 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaDA: Calibrated Probe Gating for Task-Domain LoRA Merging
Jun 03, 2026Combining a task LoRA adapter with a domain LoRA adapter into a single unified model is a practical yet largely unexplored challenge. Existing methods treat both adapters as symmetric peers, applying uniform weights across all layers. We argue that task and domain adapters exhibit a consistent depth-dependent asymmetry across transformer architectures. Domain dominance increases with layer depth, while shallower layers retain stronger task-relevant signals. Motivated by this observation, we propose $\textbf{TaDA}$ ($\textbf{Ta}$sk-$\textbf{D}$omain LoR$\textbf{A}$ Merging), a training-free algorithm that exploits this structure through calibrated probe-guided per-layer gating and per-component subspace-aware merging. The gating assigns individual weights per layer and projection type using a probe signal proved invariant to adapter weight magnitude. The merging discards conflicting singular directions before combining the remaining components. $\textbf{TaDA}$ produces a standard rank-$r$ LoRA adapter with zero inference overhead. On six scientific QA benchmarks with Llama-2-7B, TaDA achieves an average accuracy of 0.452, outperforming DARE-TIES by +3.6 percentage points and obtaining the best result on all six benchmarks. On six image classification benchmarks with ViT-L/16, TaDA reaches 85.9\% average accuracy, improving over the strongest merging baseline while leading in three of the six individual benchmarks.
Towards Efficient Large Language Models for Scientific Text: A Review
Aug 20, 2024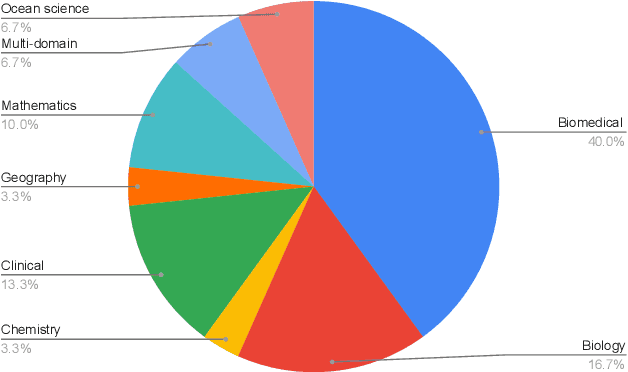

Large language models (LLMs) have ushered in a new era for processing complex information in various fields, including science. The increasing amount of scientific literature allows these models to acquire and understand scientific knowledge effectively, thus improving their performance in a wide range of tasks. Due to the power of LLMs, they require extremely expensive computational resources, intense amounts of data, and training time. Therefore, in recent years, researchers have proposed various methodologies to make scientific LLMs more affordable. The most well-known approaches align in two directions. It can be either focusing on the size of the models or enhancing the quality of data. To date, a comprehensive review of these two families of methods has not yet been undertaken. In this paper, we (I) summarize the current advances in the emerging abilities of LLMs into more accessible AI solutions for science, and (II) investigate the challenges and opportunities of developing affordable solutions for scientific domains using LLMs.
SKT5SciSumm - A Hybrid Generative Approach for Multi-Document Scientific Summarization
Feb 27, 2024



Summarization for scientific text has shown significant benefits both for the research community and human society. Given the fact that the nature of scientific text is distinctive and the input of the multi-document summarization task is substantially long, the task requires sufficient embedding generation and text truncation without losing important information. To tackle these issues, in this paper, we propose SKT5SciSumm - a hybrid framework for multi-document scientific summarization (MDSS). We leverage the Sentence-Transformer version of Scientific Paper Embeddings using Citation-Informed Transformers (SPECTER) to encode and represent textual sentences, allowing for efficient extractive summarization using k-means clustering. We employ the T5 family of models to generate abstractive summaries using extracted sentences. SKT5SciSumm achieves state-of-the-art performance on the Multi-XScience dataset. Through extensive experiments and evaluation, we showcase the benefits of our model by using less complicated models to achieve remarkable results, thereby highlighting its potential in advancing the field of multi-document summarization for scientific text.
A Survey of Pre-trained Language Models for Processing Scientific Text
Jan 31, 2024The number of Language Models (LMs) dedicated to processing scientific text is on the rise. Keeping pace with the rapid growth of scientific LMs (SciLMs) has become a daunting task for researchers. To date, no comprehensive surveys on SciLMs have been undertaken, leaving this issue unaddressed. Given the constant stream of new SciLMs, appraising the state-of-the-art and how they compare to each other remain largely unknown. This work fills that gap and provides a comprehensive review of SciLMs, including an extensive analysis of their effectiveness across different domains, tasks and datasets, and a discussion on the challenges that lie ahead.
Gender Prediction Based on Vietnamese Names with Machine Learning Techniques
Oct 27, 2020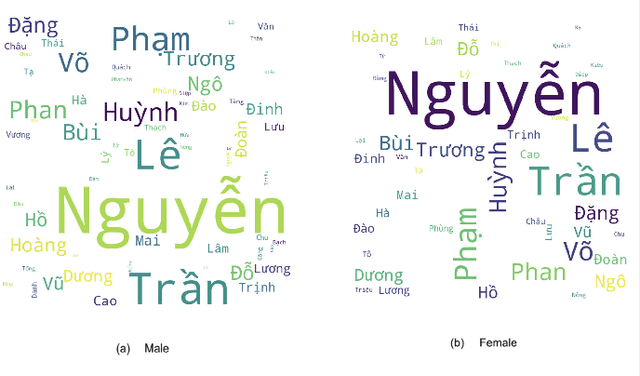

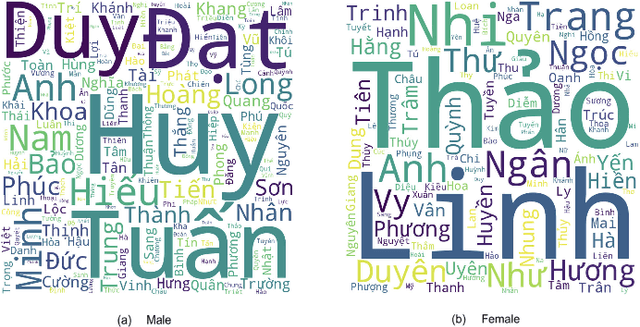
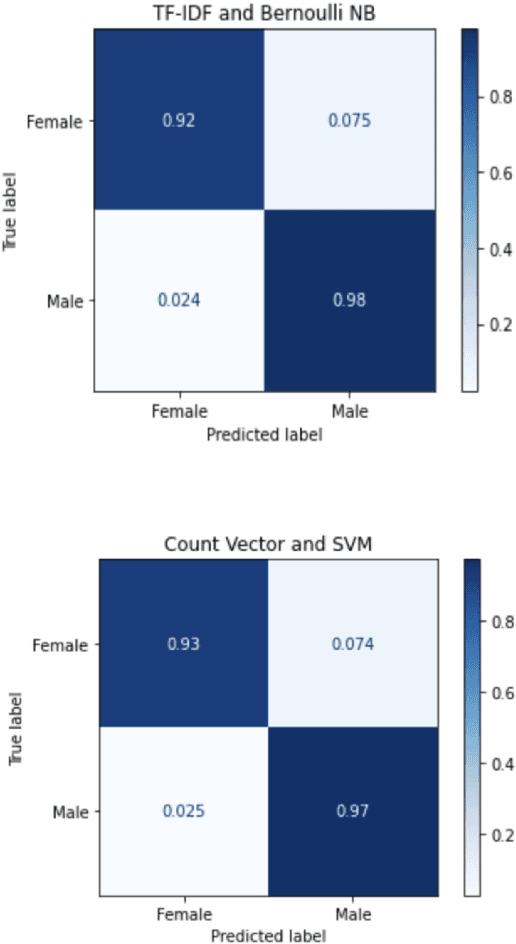
As biological gender is one of the aspects of presenting individual human, much work has been done on gender classification based on people names. The proposals for English and Chinese languages are tremendous; still, there have been few works done for Vietnamese so far. We propose a new dataset for gender prediction based on Vietnamese names. This dataset comprises over 26,000 full names annotated with genders. This dataset is available on our website for research purposes. In addition, this paper describes six machine learning algorithms (Support Vector Machine, Multinomial Naive Bayes, Bernoulli Naive Bayes, Decision Tree, Random Forrest and Logistic Regression) and a deep learning model (LSTM) with fastText word embedding for gender prediction on Vietnamese names. We create a dataset and investigate the impact of each name component on detecting gender. As a result, the best F1-score that we have achieved is up to 96\% on LSTM model and we generate a web API based on our trained model.