 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn More with Less: Uncertainty Consistency Guided Query Selection for RLVR
Jan 30, 2026Large Language Models (LLMs) have recently improved mathematical reasoning through Reinforcement Learning with Verifiable Reward (RLVR). However, existing RLVR algorithms require large query budgets, making annotation costly. We investigate whether fewer but more informative queries can yield similar or superior performance, introducing active learning (AL) into RLVR. We identify that classic AL sampling strategies fail to outperform random selection in this setting, due to ignoring objective uncertainty when only selecting by subjective uncertainty. This work proposes an uncertainty consistency metric to evaluate how well subjective uncertainty aligns with objective uncertainty. In the offline setting, this alignment is measured using the Point-Biserial Correlation Coefficient (PBC). For online training, because of limited sampling and dynamically shifting output distributions, PBC estimation is difficult. Therefore, we introduce a new online variant, computed from normalized advantage and subjective uncertainty. Theoretically, we prove that the online variant is strictly negatively correlated with offline PBC and supports better sample selection. Experiments show our method consistently outperforms random and classic AL baselines, achieving full-dataset performance while training on only 30% of the data, effectively reducing the cost of RLVR for reasoning tasks.
No More Stale Feedback: Co-Evolving Critics for Open-World Agent Learning
Jan 11, 2026Critique-guided reinforcement learning (RL) has emerged as a powerful paradigm for training LLM agents by augmenting sparse outcome rewards with natural-language feedback. However, current methods often rely on static or offline critic models, which fail to adapt as the policy evolves. In on-policy RL, the agent's error patterns shift over time, causing stationary critics to become stale and providing feedback of diminishing utility. To address this, we introduce ECHO (Evolving Critic for Hindsight-Guided Optimization)}, a framework that jointly optimizes the policy and critic through a synchronized co-evolutionary loop. ECHO utilizes a cascaded rollout mechanism where the critic generates multiple diagnoses for an initial trajectory, followed by policy refinement to enable group-structured advantage estimation. We address the challenge of learning plateaus via a saturation-aware gain shaping objective, which rewards the critic for inducing incremental improvements in high-performing trajectories. By employing dual-track GRPO updates, ECHO ensures the critic's feedback stays synchronized with the evolving policy. Experimental results show that ECHO yields more stable training and higher long-horizon task success across open-world environments.
TravelBench: A Broader Real-World Benchmark for Multi-Turn and Tool-Using Travel Planning
Jan 05, 2026Travel planning is a natural real-world task to test large language models (LLMs) planning and tool-use abilities. Although prior work has studied LLM performance on travel planning, existing settings still differ from real-world needs, mainly due to limited domain coverage, insufficient modeling of users' implicit preferences in multi-turn conversations, and a lack of clear evaluation of agents' capability boundaries. To mitigate these gaps, we propose \textbf{TravelBench}, a benchmark for fully real-world travel planning. We collect user queries, user profile and tools from real scenarios, and construct three subtasks-Single-Turn, Multi-Turn, and Unsolvable-to evaluate agent's three core capabilities in real settings: (1) solving problems autonomously, (2) interacting with users over multiple turns to refine requirements, and (3) recognizing the limits of own abilities. To enable stable tool invocation and reproducible evaluation, we cache real tool-call results and build a sandbox environment that integrates ten travel-related tools. Agents can combine these tools to solve most practical travel planning problems, and our systematic verification demonstrates the stability of the proposed benchmark. We further evaluate multiple LLMs on TravelBench and conduct an in-depth analysis of their behaviors and performance. TravelBench provides a practical and reproducible evaluation benchmark to advance research on LLM agents for travel planning.\footnote{Our code and data will be available after internal review.
AMAP Agentic Planning Technical Report
Dec 31, 2025We present STAgent, an agentic large language model tailored for spatio-temporal understanding, designed to solve complex tasks such as constrained point-of-interest discovery and itinerary planning. STAgent is a specialized model capable of interacting with ten distinct tools within spatio-temporal scenarios, enabling it to explore, verify, and refine intermediate steps during complex reasoning. Notably, STAgent effectively preserves its general capabilities. We empower STAgent with these capabilities through three key contributions: (1) a stable tool environment that supports over ten domain-specific tools, enabling asynchronous rollout and training; (2) a hierarchical data curation framework that identifies high-quality data like a needle in a haystack, curating high-quality queries with a filter ratio of 1:10,000, emphasizing both diversity and difficulty; and (3) a cascaded training recipe that starts with a seed SFT stage acting as a guardian to measure query difficulty, followed by a second SFT stage fine-tuned on queries with high certainty, and an ultimate RL stage that leverages data of low certainty. Initialized with Qwen3-30B-A3B to establish a strong SFT foundation and leverage insights into sample difficulty, STAgent yields promising performance on TravelBench while maintaining its general capabilities across a wide range of general benchmarks, thereby demonstrating the effectiveness of our proposed agentic model.
TravelBench: A Real-World Benchmark for Multi-Turn and Tool-Augmented Travel Planning
Dec 27, 2025Large language model (LLM) agents have demonstrated strong capabilities in planning and tool use. Travel planning provides a natural and high-impact testbed for these capabilities, as it requires multi-step reasoning, iterative preference elicitation through interaction, and calls to external tools under evolving constraints. Prior work has studied LLMs on travel-planning tasks, but existing settings are limited in domain coverage and multi-turn interaction. As a result, they cannot support dynamic user-agent interaction and therefore fail to comprehensively assess agent capabilities. In this paper, we introduce TravelBench, a real-world travel-planning benchmark featuring multi-turn interaction and tool use. We collect user requests from real-world scenarios and construct three subsets-multi-turn, single-turn, and unsolvable-to evaluate different aspects of agent performance. For stable and reproducible evaluation, we build a controlled sandbox environment with 10 travel-domain tools, providing deterministic tool outputs for reliable reasoning. We evaluate multiple LLMs on TravelBench and conduct an analysis of their behaviors and performance. TravelBench offers a practical and reproducible benchmark for advancing LLM agents in travel planning.
Towards Reward Fairness in RLHF: From a Resource Allocation Perspective
May 29, 2025Rewards serve as proxies for human preferences and play a crucial role in Reinforcement Learning from Human Feedback (RLHF). However, if these rewards are inherently imperfect, exhibiting various biases, they can adversely affect the alignment of large language models (LLMs). In this paper, we collectively define the various biases present in rewards as the problem of reward unfairness. We propose a bias-agnostic method to address the issue of reward fairness from a resource allocation perspective, without specifically designing for each type of bias, yet effectively mitigating them. Specifically, we model preference learning as a resource allocation problem, treating rewards as resources to be allocated while considering the trade-off between utility and fairness in their distribution. We propose two methods, Fairness Regularization and Fairness Coefficient, to achieve fairness in rewards. We apply our methods in both verification and reinforcement learning scenarios to obtain a fairness reward model and a policy model, respectively. Experiments conducted in these scenarios demonstrate that our approach aligns LLMs with human preferences in a more fair manner.
SPPD: Self-training with Process Preference Learning Using Dynamic Value Margin
Feb 19, 2025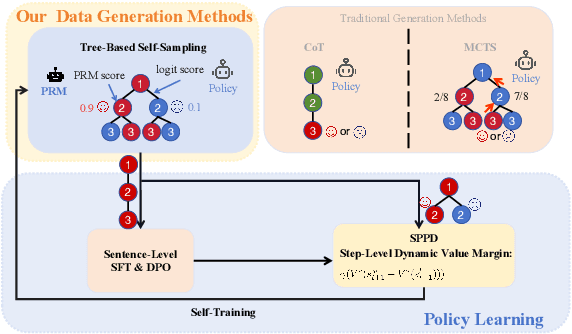
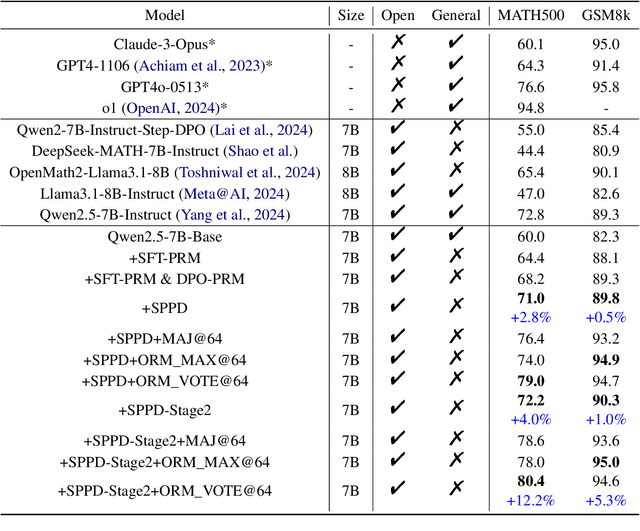
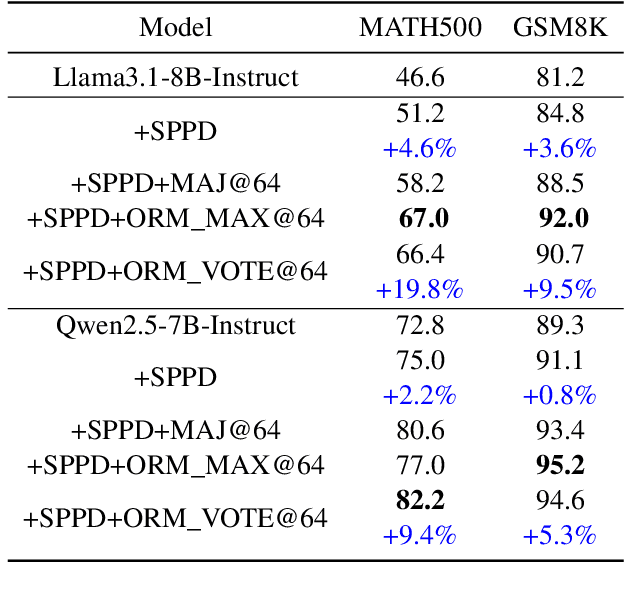
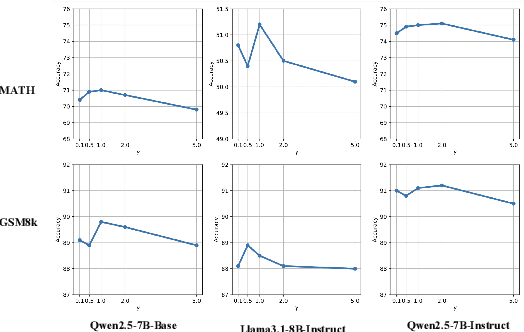
Recently, enhancing the numerical and logical reasoning capability of Large Language Models (LLMs) has emerged as a research hotspot. Existing methods face several limitations: inference-phase techniques (e.g., Chain of Thoughts) rely on prompt selection and the pretrained knowledge; sentence-level Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) struggle with step-wise mathematical correctness and depend on stronger models distillation or human annotations; while Reinforcement Learning (RL) approaches incur high GPU memory costs and unstable training. To address these, we propose \textbf{S}elf-training framework integrating \textbf{P}rocess \textbf{P}reference learning using \textbf{D}ynamic value margin (SPPD). SPPD leverages a process-based Markov Decision Process (MDP) and Bellman optimality equation to derive \textbf{dynamic value margin} on step-level preference optimization, which employs tree-based self-sampling on model responses \textbf{without any distillation} from other models. Furthermore, we theoretically prove that SPPD is \textbf{equivalent to on-policy policy gradient methods} under reward constraints. Experiments on 7B-scale models demonstrate superior performance across in-domain and out-domain mathematical benchmarks. We open-source our code at \href{https://anonymous.4open.science/r/SSDPO-D-DCDD}{https://anonymous.4open.science/r/SPPD-DCDD}.
Coarse-to-Fine Process Reward Modeling for Enhanced Mathematical Reasoning
Jan 23, 2025



Process reward model (PRM) is critical for mathematical reasoning tasks to assign rewards for each intermediate steps. The PRM requires constructing process-wise supervision data for training, which rely on chain-of-thought (CoT) or tree-based methods to construct the reasoning steps, however, the individual reasoning steps may be redundant or containing nuanced errors that difficult to detect. We attribute these to the issue of the overlook of granularity division during process data collection. In this paper, we propose a coarse-to-fine framework to tackle this issue. Specifically, while gathering the process supervision data, we collect the coarse reasoning steps by merging adjacent steps according to preset merging granularity, then we sequentially reduce the merging granularity to collect fine-grained reasoning steps. For each synthesized new step, we relabel according to the label of last step. During training, we also traverse the collected training corpus in a coarse-to-fine manner. We conduct extensive experiments on popular mathematical reasoning datasets across diverse loss criterions, the proposed framework can consistently boost the reasoning performance.
Video-Text Dataset Construction from Multi-AI Feedback: Promoting Weak-to-Strong Preference Learning for Video Large Language Models
Nov 25, 2024



High-quality video-text preference data is crucial for Multimodal Large Language Models (MLLMs) alignment. However, existing preference data is very scarce. Obtaining VQA preference data for preference training is costly, and manually annotating responses is highly unreliable, which could result in low-quality pairs. Meanwhile, AI-generated responses controlled by temperature adjustment lack diversity. To address these issues, we propose a high-quality VQA preference dataset, called \textit{\textbf{M}ultiple \textbf{M}ultimodal \textbf{A}rtificial \textbf{I}ntelligence \textbf{P}reference Datasets in \textbf{V}QA} (\textbf{MMAIP-V}), which is constructed by sampling from the response distribution set and using an external scoring function for response evaluation. Furthermore, to fully leverage the preference knowledge in MMAIP-V and ensure sufficient optimization, we propose \textit{\textbf{Iter}ative \textbf{W}eak-to-\textbf{S}trong \textbf{R}einforcement \textbf{L}earning from \textbf{AI} \textbf{F}eedback for video MLLMs} (\textbf{Iter-W2S-RLAIF}), a framework that gradually enhances MLLMs' alignment capabilities by iteratively updating the reference model and performing parameter extrapolation. Finally, we propose an unbiased and information-complete evaluation scheme in VQA evaluation. Experiments demonstrate that MMAIP-V is beneficial for MLLMs in preference learning and Iter-W2S-RLAIF fully exploits the alignment information in MMAIP-V. We believe that the proposed automatic VQA preference data generation pipeline based on AI feedback can greatly promote future work in the MLLMs alignment. \textbf{Code and dataset are available} \href{https://anonymous.4open.science/r/MMAIP-V_Iter-W2S-RLAIF-702F}{MMAIP-V\_Iter-W2S-RLAIF-702F}.
GUNDAM: Aligning Large Language Models with Graph Understanding
Sep 30, 2024



Large Language Models (LLMs) have achieved impressive results in processing text data, which has sparked interest in applying these models beyond textual data, such as graphs. In the field of graph learning, there is a growing interest in harnessing LLMs to comprehend and manipulate graph-structured data. Existing research predominantly focuses on graphs with rich textual features, such as knowledge graphs or text attribute graphs, leveraging LLMs' ability to process text but inadequately addressing graph structure. This work specifically aims to assess and enhance LLMs' abilities to comprehend and utilize the structural knowledge inherent in graph data itself, rather than focusing solely on graphs rich in textual content. To achieve this, we introduce the \textbf{G}raph \textbf{U}nderstanding for \textbf{N}atural Language \textbf{D}riven \textbf{A}nalytical \textbf{M}odel (\model). This model adapts LLMs to better understand and engage with the structure of graph data, enabling them to perform complex reasoning tasks by leveraging the graph's structure itself. Our experimental evaluations on graph reasoning benchmarks not only substantiate that \model~ outperforms the SOTA baselines for comparisons. But also reveals key factors affecting the graph reasoning capabilities of LLMs. Moreover, we provide a theoretical analysis illustrating how reasoning paths can enhance LLMs' reasoning capabilities.