 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPPD: Self-training with Process Preference Learning Using Dynamic Value Margin
Paper and Code
Feb 19, 2025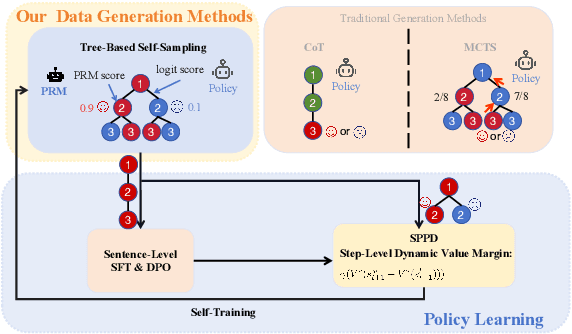
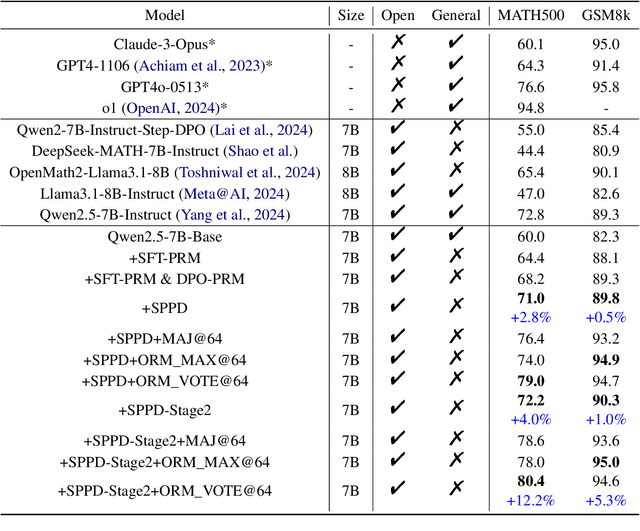
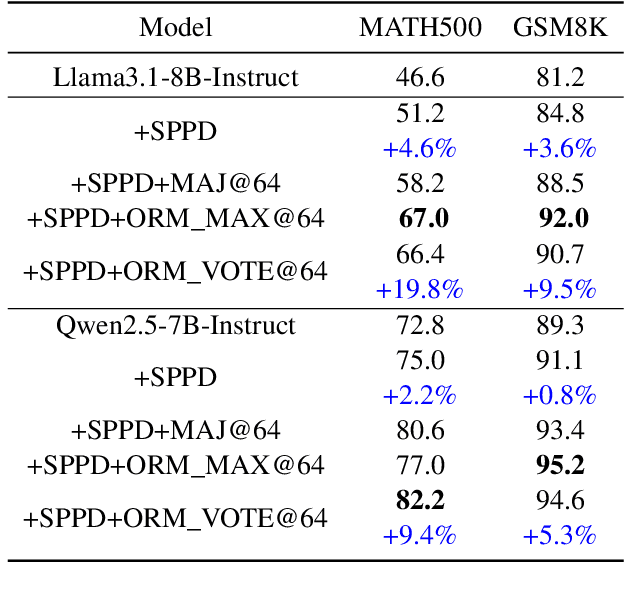
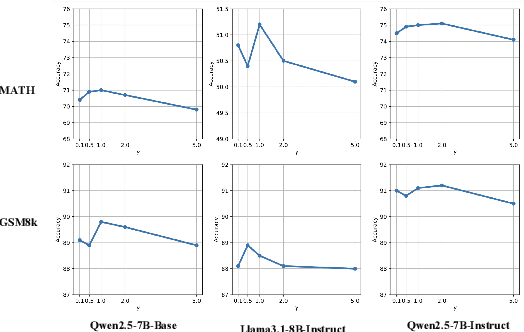
Recently, enhancing the numerical and logical reasoning capability of Large Language Models (LLMs) has emerged as a research hotspot. Existing methods face several limitations: inference-phase techniques (e.g., Chain of Thoughts) rely on prompt selection and the pretrained knowledge; sentence-level Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) struggle with step-wise mathematical correctness and depend on stronger models distillation or human annotations; while Reinforcement Learning (RL) approaches incur high GPU memory costs and unstable training. To address these, we propose \textbf{S}elf-training framework integrating \textbf{P}rocess \textbf{P}reference learning using \textbf{D}ynamic value margin (SPPD). SPPD leverages a process-based Markov Decision Process (MDP) and Bellman optimality equation to derive \textbf{dynamic value margin} on step-level preference optimization, which employs tree-based self-sampling on model responses \textbf{without any distillation} from other models. Furthermore, we theoretically prove that SPPD is \textbf{equivalent to on-policy policy gradient methods} under reward constraints. Experiments on 7B-scale models demonstrate superior performance across in-domain and out-domain mathematical benchmarks. We open-source our code at \href{https://anonymous.4open.science/r/SSDPO-D-DCDD}{https://anonymous.4open.science/r/SPPD-DCDD}.