 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Aware Visual Representation Learning for Medical Visual Question Answering
Jun 04, 2026Medical visual question answering (Med-VQA) has strong potential for clinical decision support by enabling AI models to interpret medical images and answer clinically relevant queries. Recent approaches typically connect off-the-shelf vision encoders with large language models (LLMs) through lightweight mapping networks to reduce computational cost. However, these methods often overlook the importance of handling noise and small irrelevant changes in visual representations. To address these challenges, we propose a noise-aware Med-VQA framework that incorporates a denoising autoencoder before visual embeddings are mapped into the input space of an LLM. The denoising autoencoder is pretrained to reconstruct clean visual embeddings from corrupted inputs, encouraging the model to learn robust visual representations that are less sensitive to noise. The resulting embeddings are then projected into the language model embedding space using a multi-layer perceptron (MLP), forming visual prefix tokens that provide image information to the LLM. To enable efficient adaptation without full retraining, we employ parameter-efficient fine-tuning using low-rank adaptation (LoRA). The proposed method is evaluated on the SLAKE and PathVQA benchmarks. Experimental results show improved robustness to noisy input embeddings while maintaining competitive clean performance across multiple evaluation criteria. These findings suggest that learning more robust visual representations can enhance Med-VQA performance and robustness.
When Evidence Contradicts: Toward Safer Retrieval-Augmented Generation in Healthcare
Nov 10, 2025In high-stakes information domains such as healthcare, where large language models (LLMs) can produce hallucinations or misinformation, retrieval-augmented generation (RAG) has been proposed as a mitigation strategy, grounding model outputs in external, domain-specific documents. Yet, this approach can introduce errors when source documents contain outdated or contradictory information. This work investigates the performance of five LLMs in generating RAG-based responses to medicine-related queries. Our contributions are three-fold: i) the creation of a benchmark dataset using consumer medicine information documents from the Australian Therapeutic Goods Administration (TGA), where headings are repurposed as natural language questions, ii) the retrieval of PubMed abstracts using TGA headings, stratified across multiple publication years, to enable controlled temporal evaluation of outdated evidence, and iii) a comparative analysis of the frequency and impact of outdated or contradictory content on model-generated responses, assessing how LLMs integrate and reconcile temporally inconsistent information. Our findings show that contradictions between highly similar abstracts do, in fact, degrade performance, leading to inconsistencies and reduced factual accuracy in model answers. These results highlight that retrieval similarity alone is insufficient for reliable medical RAG and underscore the need for contradiction-aware filtering strategies to ensure trustworthy responses in high-stakes domains.
Synthetic Dialogue Dataset Generation using LLM Agents
Jan 30, 2024

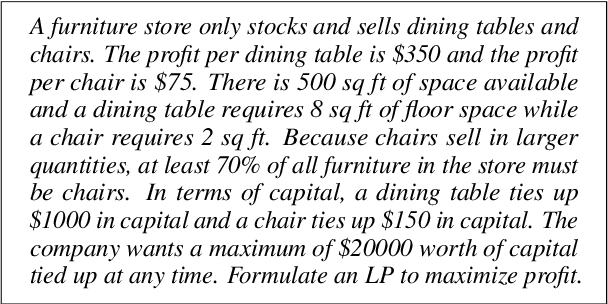
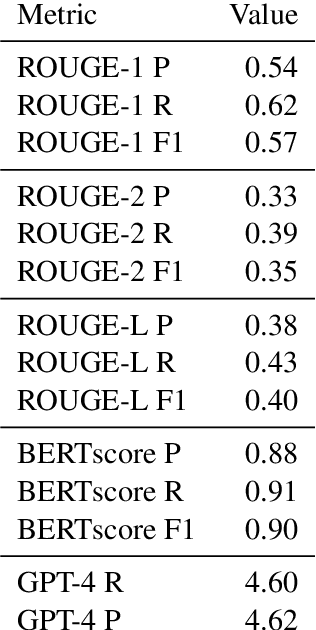
Linear programming (LP) problems are pervasive in real-life applications. However, despite their apparent simplicity, an untrained user may find it difficult to determine the linear model of their specific problem. We envisage the creation of a goal-oriented conversational agent that will engage in conversation with the user to elicit all information required so that a subsequent agent can generate the linear model. In this paper, we present an approach for the generation of sample dialogues that can be used to develop and train such a conversational agent. Using prompt engineering, we develop two agents that "talk" to each other, one acting as the conversational agent, and the other acting as the user. Using a set of text descriptions of linear problems from NL4Opt available to the user only, the agent and the user engage in conversation until the agent has retrieved all key information from the original problem description. We also propose an extrinsic evaluation of the dialogues by assessing how well the summaries generated by the dialogues match the original problem descriptions. We conduct human and automatic evaluations, including an evaluation approach that uses GPT-4 to mimic the human evaluation metrics. The evaluation results show an overall good quality of the dialogues, though research is still needed to improve the quality of the GPT-4 evaluation metrics. The resulting dialogues, including the human annotations of a subset, are available to the research community. The conversational agent used for the generation of the dialogues can be used as a baseline.
PIE-QG: Paraphrased Information Extraction for Unsupervised Question Generation from Small Corpora
Jan 03, 2023



Supervised Question Answering systems (QA systems) rely on domain-specific human-labeled data for training. Unsupervised QA systems generate their own question-answer training pairs, typically using secondary knowledge sources to achieve this outcome. Our approach (called PIE-QG) uses Open Information Extraction (OpenIE) to generate synthetic training questions from paraphrased passages and uses the question-answer pairs as training data for a language model for a state-of-the-art QA system based on BERT. Triples in the form of <subject, predicate, object> are extracted from each passage, and questions are formed with subjects (or objects) and predicates while objects (or subjects) are considered as answers. Experimenting on five extractive QA datasets demonstrates that our technique achieves on-par performance with existing state-of-the-art QA systems with the benefit of being trained on an order of magnitude fewer documents and without any recourse to external reference data sources.
A Knowledge Representation Approach to Automated Mathematical Modelling
Nov 12, 2020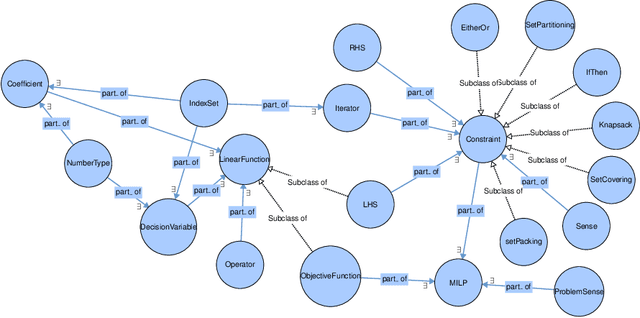
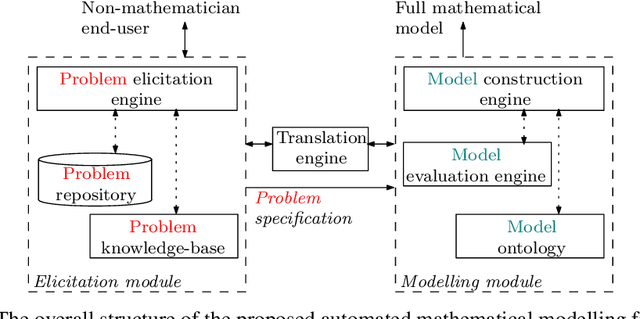
Mathematicians formulate complex mathematical models based on user requirements to solve a diverse range of problems in different domains. These models are, in most cases, represented through several mathematical equations and constraints. This modelling task comprises several time-intensive processes that require both mathematical expertise and (problem) domain knowledge. In an attempt to automate these processes, we have developed an ontology for Mixed Integer Linear Programming (MILP) problems to formulate expert mathematician knowledge and in this paper, we show how this new ontology can be utilized for modelling a relatively straightforward MILP problem, a Machine Scheduling example. We also show that more complex MILP problems, such as the Asymmetric Travelling Salesman Problem (ATSP), however, are not readily amenable to simple elicitation of user requirements and the utilization of the proposed mathematical model ontology. Therefore, an automatic mathematical modelling framework is proposed for such complex MILP problems, which includes a problem (requirement) elicitation module connected to a model extraction module through a translation engine that bridges between the non-expert problem domain and the expert mathematical model domain. This framework is argued to have the necessary components to effectively tackle the automation of modelling task of the more intricate MILP problems such as the ATSP.