 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKlear-AgentForge: Forging Agentic Intelligence through Posttraining Scaling
Nov 08, 2025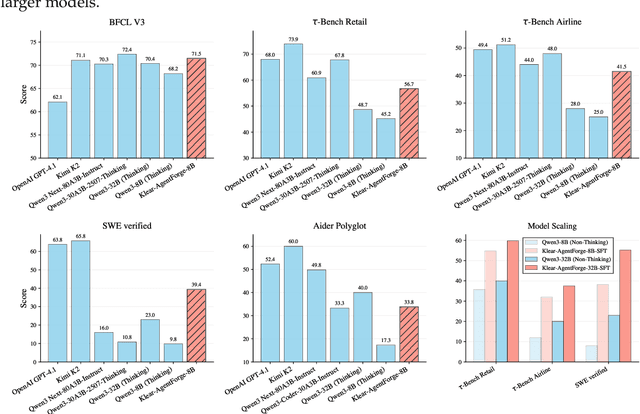
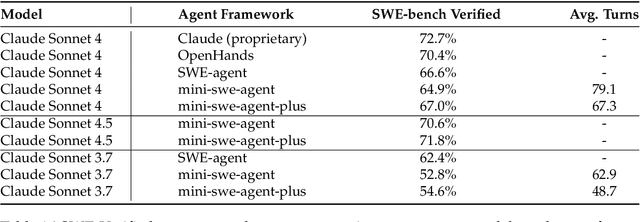
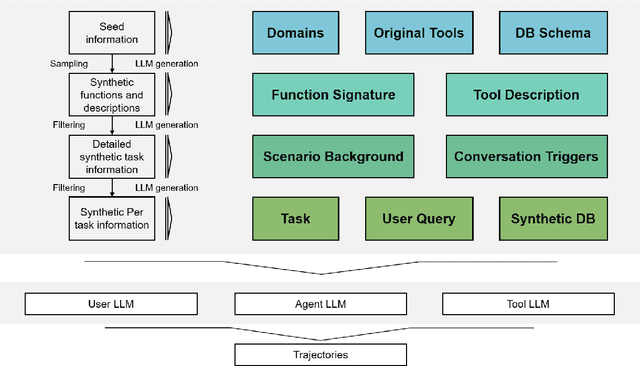
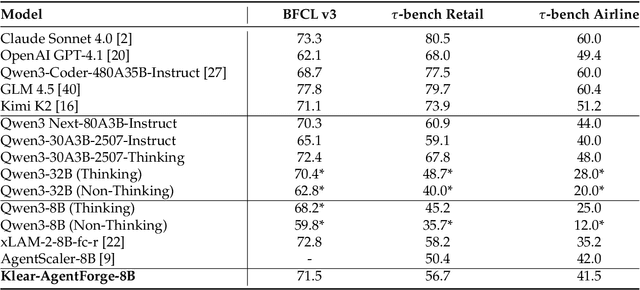
Despite the proliferation of powerful agentic models, the lack of critical post-training details hinders the development of strong counterparts in the open-source community. In this study, we present a comprehensive and fully open-source pipeline for training a high-performance agentic model for interacting with external tools and environments, named Klear-Qwen3-AgentForge, starting from the Qwen3-8B base model. We design effective supervised fine-tuning (SFT) with synthetic data followed by multi-turn reinforcement learning (RL) to unlock the potential for multiple diverse agentic tasks. We perform exclusive experiments on various agentic benchmarks in both tool use and coding domains. Klear-Qwen3-AgentForge-8B achieves state-of-the-art performance among LLMs of similar size and remains competitive with significantly larger models.
Attention as a Compass: Efficient Exploration for Process-Supervised RL in Reasoning Models
Sep 30, 2025Reinforcement Learning (RL) has shown remarkable success in enhancing the reasoning capabilities of Large Language Models (LLMs). Process-Supervised RL (PSRL) has emerged as a more effective paradigm compared to outcome-based RL. However, existing PSRL approaches suffer from limited exploration efficiency, both in terms of branching positions and sampling. In this paper, we introduce a novel PSRL framework (AttnRL), which enables efficient exploration for reasoning models. Motivated by preliminary observations that steps exhibiting high attention scores correlate with reasoning behaviors, we propose to branch from positions with high values. Furthermore, we develop an adaptive sampling strategy that accounts for problem difficulty and historical batch size, ensuring that the whole training batch maintains non-zero advantage values. To further improve sampling efficiency, we design a one-step off-policy training pipeline for PSRL. Extensive experiments on multiple challenging mathematical reasoning benchmarks demonstrate that our method consistently outperforms prior approaches in terms of performance and sampling and training efficiency.
Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization
Aug 12, 2025

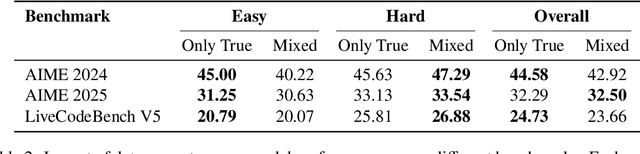

We present Klear-Reasoner, a model with long reasoning capabilities that demonstrates careful deliberation during problem solving, achieving outstanding performance across multiple benchmarks. Although there are already many excellent works related to inference models in the current community, there are still many problems with reproducing high-performance inference models due to incomplete disclosure of training details. This report provides an in-depth analysis of the reasoning model, covering the entire post-training workflow from data preparation and long Chain-of-Thought supervised fine-tuning (long CoT SFT) to reinforcement learning (RL), along with detailed ablation studies for each experimental component. For SFT data, our experiments show that a small number of high-quality data sources are more effective than a large number of diverse data sources, and that difficult samples can achieve better results without accuracy filtering. In addition, we investigate two key issues with current clipping mechanisms in RL: Clipping suppresses critical exploration signals and ignores suboptimal trajectories. To address these challenges, we propose Gradient-Preserving clipping Policy Optimization (GPPO) that gently backpropagates gradients from clipped tokens. GPPO not only enhances the model's exploration capacity but also improves its efficiency in learning from negative samples. Klear-Reasoner exhibits exceptional reasoning abilities in mathematics and programming, scoring 90.5% on AIME 2024, 83.2% on AIME 2025, 66.0% on LiveCodeBench V5 and 58.1% on LiveCodeBench V6.
AR-GRPO: Training Autoregressive Image Generation Models via Reinforcement Learning
Aug 09, 2025



Inspired by the success of reinforcement learning (RL) in refining large language models (LLMs), we propose AR-GRPO, an approach to integrate online RL training into autoregressive (AR) image generation models. We adapt the Group Relative Policy Optimization (GRPO) algorithm to refine the vanilla autoregressive models' outputs by carefully designed reward functions that evaluate generated images across multiple quality dimensions, including perceptual quality, realism, and semantic fidelity. We conduct comprehensive experiments on both class-conditional (i.e., class-to-image) and text-conditional (i.e., text-to-image) image generation tasks, demonstrating that our RL-enhanced framework significantly improves both the image quality and human preference of generated images compared to the standard AR baselines. Our results show consistent improvements across various evaluation metrics, establishing the viability of RL-based optimization for AR image generation and opening new avenues for controllable and high-quality image synthesis. The source codes and models are available at: https://github.com/Kwai-Klear/AR-GRPO.
RLEP: Reinforcement Learning with Experience Replay for LLM Reasoning
Jul 10, 2025



Reinforcement learning (RL) for large language models is an energy-intensive endeavor: training can be unstable, and the policy may gradually drift away from its pretrained weights. We present \emph{RLEP}\, -- \,Reinforcement Learning with Experience rePlay\, -- \,a two-phase framework that first collects verified trajectories and then replays them during subsequent training. At every update step, the policy is optimized on mini-batches that blend newly generated rollouts with these replayed successes. By replaying high-quality examples, RLEP steers the model away from fruitless exploration, focuses learning on promising reasoning paths, and delivers both faster convergence and stronger final performance. On the Qwen2.5-Math-7B base model, RLEP reaches baseline peak accuracy with substantially fewer updates and ultimately surpasses it, improving accuracy on AIME-2024 from 38.2% to 39.9%, on AIME-2025 from 19.8% to 22.3%, and on AMC-2023 from 77.0% to 82.2%. Our code, datasets, and checkpoints are publicly available at https://github.com/Kwai-Klear/RLEP to facilitate reproducibility and further research.
Evaluating Multimodal Large Language Models on Video Captioning via Monte Carlo Tree Search
Jun 11, 2025Video captioning can be used to assess the video understanding capabilities of Multimodal Large Language Models (MLLMs). However, existing benchmarks and evaluation protocols suffer from crucial issues, such as inadequate or homogeneous creation of key points, exorbitant cost of data creation, and limited evaluation scopes. To address these issues, we propose an automatic framework, named AutoCaption, which leverages Monte Carlo Tree Search (MCTS) to construct numerous and diverse descriptive sentences (\textit{i.e.}, key points) that thoroughly represent video content in an iterative way. This iterative captioning strategy enables the continuous enhancement of video details such as actions, objects' attributes, environment details, etc. We apply AutoCaption to curate MCTS-VCB, a fine-grained video caption benchmark covering video details, thereby enabling a comprehensive evaluation of MLLMs on the video captioning task. We evaluate more than 20 open- and closed-source MLLMs of varying sizes on MCTS-VCB. Results show that MCTS-VCB can effectively and comprehensively evaluate the video captioning capability, with Gemini-1.5-Pro achieving the highest F1 score of 71.2. Interestingly, we fine-tune InternVL2.5-8B with the AutoCaption-generated data, which helps the model achieve an overall improvement of 25.0% on MCTS-VCB and 16.3% on DREAM-1K, further demonstrating the effectiveness of AutoCaption. The code and data are available at https://github.com/tjunlp-lab/MCTS-VCB.
DynTok: Dynamic Compression of Visual Tokens for Efficient and Effective Video Understanding
Jun 04, 2025Typical video modeling methods, such as LLava, represent videos as sequences of visual tokens, which are then processed by the LLM backbone for effective video understanding. However, this approach leads to a massive number of visual tokens, especially for long videos. A practical solution is to first extract relevant visual information from the large visual context before feeding it into the LLM backbone, thereby reducing computational overhead. In this work, we introduce DynTok, a novel \textbf{Dyn}amic video \textbf{Tok}en compression strategy. DynTok adaptively splits visual tokens into groups and merges them within each group, achieving high compression in regions with low information density while preserving essential content. Our method reduces the number of tokens to 44.4% of the original size while maintaining comparable performance. It further benefits from increasing the number of video frames and achieves 65.3% on Video-MME and 72.5% on MLVU. By applying this simple yet effective compression method, we expose the redundancy in video token representations and offer insights for designing more efficient video modeling techniques.
Towards Reward Fairness in RLHF: From a Resource Allocation Perspective
May 29, 2025Rewards serve as proxies for human preferences and play a crucial role in Reinforcement Learning from Human Feedback (RLHF). However, if these rewards are inherently imperfect, exhibiting various biases, they can adversely affect the alignment of large language models (LLMs). In this paper, we collectively define the various biases present in rewards as the problem of reward unfairness. We propose a bias-agnostic method to address the issue of reward fairness from a resource allocation perspective, without specifically designing for each type of bias, yet effectively mitigating them. Specifically, we model preference learning as a resource allocation problem, treating rewards as resources to be allocated while considering the trade-off between utility and fairness in their distribution. We propose two methods, Fairness Regularization and Fairness Coefficient, to achieve fairness in rewards. We apply our methods in both verification and reinforcement learning scenarios to obtain a fairness reward model and a policy model, respectively. Experiments conducted in these scenarios demonstrate that our approach aligns LLMs with human preferences in a more fair manner.
What Makes a Good Reasoning Chain? Uncovering Structural Patterns in Long Chain-of-Thought Reasoning
May 28, 2025



Recent advances in reasoning with large language models (LLMs) have popularized Long Chain-of-Thought (LCoT), a strategy that encourages deliberate and step-by-step reasoning before producing a final answer. While LCoTs have enabled expert-level performance in complex tasks, how the internal structures of their reasoning chains drive, or even predict, the correctness of final answers remains a critical yet underexplored question. In this work, we present LCoT2Tree, an automated framework that converts sequential LCoTs into hierarchical tree structures and thus enables deeper structural analysis of LLM reasoning. Using graph neural networks (GNNs), we reveal that structural patterns extracted by LCoT2Tree, including exploration, backtracking, and verification, serve as stronger predictors of final performance across a wide range of tasks and models. Leveraging an explainability technique, we further identify critical thought patterns such as over-branching that account for failures. Beyond diagnostic insights, the structural patterns by LCoT2Tree support practical applications, including improving Best-of-N decoding effectiveness. Overall, our results underscore the critical role of internal structures of reasoning chains, positioning LCoT2Tree as a powerful tool for diagnosing, interpreting, and improving reasoning in LLMs.
Modality Curation: Building Universal Embeddings for Advanced Multimodal Information Retrieval
May 26, 2025



Multimodal information retrieval (MIR) faces inherent challenges due to the heterogeneity of data sources and the complexity of cross-modal alignment. While previous studies have identified modal gaps in feature spaces, a systematic approach to address these challenges remains unexplored. In this work, we introduce UNITE, a universal framework that tackles these challenges through two critical yet underexplored aspects: data curation and modality-aware training configurations. Our work provides the first comprehensive analysis of how modality-specific data properties influence downstream task performance across diverse scenarios. Moreover, we propose Modal-Aware Masked Contrastive Learning (MAMCL) to mitigate the competitive relationships among the instances of different modalities. Our framework achieves state-of-the-art results on multiple multimodal retrieval benchmarks, outperforming existing methods by notable margins. Through extensive experiments, we demonstrate that strategic modality curation and tailored training protocols are pivotal for robust cross-modal representation learning. This work not only advances MIR performance but also provides a foundational blueprint for future research in multimodal systems. Our project is available at https://friedrichor.github.io/projects/UNITE.