 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMalMoE: Mixture-of-Experts Enhanced Encrypted Malicious Traffic Detection Under Graph Drift
Feb 10, 2026Encryption has been commonly used in network traffic to secure transmission, but it also brings challenges for malicious traffic detection, due to the invisibility of the packet payload. Graph-based methods are emerging as promising solutions by leveraging multi-host interactions to promote detection accuracy. But most of them face a critical problem: Graph Drift, where the flow statistics or topological information of a graph change over time. To overcome these drawbacks, we propose a graph-assisted encrypted traffic detection system, MalMoE, which applies Mixture of Experts (MoE) to select the best expert model for drift-aware classification. Particularly, we design 1-hop-GNN-like expert models that handle different graph drifts by analyzing graphs with different features. Then, the redesigned gate model conducts expert selection according to the actual drift. MalMoE is trained with a stable two-stage training strategy with data augmentation, which effectively guides the gate on how to perform routing. Experiments on open-source, synthetic, and real-world datasets show that MalMoE can perform precise and real-time detection.
Facet: highly efficient E(3)-equivariant networks for interatomic potentials
Sep 10, 2025Computational materials discovery is limited by the high cost of first-principles calculations. Machine learning (ML) potentials that predict energies from crystal structures are promising, but existing methods face computational bottlenecks. Steerable graph neural networks (GNNs) encode geometry with spherical harmonics, respecting atomic symmetries -- permutation, rotation, and translation -- for physically realistic predictions. Yet maintaining equivariance is difficult: activation functions must be modified, and each layer must handle multiple data types for different harmonic orders. We present Facet, a GNN architecture for efficient ML potentials, developed through systematic analysis of steerable GNNs. Our innovations include replacing expensive multi-layer perceptrons (MLPs) for interatomic distances with splines, which match performance while cutting computational and memory demands. We also introduce a general-purpose equivariant layer that mixes node information via spherical grid projection followed by standard MLPs -- faster than tensor products and more expressive than linear or gate layers. On the MPTrj dataset, Facet matches leading models with far fewer parameters and under 10% of their training compute. On a crystal relaxation task, it runs twice as fast as MACE models. We further show SevenNet-0's parameters can be reduced by over 25% with no accuracy loss. These techniques enable more than 10x faster training of large-scale foundation models for ML potentials, potentially reshaping computational materials discovery.
Towards Reward Fairness in RLHF: From a Resource Allocation Perspective
May 29, 2025Rewards serve as proxies for human preferences and play a crucial role in Reinforcement Learning from Human Feedback (RLHF). However, if these rewards are inherently imperfect, exhibiting various biases, they can adversely affect the alignment of large language models (LLMs). In this paper, we collectively define the various biases present in rewards as the problem of reward unfairness. We propose a bias-agnostic method to address the issue of reward fairness from a resource allocation perspective, without specifically designing for each type of bias, yet effectively mitigating them. Specifically, we model preference learning as a resource allocation problem, treating rewards as resources to be allocated while considering the trade-off between utility and fairness in their distribution. We propose two methods, Fairness Regularization and Fairness Coefficient, to achieve fairness in rewards. We apply our methods in both verification and reinforcement learning scenarios to obtain a fairness reward model and a policy model, respectively. Experiments conducted in these scenarios demonstrate that our approach aligns LLMs with human preferences in a more fair manner.
MCBlock: Boosting Neural Radiance Field Training Speed by MCTS-based Dynamic-Resolution Ray Sampling
Apr 14, 2025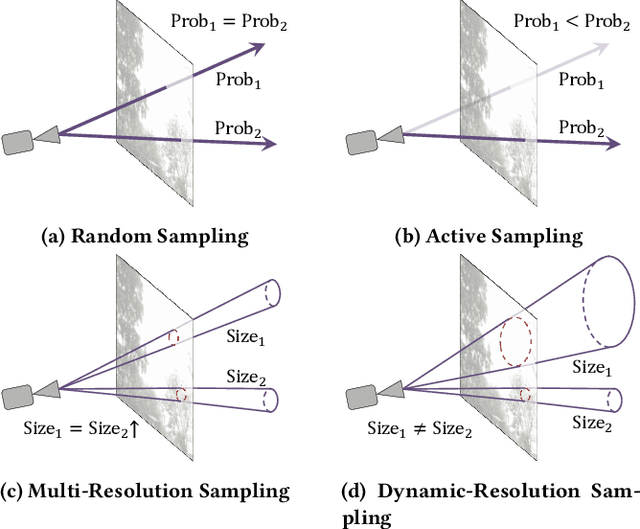
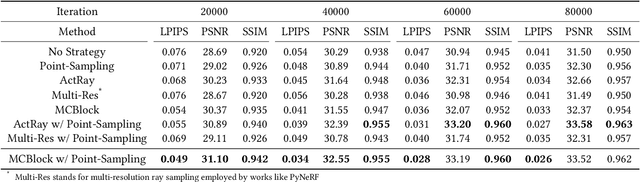


Neural Radiance Field (NeRF) is widely known for high-fidelity novel view synthesis. However, even the state-of-the-art NeRF model, Gaussian Splatting, requires minutes for training, far from the real-time performance required by multimedia scenarios like telemedicine. One of the obstacles is its inefficient sampling, which is only partially addressed by existing works. Existing point-sampling algorithms uniformly sample simple-texture regions (easy to fit) and complex-texture regions (hard to fit), while existing ray-sampling algorithms sample these regions all in the finest granularity (i.e. the pixel level), both wasting GPU training resources. Actually, regions with different texture intensities require different sampling granularities. To this end, we propose a novel dynamic-resolution ray-sampling algorithm, MCBlock, which employs Monte Carlo Tree Search (MCTS) to partition each training image into pixel blocks with different sizes for active block-wise training. Specifically, the trees are initialized according to the texture of training images to boost the initialization speed, and an expansion/pruning module dynamically optimizes the block partition. MCBlock is implemented in Nerfstudio, an open-source toolset, and achieves a training acceleration of up to 2.33x, surpassing other ray-sampling algorithms. We believe MCBlock can apply to any cone-tracing NeRF model and contribute to the multimedia community.
SPPD: Self-training with Process Preference Learning Using Dynamic Value Margin
Feb 19, 2025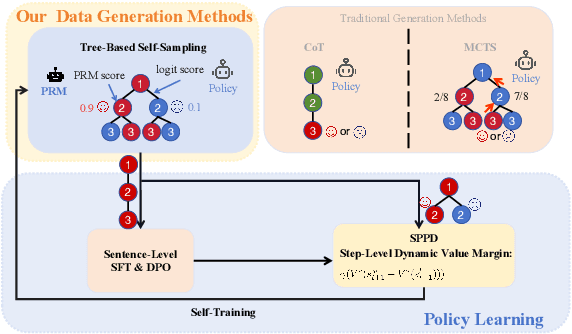
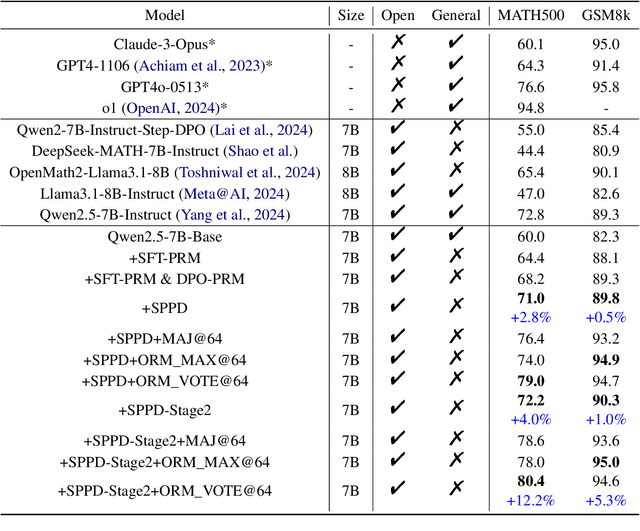
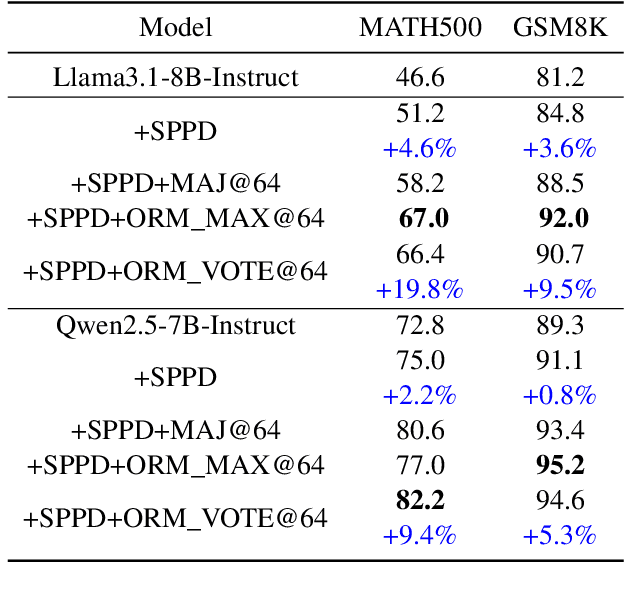
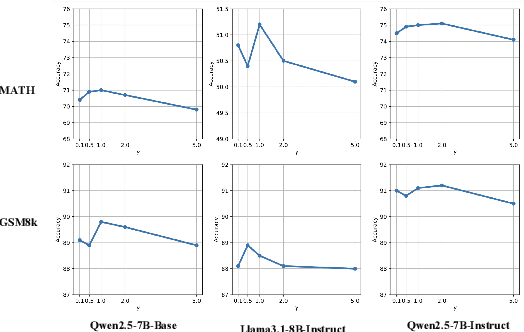
Recently, enhancing the numerical and logical reasoning capability of Large Language Models (LLMs) has emerged as a research hotspot. Existing methods face several limitations: inference-phase techniques (e.g., Chain of Thoughts) rely on prompt selection and the pretrained knowledge; sentence-level Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) struggle with step-wise mathematical correctness and depend on stronger models distillation or human annotations; while Reinforcement Learning (RL) approaches incur high GPU memory costs and unstable training. To address these, we propose \textbf{S}elf-training framework integrating \textbf{P}rocess \textbf{P}reference learning using \textbf{D}ynamic value margin (SPPD). SPPD leverages a process-based Markov Decision Process (MDP) and Bellman optimality equation to derive \textbf{dynamic value margin} on step-level preference optimization, which employs tree-based self-sampling on model responses \textbf{without any distillation} from other models. Furthermore, we theoretically prove that SPPD is \textbf{equivalent to on-policy policy gradient methods} under reward constraints. Experiments on 7B-scale models demonstrate superior performance across in-domain and out-domain mathematical benchmarks. We open-source our code at \href{https://anonymous.4open.science/r/SSDPO-D-DCDD}{https://anonymous.4open.science/r/SPPD-DCDD}.
Video-Text Dataset Construction from Multi-AI Feedback: Promoting Weak-to-Strong Preference Learning for Video Large Language Models
Nov 25, 2024



High-quality video-text preference data is crucial for Multimodal Large Language Models (MLLMs) alignment. However, existing preference data is very scarce. Obtaining VQA preference data for preference training is costly, and manually annotating responses is highly unreliable, which could result in low-quality pairs. Meanwhile, AI-generated responses controlled by temperature adjustment lack diversity. To address these issues, we propose a high-quality VQA preference dataset, called \textit{\textbf{M}ultiple \textbf{M}ultimodal \textbf{A}rtificial \textbf{I}ntelligence \textbf{P}reference Datasets in \textbf{V}QA} (\textbf{MMAIP-V}), which is constructed by sampling from the response distribution set and using an external scoring function for response evaluation. Furthermore, to fully leverage the preference knowledge in MMAIP-V and ensure sufficient optimization, we propose \textit{\textbf{Iter}ative \textbf{W}eak-to-\textbf{S}trong \textbf{R}einforcement \textbf{L}earning from \textbf{AI} \textbf{F}eedback for video MLLMs} (\textbf{Iter-W2S-RLAIF}), a framework that gradually enhances MLLMs' alignment capabilities by iteratively updating the reference model and performing parameter extrapolation. Finally, we propose an unbiased and information-complete evaluation scheme in VQA evaluation. Experiments demonstrate that MMAIP-V is beneficial for MLLMs in preference learning and Iter-W2S-RLAIF fully exploits the alignment information in MMAIP-V. We believe that the proposed automatic VQA preference data generation pipeline based on AI feedback can greatly promote future work in the MLLMs alignment. \textbf{Code and dataset are available} \href{https://anonymous.4open.science/r/MMAIP-V_Iter-W2S-RLAIF-702F}{MMAIP-V\_Iter-W2S-RLAIF-702F}.
Investigating the Synergistic Effects of Dropout and Residual Connections on Language Model Training
Oct 01, 2024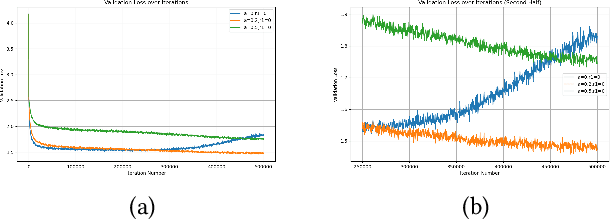
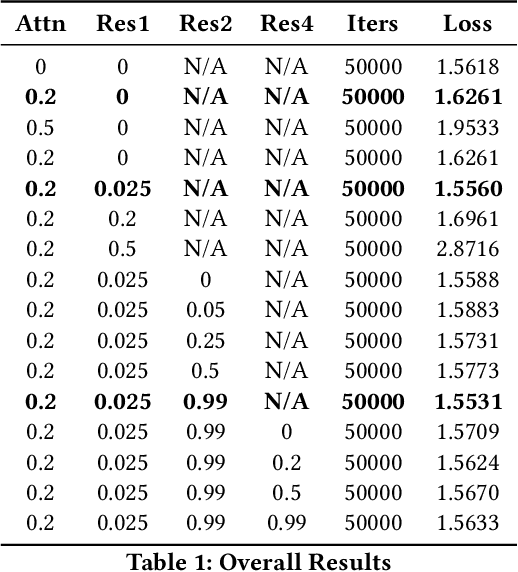
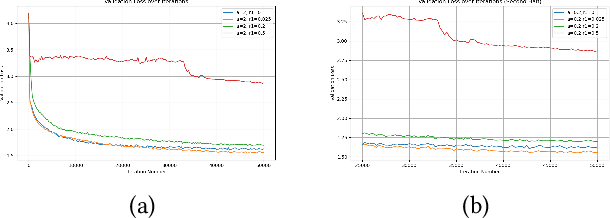
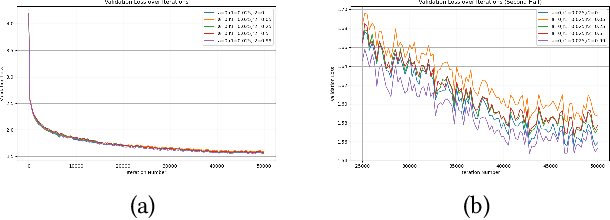
This paper examines the pivotal role of dropout techniques in mitigating overfitting in language model training. It conducts a comprehensive investigation into the influence of variable dropout rates on both individual layers and residual connections within the context of language modeling. Our study conducts training of a decoder implementation on the classic Tiny Shakespeare data to examine the effects of the adjustments on training efficiency and validation error. Results not only confirm the benefits of dropout for regularization and residuals for convergence, but also reveal their interesting interactions. There exists an important trade-off between the depth of residual connections and the dropout on these connections for optimal deep neural network convergence and generalization.
TSO: Self-Training with Scaled Preference Optimization
Aug 31, 2024



Enhancing the conformity of large language models (LLMs) to human preferences remains an ongoing research challenge. Recently, offline approaches such as Direct Preference Optimization (DPO) have gained prominence as attractive options due to offering effective improvement in simple, efficient, and stable without interactions with reward models. However, these offline preference optimization methods highly rely on the quality of pairwise preference samples. Meanwhile, numerous iterative methods require additional training of reward models to select positive and negative samples from the model's own generated responses for preference learning. Furthermore, as LLMs' capabilities advance, it is quite challenging to continuously construct high-quality positive and negative preference instances from the model's outputs due to the lack of diversity. To tackle these challenges, we propose TSO, or Self-Training with Scaled Preference Optimization, a framework for preference optimization that conducts self-training preference learning without training an additional reward model. TSO enhances the diversity of responses by constructing a model matrix and incorporating human preference responses. Furthermore, TSO introduces corrections for model preference errors through human and AI feedback. Finally, TSO adopts iterative and dual clip reward strategies to update the reference model and its responses, adaptively adjusting preference data and balancing the optimization process. Experimental results demonstrate that TSO outperforms existing mainstream methods on various alignment evaluation benchmarks, providing practical insight into preference data construction and model training strategies in the alignment domain.
Towards Comprehensive Preference Data Collection for Reward Modeling
Jun 24, 2024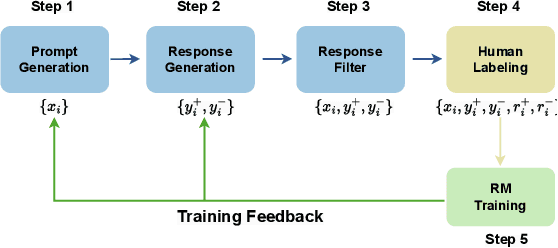

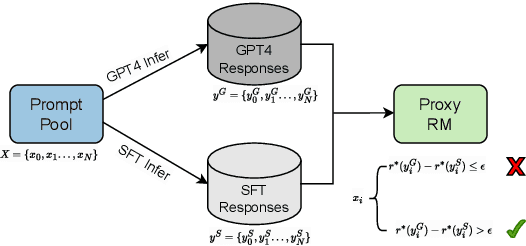
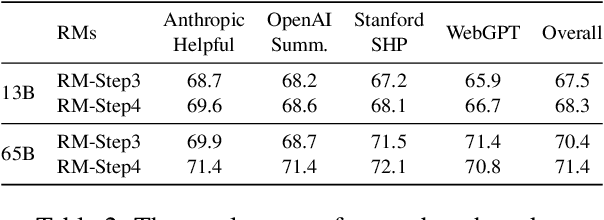
Reinforcement Learning from Human Feedback (RLHF) facilitates the alignment of large language models (LLMs) with human preferences, thereby enhancing the quality of responses generated. A critical component of RLHF is the reward model, which is trained on preference data and outputs a scalar reward during the inference stage. However, the collection of preference data still lacks thorough investigation. Recent studies indicate that preference data is collected either by AI or humans, where chosen and rejected instances are identified among pairwise responses. We question whether this process effectively filters out noise and ensures sufficient diversity in collected data. To address these concerns, for the first time, we propose a comprehensive framework for preference data collection, decomposing the process into four incremental steps: Prompt Generation, Response Generation, Response Filtering, and Human Labeling. This structured approach ensures the collection of high-quality preferences while reducing reliance on human labor. We conducted comprehensive experiments based on the data collected at different stages, demonstrating the effectiveness of the proposed data collection method.
DoLLM: How Large Language Models Understanding Network Flow Data to Detect Carpet Bombing DDoS
May 13, 2024



It is an interesting question Can and How Large Language Models (LLMs) understand non-language network data, and help us detect unknown malicious flows. This paper takes Carpet Bombing as a case study and shows how to exploit LLMs' powerful capability in the networking area. Carpet Bombing is a new DDoS attack that has dramatically increased in recent years, significantly threatening network infrastructures. It targets multiple victim IPs within subnets, causing congestion on access links and disrupting network services for a vast number of users. Characterized by low-rates, multi-vectors, these attacks challenge traditional DDoS defenses. We propose DoLLM, a DDoS detection model utilizes open-source LLMs as backbone. By reorganizing non-contextual network flows into Flow-Sequences and projecting them into LLMs semantic space as token embeddings, DoLLM leverages LLMs' contextual understanding to extract flow representations in overall network context. The representations are used to improve the DDoS detection performance. We evaluate DoLLM with public datasets CIC-DDoS2019 and real NetFlow trace from Top-3 countrywide ISP. The tests have proven that DoLLM possesses strong detection capabilities. Its F1 score increased by up to 33.3% in zero-shot scenarios and by at least 20.6% in real ISP traces.