 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVistaGEN: Consistent Driving Video Generation with Fine-Grained Control Using Multiview Visual-Language Reasoning
Mar 30, 2026Driving video generation has achieved much progress in controllability, video resolution, and length, but fails to support fine-grained object-level controllability for diverse driving videos, while preserving the spatiotemporal consistency, especially in long video generation. In this paper, we present a new driving video generation technique, called VistaGEN, which enables fine-grained control of specific entities, including 3D objects, images, and text descriptions, while maintaining spatiotemporal consistency in long video sequences. Our key innovation is the incorporation of multiview visual-language reasoning into the long driving video generation. To this end, we inject visual-language features into a multiview video generator to enable fine-grained controllability. More importantly, we propose a multiview vision-language evaluator (MV-VLM) to intelligently and automatically evaluate spatiotemporal consistency of the generated content, thus formulating a novel generation-evaluation-regeneration closed-loop generation mechanism. This mechanism ensures high-quality, coherent outputs, facilitating the creation of complex and reliable driving scenarios. Besides, within the closed-loop generation, we introduce an object-level refinement module to refine the unsatisfied results evaluated from the MV-VLM and then feed them back to the video generator for regeneration. Extensive evaluation shows that our VistaGEN achieves diverse driving video generation results with fine-grained controllability, especially for long-tail objects, and much better spatiotemporal consistency than previous approaches.
Not Just What's There: Enabling CLIP to Comprehend Negated Visual Descriptions Without Fine-tuning
Feb 24, 2026Vision-Language Models (VLMs) like CLIP struggle to understand negation, often embedding affirmatives and negatives similarly (e.g., matching "no dog" with dog images). Existing methods refine negation understanding via fine-tuning CLIP's text encoder, risking overfitting. In this work, we propose CLIPGlasses, a plug-and-play framework that enhances CLIP's ability to comprehend negated visual descriptions. CLIPGlasses adopts a dual-stage design: a Lens module disentangles negated semantics from text embeddings, and a Frame module predicts context-aware repulsion strength, which is integrated into a modified similarity computation to penalize alignment with negated semantics, thereby reducing false positive matches. Experiments show that CLIP equipped with CLIPGlasses achieves competitive in-domain performance and outperforms state-of-the-art methods in cross-domain generalization. Its superiority is especially evident under low-resource conditions, indicating stronger robustness across domains.
Kelix Technical Report
Feb 12, 2026Autoregressive large language models (LLMs) scale well by expressing diverse tasks as sequences of discrete natural-language tokens and training with next-token prediction, which unifies comprehension and generation under self-supervision. Extending this paradigm to multimodal data requires a shared, discrete representation across modalities. However, most vision-language models (VLMs) still rely on a hybrid interface: discrete text tokens paired with continuous Vision Transformer (ViT) features. Because supervision is largely text-driven, these models are often biased toward understanding and cannot fully leverage large-scale self-supervised learning on non-text data. Recent work has explored discrete visual tokenization to enable fully autoregressive multimodal modeling, showing promising progress toward unified understanding and generation. Yet existing discrete vision tokens frequently lose information due to limited code capacity, resulting in noticeably weaker understanding than continuous-feature VLMs. We present Kelix, a fully discrete autoregressive unified model that closes the understanding gap between discrete and continuous visual representations.
MERGE: Next-Generation Item Indexing Paradigm for Large-Scale Streaming Recommendation
Jan 28, 2026Item indexing, which maps a large corpus of items into compact discrete representations, is critical for both discriminative and generative recommender systems, yet existing Vector Quantization (VQ)-based approaches struggle with the highly skewed and non-stationary item distributions common in streaming industry recommenders, leading to poor assignment accuracy, imbalanced cluster occupancy, and insufficient cluster separation. To address these challenges, we propose MERGE, a next-generation item indexing paradigm that adaptively constructs clusters from scratch, dynamically monitors cluster occupancy, and forms hierarchical index structures via fine-to-coarse merging. Extensive experiments demonstrate that MERGE significantly improves assignment accuracy, cluster uniformity, and cluster separation compared with existing indexing methods, while online A/B tests show substantial gains in key business metrics, highlighting its potential as a foundational indexing approach for large-scale recommendation.
A Unified Masked Jigsaw Puzzle Framework for Vision and Language Models
Jan 17, 2026In federated learning, Transformer, as a popular architecture, faces critical challenges in defending against gradient attacks and improving model performance in both Computer Vision (CV) and Natural Language Processing (NLP) tasks. It has been revealed that the gradient of Position Embeddings (PEs) in Transformer contains sufficient information, which can be used to reconstruct the input data. To mitigate this issue, we introduce a Masked Jigsaw Puzzle (MJP) framework. MJP starts with random token shuffling to break the token order, and then a learnable \textit{unknown (unk)} position embedding is used to mask out the PEs of the shuffled tokens. In this manner, the local spatial information which is encoded in the position embeddings is disrupted, and the models are forced to learn feature representations that are less reliant on the local spatial information. Notably, with the careful use of MJP, we can not only improve models' robustness against gradient attacks, but also boost their performance in both vision and text application scenarios, such as classification for images (\textit{e.g.,} ImageNet-1K) and sentiment analysis for text (\textit{e.g.,} Yelp and Amazon). Experimental results suggest that MJP is a unified framework for different Transformer-based models in both vision and language tasks. Code is publicly available via https://github.com/ywxsuperstar/transformerattack
DPWriter: Reinforcement Learning with Diverse Planning Branching for Creative Writing
Jan 14, 2026Reinforcement learning (RL)-based enhancement of large language models (LLMs) often leads to reduced output diversity, undermining their utility in open-ended tasks like creative writing. Current methods lack explicit mechanisms for guiding diverse exploration and instead prioritize optimization efficiency and performance over diversity. This paper proposes an RL framework structured around a semi-structured long Chain-of-Thought (CoT), in which the generation process is decomposed into explicitly planned intermediate steps. We introduce a Diverse Planning Branching method that strategically introduces divergence at the planning phase based on diversity variation, alongside a group-aware diversity reward to encourage distinct trajectories. Experimental results on creative writing benchmarks demonstrate that our approach significantly improves output diversity without compromising generation quality, consistently outperforming existing baselines.
Klear-AgentForge: Forging Agentic Intelligence through Posttraining Scaling
Nov 08, 2025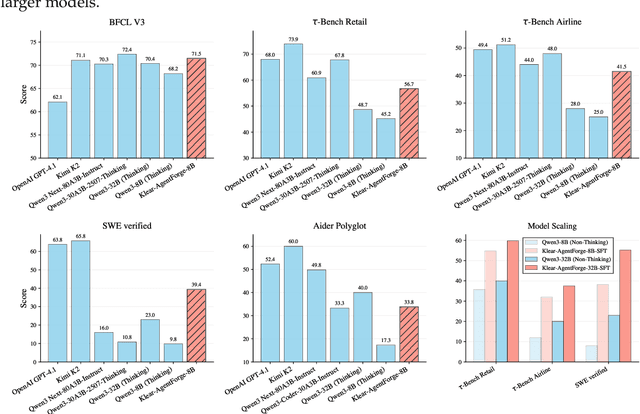
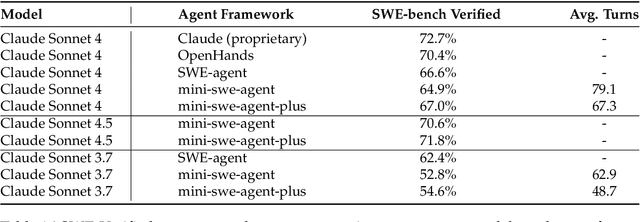
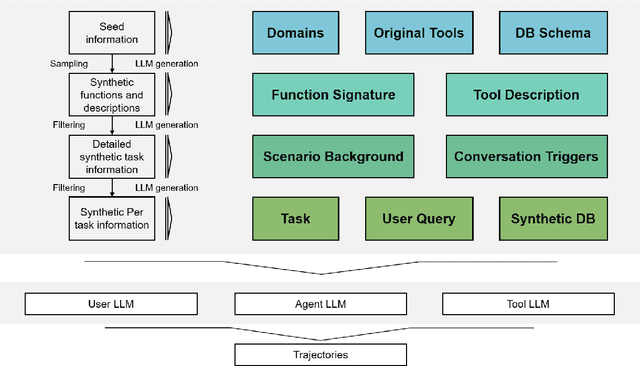
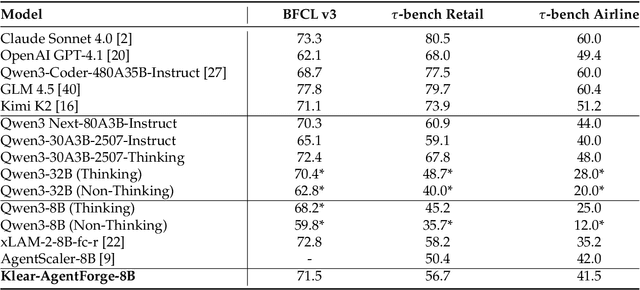
Despite the proliferation of powerful agentic models, the lack of critical post-training details hinders the development of strong counterparts in the open-source community. In this study, we present a comprehensive and fully open-source pipeline for training a high-performance agentic model for interacting with external tools and environments, named Klear-Qwen3-AgentForge, starting from the Qwen3-8B base model. We design effective supervised fine-tuning (SFT) with synthetic data followed by multi-turn reinforcement learning (RL) to unlock the potential for multiple diverse agentic tasks. We perform exclusive experiments on various agentic benchmarks in both tool use and coding domains. Klear-Qwen3-AgentForge-8B achieves state-of-the-art performance among LLMs of similar size and remains competitive with significantly larger models.
Accelerating Diffusion LLM Inference via Local Determinism Propagation
Oct 08, 2025Diffusion large language models (dLLMs) represent a significant advancement in text generation, offering parallel token decoding capabilities. However, existing open-source implementations suffer from quality-speed trade-offs that impede their practical deployment. Conservative sampling strategies typically decode only the most confident token per step to ensure quality (i.e., greedy decoding), at the cost of inference efficiency due to repeated redundant refinement iterations--a phenomenon we term delayed decoding. Through systematic analysis of dLLM decoding dynamics, we characterize this delayed decoding behavior and propose a training-free adaptive parallel decoding strategy, named LocalLeap, to address these inefficiencies. LocalLeap is built on two fundamental empirical principles: local determinism propagation centered on high-confidence anchors and progressive spatial consistency decay. By applying these principles, LocalLeap identifies anchors and performs localized relaxed parallel decoding within bounded neighborhoods, achieving substantial inference step reduction through early commitment of already-determined tokens without compromising output quality. Comprehensive evaluation on various benchmarks demonstrates that LocalLeap achieves 6.94$\times$ throughput improvements and reduces decoding steps to just 14.2\% of the original requirement, achieving these gains with negligible performance impact. The source codes are available at: https://github.com/friedrichor/LocalLeap.
The Better You Learn, The Smarter You Prune: Towards Efficient Vision-language-action Models via Differentiable Token Pruning
Sep 16, 2025We present LightVLA, a simple yet effective differentiable token pruning framework for vision-language-action (VLA) models. While VLA models have shown impressive capability in executing real-world robotic tasks, their deployment on resource-constrained platforms is often bottlenecked by the heavy attention-based computation over large sets of visual tokens. LightVLA addresses this challenge through adaptive, performance-driven pruning of visual tokens: It generates dynamic queries to evaluate visual token importance, and adopts Gumbel softmax to enable differentiable token selection. Through fine-tuning, LightVLA learns to preserve the most informative visual tokens while pruning tokens which do not contribute to task execution, thereby improving efficiency and performance simultaneously. Notably, LightVLA requires no heuristic magic numbers and introduces no additional trainable parameters, making it compatible with modern inference frameworks. Experimental results demonstrate that LightVLA outperforms different VLA models and existing token pruning methods across diverse tasks on the LIBERO benchmark, achieving higher success rates with substantially reduced computational overhead. Specifically, LightVLA reduces FLOPs and latency by 59.1% and 38.2% respectively, with a 2.9% improvement in task success rate. Meanwhile, we also investigate the learnable query-based token pruning method LightVLA* with additional trainable parameters, which also achieves satisfactory performance. Our work reveals that as VLA pursues optimal performance, LightVLA spontaneously learns to prune tokens from a performance-driven perspective. To the best of our knowledge, LightVLA is the first work to apply adaptive visual token pruning to VLA tasks with the collateral goals of efficiency and performance, marking a significant step toward more efficient, powerful and practical real-time robotic systems.
All-in-One Slider for Attribute Manipulation in Diffusion Models
Aug 26, 2025Text-to-image (T2I) diffusion models have made significant strides in generating high-quality images. However, progressively manipulating certain attributes of generated images to meet the desired user expectations remains challenging, particularly for content with rich details, such as human faces. Some studies have attempted to address this by training slider modules. However, they follow a One-for-One manner, where an independent slider is trained for each attribute, requiring additional training whenever a new attribute is introduced. This not only results in parameter redundancy accumulated by sliders but also restricts the flexibility of practical applications and the scalability of attribute manipulation. To address this issue, we introduce the All-in-One Slider, a lightweight module that decomposes the text embedding space into sparse, semantically meaningful attribute directions. Once trained, it functions as a general-purpose slider, enabling interpretable and fine-grained continuous control over various attributes. Moreover, by recombining the learned directions, the All-in-One Slider supports zero-shot manipulation of unseen attributes (e.g., races and celebrities) and the composition of multiple attributes. Extensive experiments demonstrate that our method enables accurate and scalable attribute manipulation, achieving notable improvements compared to previous methods. Furthermore, our method can be extended to integrate with the inversion framework to perform attribute manipulation on real images, broadening its applicability to various real-world scenarios. The code and trained model will be released at: https://github.com/ywxsuperstar/KSAE-FaceSteer.