evaluation, we adapt two existing datasets of scientific papers by incorporating annotations and structures necessary for a multimodal claim verification task. Using this adapted dataset, we evaluate 12 multimodal LLMs and find that current models perform better with table-based evidence while struggling with chart-based evidence. We further conduct human evaluations and observe that humans maintain strong performance across both formats, unlike the models. Our analysis also reveals that smaller multimodal LLMs (under 8B) show weak correlation in performance between table-based and chart-based tasks, indicating limited cross-modal generalization. These findings highlight a critical gap in current models' multimodal reasoning capabilities. We suggest that future multimodal LLMs should place greater emphasis on improving chart understanding to better support scientific claim verification.
Table-Text Alignment: Explaining Claim Verification Against Tables in Scientific Papers
Jun 12, 2025
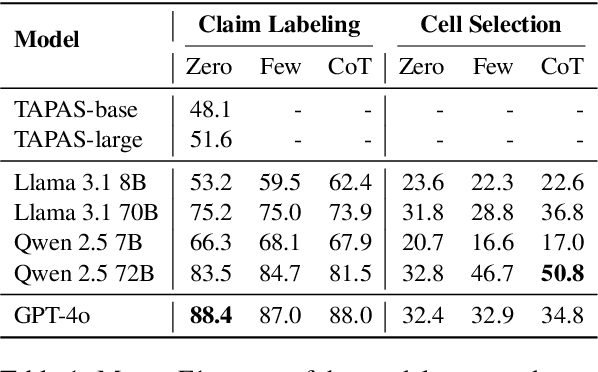
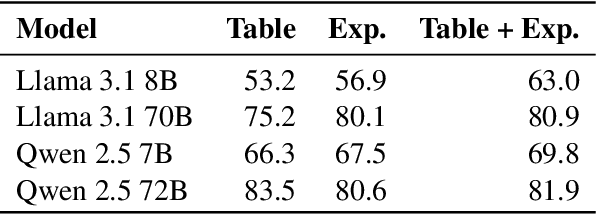
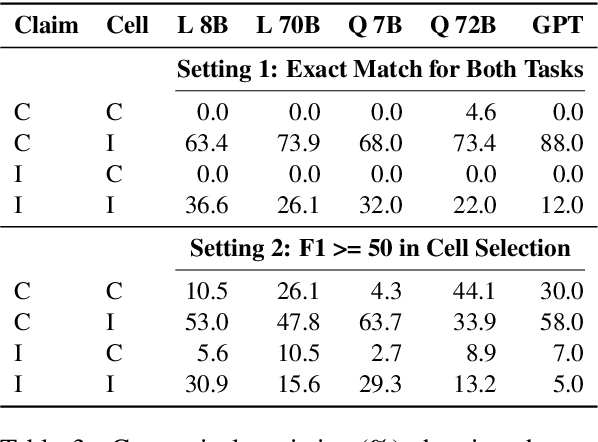
Scientific claim verification against tables typically requires predicting whether a claim is supported or refuted given a table. However, we argue that predicting the final label alone is insufficient: it reveals little about the model's reasoning and offers limited interpretability. To address this, we reframe table-text alignment as an explanation task, requiring models to identify the table cells essential for claim verification. We build a new dataset by extending the SciTab benchmark with human-annotated cell-level rationales. Annotators verify the claim label and highlight the minimal set of cells needed to support their decision. After the annotation process, we utilize the collected information and propose a taxonomy for handling ambiguous cases. Our experiments show that (i) incorporating table alignment information improves claim verification performance, and (ii) most LLMs, while often predicting correct labels, fail to recover human-aligned rationales, suggesting that their predictions do not stem from faithful reasoning.
An Analysis of Datasets, Metrics and Models in Keyphrase Generation
Jun 12, 2025
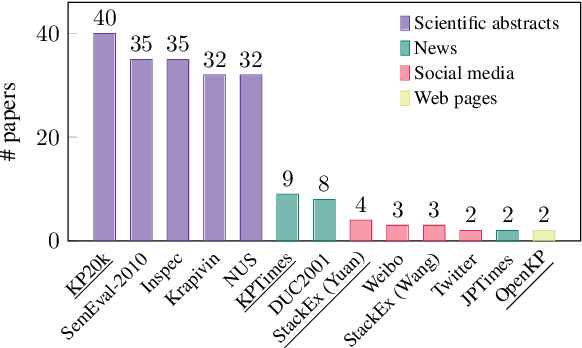
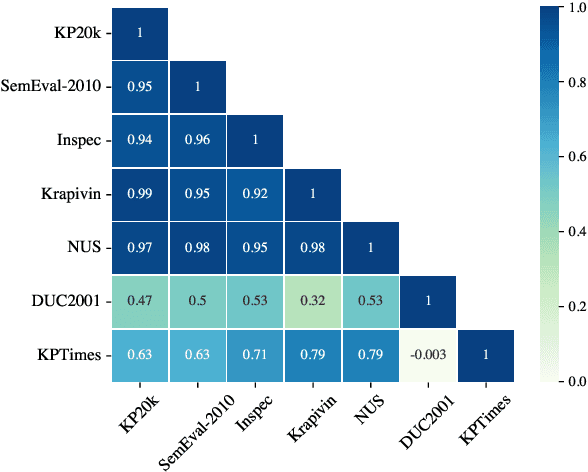
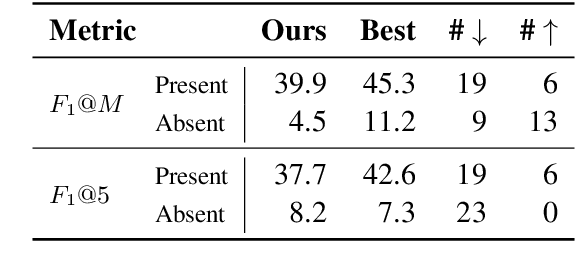
Keyphrase generation refers to the task of producing a set of words or phrases that summarises the content of a document. Continuous efforts have been dedicated to this task over the past few years, spreading across multiple lines of research, such as model architectures, data resources, and use-case scenarios. Yet, the current state of keyphrase generation remains unknown as there has been no attempt to review and analyse previous work. In this paper, we bridge this gap by presenting an analysis of over 50 research papers on keyphrase generation, offering a comprehensive overview of recent progress, limitations, and open challenges. Our findings highlight several critical issues in current evaluation practices, such as the concerning similarity among commonly-used benchmark datasets and inconsistencies in metric calculations leading to overestimated performances. Additionally, we address the limited availability of pre-trained models by releasing a strong PLM-based model for keyphrase generation as an effort to facilitate future research.
No Stupid Questions: An Analysis of Question Query Generation for Citation Recommendation
Jun 09, 2025Existing techniques for citation recommendation are constrained by their adherence to article contents and metadata. We leverage GPT-4o-mini's latent expertise as an inquisitive assistant by instructing it to ask questions which, when answered, could expose new insights about an excerpt from a scientific article. We evaluate the utility of these questions as retrieval queries, measuring their effectiveness in retrieving and ranking masked target documents. In some cases, generated questions ended up being better queries than extractive keyword queries generated by the same model. We additionally propose MMR-RBO, a variation of Maximal Marginal Relevance (MMR) using Rank-Biased Overlap (RBO) to identify which questions will perform competitively with the keyword baseline. As all question queries yield unique result sets, we contend that there are no stupid questions.
Identifying Reliable Evaluation Metrics for Scientific Text Revision
Jun 06, 2025Evaluating text revision in scientific writing remains a challenge, as traditional metrics such as ROUGE and BERTScore primarily focus on similarity rather than capturing meaningful improvements. In this work, we analyse and identify the limitations of these metrics and explore alternative evaluation methods that better align with human judgments. We first conduct a manual annotation study to assess the quality of different revisions. Then, we investigate reference-free evaluation metrics from related NLP domains. Additionally, we examine LLM-as-a-judge approaches, analysing their ability to assess revisions with and without a gold reference. Our results show that LLMs effectively assess instruction-following but struggle with correctness, while domain-specific metrics provide complementary insights. We find that a hybrid approach combining LLM-as-a-judge evaluation and task-specific metrics offers the most reliable assessment of revision quality.