 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaDA: Calibrated Probe Gating for Task-Domain LoRA Merging
Jun 03, 2026Combining a task LoRA adapter with a domain LoRA adapter into a single unified model is a practical yet largely unexplored challenge. Existing methods treat both adapters as symmetric peers, applying uniform weights across all layers. We argue that task and domain adapters exhibit a consistent depth-dependent asymmetry across transformer architectures. Domain dominance increases with layer depth, while shallower layers retain stronger task-relevant signals. Motivated by this observation, we propose $\textbf{TaDA}$ ($\textbf{Ta}$sk-$\textbf{D}$omain LoR$\textbf{A}$ Merging), a training-free algorithm that exploits this structure through calibrated probe-guided per-layer gating and per-component subspace-aware merging. The gating assigns individual weights per layer and projection type using a probe signal proved invariant to adapter weight magnitude. The merging discards conflicting singular directions before combining the remaining components. $\textbf{TaDA}$ produces a standard rank-$r$ LoRA adapter with zero inference overhead. On six scientific QA benchmarks with Llama-2-7B, TaDA achieves an average accuracy of 0.452, outperforming DARE-TIES by +3.6 percentage points and obtaining the best result on all six benchmarks. On six image classification benchmarks with ViT-L/16, TaDA reaches 85.9\% average accuracy, improving over the strongest merging baseline while leading in three of the six individual benchmarks.
Towards Efficient Large Language Models for Scientific Text: A Review
Aug 20, 2024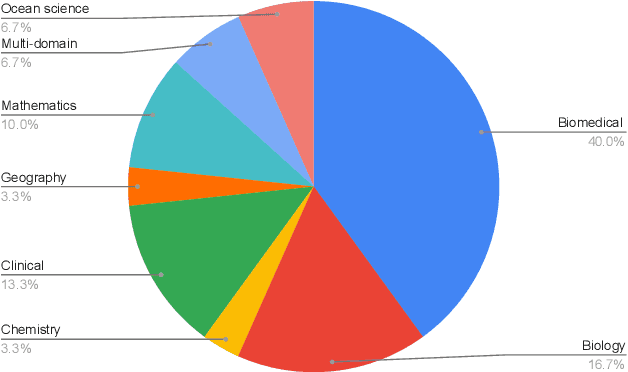

Large language models (LLMs) have ushered in a new era for processing complex information in various fields, including science. The increasing amount of scientific literature allows these models to acquire and understand scientific knowledge effectively, thus improving their performance in a wide range of tasks. Due to the power of LLMs, they require extremely expensive computational resources, intense amounts of data, and training time. Therefore, in recent years, researchers have proposed various methodologies to make scientific LLMs more affordable. The most well-known approaches align in two directions. It can be either focusing on the size of the models or enhancing the quality of data. To date, a comprehensive review of these two families of methods has not yet been undertaken. In this paper, we (I) summarize the current advances in the emerging abilities of LLMs into more accessible AI solutions for science, and (II) investigate the challenges and opportunities of developing affordable solutions for scientific domains using LLMs.
SS-shapelets: Semi-supervised Clustering of Time Series Using Representative Shapelets
Apr 06, 2023



Shapelets that discriminate time series using local features (subsequences) are promising for time series clustering. Existing time series clustering methods may fail to capture representative shapelets because they discover shapelets from a large pool of uninformative subsequences, and thus result in low clustering accuracy. This paper proposes a Semi-supervised Clustering of Time Series Using Representative Shapelets (SS-Shapelets) method, which utilizes a small number of labeled and propagated pseudo-labeled time series to help discover representative shapelets, thereby improving the clustering accuracy. In SS-Shapelets, we propose two techniques to discover representative shapelets for the effective clustering of time series. 1) A \textit{salient subsequence chain} ($SSC$) that can extract salient subsequences (as candidate shapelets) of a labeled/pseudo-labeled time series, which helps remove massive uninformative subsequences from the pool. 2) A \textit{linear discriminant selection} ($LDS$) algorithm to identify shapelets that can capture representative local features of time series in different classes, for convenient clustering. Experiments on UCR time series datasets demonstrate that SS-shapelets discovers representative shapelets and achieves higher clustering accuracy than counterpart semi-supervised time series clustering methods.
PIE-QG: Paraphrased Information Extraction for Unsupervised Question Generation from Small Corpora
Jan 03, 2023



Supervised Question Answering systems (QA systems) rely on domain-specific human-labeled data for training. Unsupervised QA systems generate their own question-answer training pairs, typically using secondary knowledge sources to achieve this outcome. Our approach (called PIE-QG) uses Open Information Extraction (OpenIE) to generate synthetic training questions from paraphrased passages and uses the question-answer pairs as training data for a language model for a state-of-the-art QA system based on BERT. Triples in the form of <subject, predicate, object> are extracted from each passage, and questions are formed with subjects (or objects) and predicates while objects (or subjects) are considered as answers. Experimenting on five extractive QA datasets demonstrates that our technique achieves on-par performance with existing state-of-the-art QA systems with the benefit of being trained on an order of magnitude fewer documents and without any recourse to external reference data sources.
Representation Learning for Short Text Clustering
Sep 21, 2021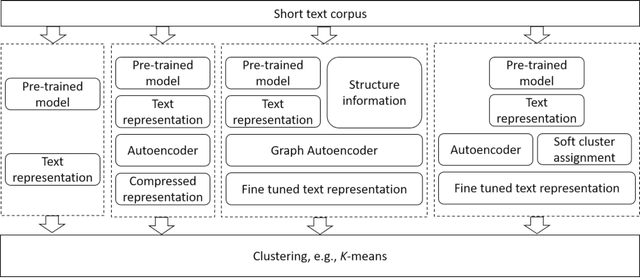
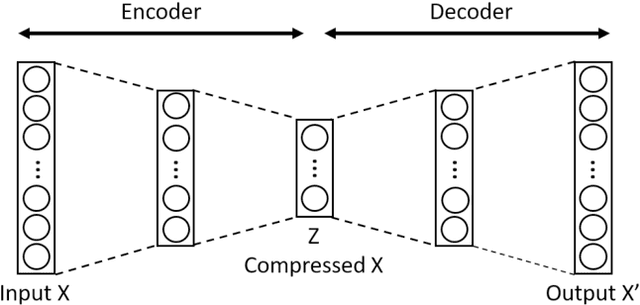
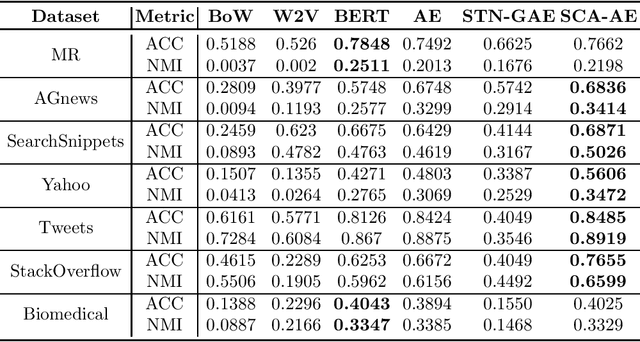
Effective representation learning is critical for short text clustering due to the sparse, high-dimensional and noise attributes of short text corpus. Existing pre-trained models (e.g., Word2vec and BERT) have greatly improved the expressiveness for short text representations with more condensed, low-dimensional and continuous features compared to the traditional Bag-of-Words (BoW) model. However, these models are trained for general purposes and thus are suboptimal for the short text clustering task. In this paper, we propose two methods to exploit the unsupervised autoencoder (AE) framework to further tune the short text representations based on these pre-trained text models for optimal clustering performance. In our first method Structural Text Network Graph Autoencoder (STN-GAE), we exploit the structural text information among the corpus by constructing a text network, and then adopt graph convolutional network as encoder to fuse the structural features with the pre-trained text features for text representation learning. In our second method Soft Cluster Assignment Autoencoder (SCA-AE), we adopt an extra soft cluster assignment constraint on the latent space of autoencoder to encourage the learned text representations to be more clustering-friendly. We tested two methods on seven popular short text datasets, and the experimental results show that when only using the pre-trained model for short text clustering, BERT performs better than BoW and Word2vec. However, as long as we further tune the pre-trained representations, the proposed method like SCA-AE can greatly increase the clustering performance, and the accuracy improvement compared to use BERT alone could reach as much as 14\%.