 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Implicit Experience: Synthesizing Tool-Use Trajectories from Text
Jan 15, 2026Enabling Large Language Models (LLMs) to effectively utilize tools in multi-turn interactions is essential for building capable autonomous agents. However, acquiring diverse and realistic multi-turn tool-use data remains a significant challenge. In this work, we propose a novel text-based paradigm. We observe that textual corpora naturally contain rich, multi-step problem-solving experiences, which can serve as an untapped, scalable, and authentic data source for multi-turn tool-use tasks. Based on this insight, we introduce GEM, a data synthesis pipeline that enables the generation and extraction of multi-turn tool-use trajectories from text corpora through a four-stage process: relevance filtering, workflow & tool extraction, trajectory grounding, and complexity refinement. To reduce the computational cost, we further train a specialized Trajectory Synthesizer via supervised fine-tuning. This model distills the complex generation pipeline into an efficient, end-to-end trajectory generator. Experiments demonstrate that our GEM-32B achieve a 16.5% improvement on the BFCL V3 Multi-turn benchmark. Our models partially surpass the performance of models trained on τ - bench (Airline and Retail) in-domain data, highlighting the superior generalization capability derived from our text-based synthesis paradigm. Notably, our Trajectory Synthesizer matches the quality of the full pipeline while significantly reducing inference latency and costs.
DPWriter: Reinforcement Learning with Diverse Planning Branching for Creative Writing
Jan 14, 2026Reinforcement learning (RL)-based enhancement of large language models (LLMs) often leads to reduced output diversity, undermining their utility in open-ended tasks like creative writing. Current methods lack explicit mechanisms for guiding diverse exploration and instead prioritize optimization efficiency and performance over diversity. This paper proposes an RL framework structured around a semi-structured long Chain-of-Thought (CoT), in which the generation process is decomposed into explicitly planned intermediate steps. We introduce a Diverse Planning Branching method that strategically introduces divergence at the planning phase based on diversity variation, alongside a group-aware diversity reward to encourage distinct trajectories. Experimental results on creative writing benchmarks demonstrate that our approach significantly improves output diversity without compromising generation quality, consistently outperforming existing baselines.
Select, Read, and Write: A Multi-Agent Framework of Full-Text-based Related Work Generation
May 26, 2025Automatic related work generation (RWG) can save people's time and effort when writing a draft of related work section (RWS) for further revision. However, existing methods for RWG always suffer from shallow comprehension due to taking the limited portions of references papers as input and isolated explanation for each reference due to ineffective capturing the relationships among them. To address these issues, we focus on full-text-based RWG task and propose a novel multi-agent framework. Our framework consists of three agents: a selector that decides which section of the papers is going to read next, a reader that digests the selected section and updates a shared working memory, and a writer that generates RWS based on the final curated memory. To better capture the relationships among references, we also propose two graph-aware strategies for selector, enabling to optimize the reading order with constrains of the graph structure. Extensive experiments demonstrate that our framework consistently improves performance across three base models and various input configurations. The graph-aware selectors outperform alternative selectors, achieving state-of-the-art results. The code and data are available at https://github.com/1190200817/Full_Text_RWG.
Evaluating Text Creativity across Diverse Domains: A Dataset and Large Language Model Evaluator
May 25, 2025Creativity evaluation remains a challenging frontier for large language models (LLMs). Current evaluations heavily rely on inefficient and costly human judgments, hindering progress in enhancing machine creativity. While automated methods exist, ranging from psychological testing to heuristic- or prompting-based approaches, they often lack generalizability or alignment with human judgment. To address these issues, in this paper, we propose a novel pairwise-comparison framework for assessing textual creativity, leveraging shared contextual instructions to improve evaluation consistency. We introduce CreataSet, a large-scale dataset with 100K+ human-level and 1M+ synthetic creative instruction-response pairs spanning diverse open-domain tasks. Through training on CreataSet, we develop an LLM-based evaluator named CrEval. CrEval demonstrates remarkable superiority over existing methods in alignment with human judgments. Experimental results underscore the indispensable significance of integrating both human-generated and synthetic data in training highly robust evaluators, and showcase the practical utility of CrEval in boosting the creativity of LLMs. We will release all data, code, and models publicly soon to support further research.
Optimal Transport-Based Token Weighting scheme for Enhanced Preference Optimization
May 24, 2025Direct Preference Optimization (DPO) has emerged as a promising framework for aligning Large Language Models (LLMs) with human preferences by directly optimizing the log-likelihood difference between chosen and rejected responses. However, existing methods assign equal importance to all tokens in the response, while humans focus on more meaningful parts. This leads to suboptimal preference optimization, as irrelevant or noisy tokens disproportionately influence DPO loss. To address this limitation, we propose \textbf{O}ptimal \textbf{T}ransport-based token weighting scheme for enhancing direct \textbf{P}reference \textbf{O}ptimization (OTPO). By emphasizing semantically meaningful token pairs and de-emphasizing less relevant ones, our method introduces a context-aware token weighting scheme that yields a more contrastive reward difference estimate. This adaptive weighting enhances reward stability, improves interpretability, and ensures that preference optimization focuses on meaningful differences between responses. Extensive experiments have validated OTPO's effectiveness in improving instruction-following ability across various settings\footnote{Code is available at https://github.com/Mimasss2/OTPO.}.
REWARD CONSISTENCY: Improving Multi-Objective Alignment from a Data-Centric Perspective
Apr 15, 2025
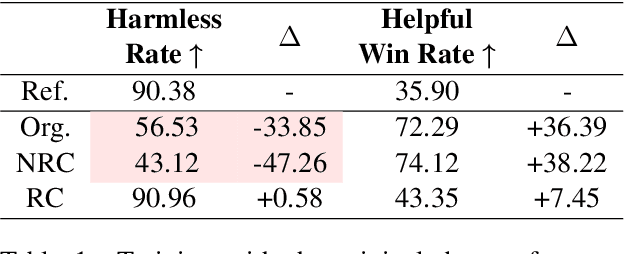


Multi-objective preference alignment in language models often encounters a challenging trade-off: optimizing for one human preference (e.g., helpfulness) frequently compromises others (e.g., harmlessness) due to the inherent conflicts between competing objectives. While prior work mainly focuses on algorithmic solutions, we explore a novel data-driven approach to uncover the types of data that can effectively mitigate these conflicts. Specifically, we propose the concept of Reward Consistency (RC), which identifies samples that align with multiple preference objectives, thereby reducing conflicts during training. Through gradient-based analysis, we demonstrate that RC-compliant samples inherently constrain performance degradation during multi-objective optimization. Building on these insights, we further develop Reward Consistency Sampling, a framework that automatically constructs preference datasets that effectively mitigate conflicts during multi-objective alignment. Our generated data achieves an average improvement of 13.37% in both the harmless rate and helpfulness win rate when optimizing harmlessness and helpfulness, and can consistently resolve conflicts in varying multi-objective scenarios.
Entropy-based Exploration Conduction for Multi-step Reasoning
Mar 20, 2025In large language model (LLM) reasoning, multi-step processes have proven effective for solving complex tasks. However, the depth of exploration can significantly affect the reasoning performance. Existing methods to automatically decide the depth often bring high costs and lack flexibility, and thus undermine the model's reasoning accuracy. To address these issues, we propose Entropy-based Exploration Depth Conduction (Entro-duction), a novel method that dynamically adjusts the exploration depth during multi-step reasoning by monitoring LLM's output entropy and variance entropy. We employ these two metrics to capture the model's current uncertainty and the fluctuation of uncertainty across consecutive reasoning steps. Based on the observed changes, the LLM selects whether to deepen, expand or stop exploration according to the probability. In this way, we balance the reasoning accuracy and exploration effectiveness. Experimental results across four benchmark datasets demonstrate the efficacy of Entro-duction. We further conduct experiments and analysis on the components of Entro-duction to discuss their contributions to reasoning performance.
Controlling Large Language Models Through Concept Activation Vectors
Jan 10, 2025



As large language models (LLMs) are widely deployed across various domains, the ability to control their generated outputs has become more critical. This control involves aligning LLMs outputs with human values and ethical principles or customizing LLMs on specific topics or styles for individual users. Existing controlled generation methods either require significant computational resources and extensive trial-and-error or provide coarse-grained control. In this paper, we propose Generation with Concept Activation Vector (GCAV), a lightweight model control framework that ensures accurate control without requiring resource-extensive fine-tuning. Specifically, GCAV first trains a concept activation vector for specified concepts to be controlled, such as toxicity. During inference, GCAV steers the concept vector in LLMs, for example, by removing the toxicity concept vector from the activation layers. Control experiments from different perspectives, including toxicity reduction, sentiment control, linguistic style, and topic control, demonstrate that our framework achieves state-of-the-art performance with granular control, allowing for fine-grained adjustments of both the steering layers and the steering magnitudes for individual samples.
Large Language Models show both individual and collective creativity comparable to humans
Dec 04, 2024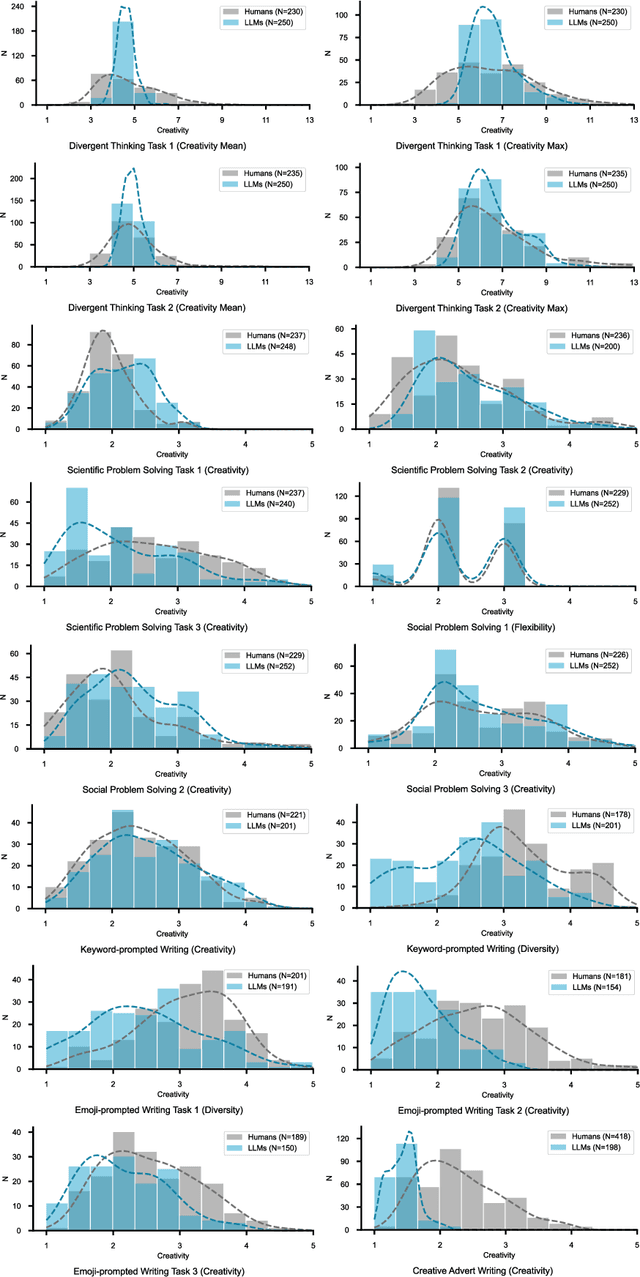
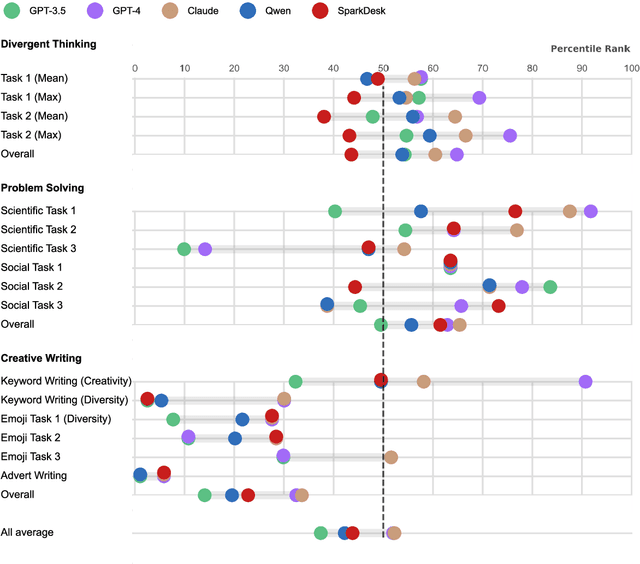
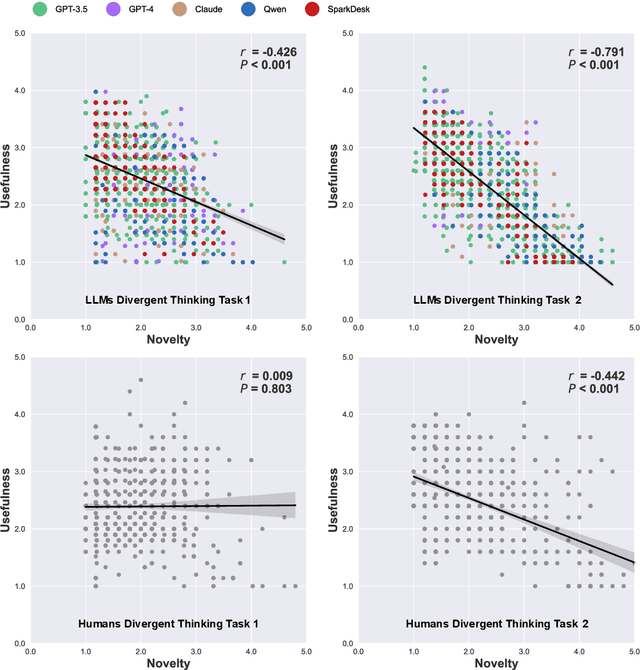
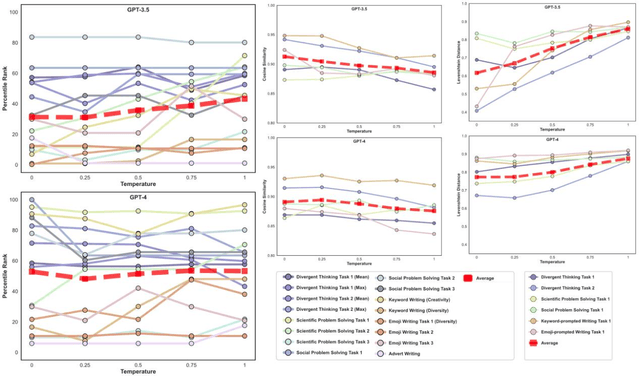
Artificial intelligence has, so far, largely automated routine tasks, but what does it mean for the future of work if Large Language Models (LLMs) show creativity comparable to humans? To measure the creativity of LLMs holistically, the current study uses 13 creative tasks spanning three domains. We benchmark the LLMs against individual humans, and also take a novel approach by comparing them to the collective creativity of groups of humans. We find that the best LLMs (Claude and GPT-4) rank in the 52nd percentile against humans, and overall LLMs excel in divergent thinking and problem solving but lag in creative writing. When questioned 10 times, an LLM's collective creativity is equivalent to 8-10 humans. When more responses are requested, two additional responses of LLMs equal one extra human. Ultimately, LLMs, when optimally applied, may compete with a small group of humans in the future of work.
Thought Space Explorer: Navigating and Expanding Thought Space for Large Language Model Reasoning
Oct 31, 2024



Recent advances in large language models (LLMs) have demonstrated their potential in handling complex reasoning tasks, which are usually achieved by constructing a thought chain to guide the model to solve the problem with multi-step thinking. However, existing methods often remain confined to previously explored solution spaces and thus overlook the critical blind spot within LLMs' cognitive range. To address these issues, we design the Thought Space Explorer (TSE), a novel framework to expand and optimize thought structures to guide LLMs to explore their blind spots of thinking. By generating new reasoning steps and branches based on the original thought structure with various designed strategies, TSE broadens the thought space and alleviates the impact of blind spots for LLM reasoning. Experimental results on multiple levels of reasoning tasks demonstrate the efficacy of TSE. We also conduct extensive analysis to understand how structured and expansive thought can contribute to unleashing the potential of LLM reasoning capabilities.