 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive or Lie: Action-Aware Capsule Multiple Instance Learning for Risk Assessment in Live Streaming Platforms
Feb 03, 2026Live streaming has become a cornerstone of today's internet, enabling massive real-time social interactions. However, it faces severe risks arising from sparse, coordinated malicious behaviors among multiple participants, which are often concealed within normal activities and challenging to detect timely and accurately. In this work, we provide a pioneering study on risk assessment in live streaming rooms, characterized by weak supervision where only room-level labels are available. We formulate the task as a Multiple Instance Learning (MIL) problem, treating each room as a bag and defining structured user-timeslot capsules as instances. These capsules represent subsequences of user actions within specific time windows, encapsulating localized behavioral patterns. Based on this formulation, we propose AC-MIL, an Action-aware Capsule MIL framework that models both individual behaviors and group-level coordination patterns. AC-MIL captures multi-granular semantics and behavioral cues through a serial and parallel architecture that jointly encodes temporal dynamics and cross-user dependencies. These signals are integrated for robust room-level risk prediction, while also offering interpretable evidence at the behavior segment level. Extensive experiments on large-scale industrial datasets from Douyin demonstrate that AC-MIL significantly outperforms MIL and sequential baselines, establishing new state-of-the-art performance in room-level risk assessment for live streaming. Moreover, AC-MIL provides capsule-level interpretability, enabling identification of risky behavior segments as actionable evidence for intervention. The project page is available at: https://qiaoyran.github.io/AC-MIL/.
Adaptive Dual-Weighting Framework for Federated Learning via Out-of-Distribution Detection
Feb 01, 2026Federated Learning (FL) enables collaborative model training across large-scale distributed service nodes while preserving data privacy, making it a cornerstone of intelligent service systems in edge-cloud environments. However, in real-world service-oriented deployments, data generated by heterogeneous users, devices, and application scenarios are inherently non-IID. This severe data heterogeneity critically undermines the convergence stability, generalization ability, and ultimately the quality of service delivered by the global model. To address this challenge, we propose FLood, a novel FL framework inspired by out-of-distribution (OOD) detection. FLood dynamically counteracts the adverse effects of heterogeneity through a dual-weighting mechanism that jointly governs local training and global aggregation. At the client level, it adaptively reweights the supervised loss by upweighting pseudo-OOD samples, thereby encouraging more robust learning from distributionally misaligned or challenging data. At the server level, it refines model aggregation by weighting client contributions according to their OOD confidence scores, prioritizing updates from clients with higher in-distribution consistency and enhancing the global model's robustness and convergence stability. Extensive experiments across multiple benchmarks under diverse non-IID settings demonstrate that FLood consistently outperforms state-of-the-art FL methods in both accuracy and generalization. Furthermore, FLood functions as an orthogonal plug-in module: it seamlessly integrates with existing FL algorithms to boost their performance under heterogeneity without modifying their core optimization logic. These properties make FLood a practical and scalable solution for deploying reliable intelligent services in real-world federated environments.
GDCNet: Generative Discrepancy Comparison Network for Multimodal Sarcasm Detection
Jan 28, 2026Multimodal sarcasm detection (MSD) aims to identify sarcasm within image-text pairs by modeling semantic incongruities across modalities. Existing methods often exploit cross-modal embedding misalignment to detect inconsistency but struggle when visual and textual content are loosely related or semantically indirect. While recent approaches leverage large language models (LLMs) to generate sarcastic cues, the inherent diversity and subjectivity of these generations often introduce noise. To address these limitations, we propose the Generative Discrepancy Comparison Network (GDCNet). This framework captures cross-modal conflicts by utilizing descriptive, factually grounded image captions generated by Multimodal LLMs (MLLMs) as stable semantic anchors. Specifically, GDCNet computes semantic and sentiment discrepancies between the generated objective description and the original text, alongside measuring visual-textual fidelity. These discrepancy features are then fused with visual and textual representations via a gated module to adaptively balance modality contributions. Extensive experiments on MSD benchmarks demonstrate GDCNet's superior accuracy and robustness, establishing a new state-of-the-art on the MMSD2.0 benchmark.
Deja Vu in Plots: Leveraging Cross-Session Evidence with Retrieval-Augmented LLMs for Live Streaming Risk Assessment
Jan 22, 2026The rise of live streaming has transformed online interaction, enabling massive real-time engagement but also exposing platforms to complex risks such as scams and coordinated malicious behaviors. Detecting these risks is challenging because harmful actions often accumulate gradually and recur across seemingly unrelated streams. To address this, we propose CS-VAR (Cross-Session Evidence-Aware Retrieval-Augmented Detector) for live streaming risk assessment. In CS-VAR, a lightweight, domain-specific model performs fast session-level risk inference, guided during training by a Large Language Model (LLM) that reasons over retrieved cross-session behavioral evidence and transfers its local-to-global insights to the small model. This design enables the small model to recognize recurring patterns across streams, perform structured risk assessment, and maintain efficiency for real-time deployment. Extensive offline experiments on large-scale industrial datasets, combined with online validation, demonstrate the state-of-the-art performance of CS-VAR. Furthermore, CS-VAR provides interpretable, localized signals that effectively empower real-world moderation for live streaming.
Improved Personalized Headline Generation via Denoising Fake Interests from Implicit Feedback
Aug 10, 2025Accurate personalized headline generation hinges on precisely capturing user interests from historical behaviors. However, existing methods neglect personalized-irrelevant click noise in entire historical clickstreams, which may lead to hallucinated headlines that deviate from genuine user preferences. In this paper, we reveal the detrimental impact of click noise on personalized generation quality through rigorous analysis in both user and news dimensions. Based on these insights, we propose a novel Personalized Headline Generation framework via Denoising Fake Interests from Implicit Feedback (PHG-DIF). PHG-DIF first employs dual-stage filtering to effectively remove clickstream noise, identified by short dwell times and abnormal click bursts, and then leverages multi-level temporal fusion to dynamically model users' evolving and multi-faceted interests for precise profiling. Moreover, we release DT-PENS, a new benchmark dataset comprising the click behavior of 1,000 carefully curated users and nearly 10,000 annotated personalized headlines with historical dwell time annotations. Extensive experiments demonstrate that PHG-DIF substantially mitigates the adverse effects of click noise and significantly improves headline quality, achieving state-of-the-art (SOTA) results on DT-PENS. Our framework implementation and dataset are available at https://github.com/liukejin-up/PHG-DIF.
* Accepted by the 34th ACM International Conference on Information and Knowledge Management (CIKM '25), Full Research Papers track
Gradient-Adaptive Policy Optimization: Towards Multi-Objective Alignment of Large Language Models
Jul 02, 2025Reinforcement Learning from Human Feedback (RLHF) has emerged as a powerful technique for aligning large language models (LLMs) with human preferences. However, effectively aligning LLMs with diverse human preferences remains a significant challenge, particularly when they are conflict. To address this issue, we frame human value alignment as a multi-objective optimization problem, aiming to maximize a set of potentially conflicting objectives. We introduce Gradient-Adaptive Policy Optimization (GAPO), a novel fine-tuning paradigm that employs multiple-gradient descent to align LLMs with diverse preference distributions. GAPO adaptively rescales the gradients for each objective to determine an update direction that optimally balances the trade-offs between objectives. Additionally, we introduce P-GAPO, which incorporates user preferences across different objectives and achieves Pareto solutions that better align with the user's specific needs. Our theoretical analysis demonstrates that GAPO converges towards a Pareto optimal solution for multiple objectives. Empirical results on Mistral-7B show that GAPO outperforms current state-of-the-art methods, achieving superior performance in both helpfulness and harmlessness.
Fact-Preserved Personalized News Headline Generation
Jan 21, 2025Personalized news headline generation, aiming at generating user-specific headlines based on readers' preferences, burgeons a recent flourishing research direction. Existing studies generally inject a user interest embedding into an encoderdecoder headline generator to make the output personalized, while the factual consistency of headlines is inadequate to be verified. In this paper, we propose a framework Fact-Preserved Personalized News Headline Generation (short for FPG), to prompt a tradeoff between personalization and consistency. In FPG, the similarity between the candidate news to be exposed and the historical clicked news is used to give different levels of attention to key facts in the candidate news, and the similarity scores help to learn a fact-aware global user embedding. Besides, an additional training procedure based on contrastive learning is devised to further enhance the factual consistency of generated headlines. Extensive experiments conducted on a real-world benchmark PENS validate the superiority of FPG, especially on the tradeoff between personalization and factual consistency.
* Accepted by IEEE ICDM 2023, Short paper, 6 pages
Panoramic Interests: Stylistic-Content Aware Personalized Headline Generation
Jan 21, 2025Personalized news headline generation aims to provide users with attention-grabbing headlines that are tailored to their preferences. Prevailing methods focus on user-oriented content preferences, but most of them overlook the fact that diverse stylistic preferences are integral to users' panoramic interests, leading to suboptimal personalization. In view of this, we propose a novel Stylistic-Content Aware Personalized Headline Generation (SCAPE) framework. SCAPE extracts both content and stylistic features from headlines with the aid of large language model (LLM) collaboration. It further adaptively integrates users' long- and short-term interests through a contrastive learning-based hierarchical fusion network. By incorporating the panoramic interests into the headline generator, SCAPE reflects users' stylistic-content preferences during the generation process. Extensive experiments on the real-world dataset PENS demonstrate the superiority of SCAPE over baselines.
Controlling Large Language Models Through Concept Activation Vectors
Jan 10, 2025



As large language models (LLMs) are widely deployed across various domains, the ability to control their generated outputs has become more critical. This control involves aligning LLMs outputs with human values and ethical principles or customizing LLMs on specific topics or styles for individual users. Existing controlled generation methods either require significant computational resources and extensive trial-and-error or provide coarse-grained control. In this paper, we propose Generation with Concept Activation Vector (GCAV), a lightweight model control framework that ensures accurate control without requiring resource-extensive fine-tuning. Specifically, GCAV first trains a concept activation vector for specified concepts to be controlled, such as toxicity. During inference, GCAV steers the concept vector in LLMs, for example, by removing the toxicity concept vector from the activation layers. Control experiments from different perspectives, including toxicity reduction, sentiment control, linguistic style, and topic control, demonstrate that our framework achieves state-of-the-art performance with granular control, allowing for fine-grained adjustments of both the steering layers and the steering magnitudes for individual samples.
Financial Risk Assessment via Long-term Payment Behavior Sequence Folding
Nov 22, 2024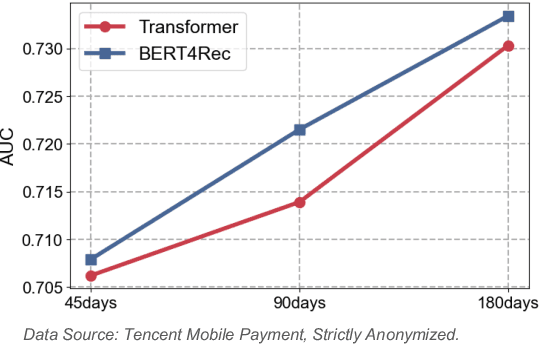
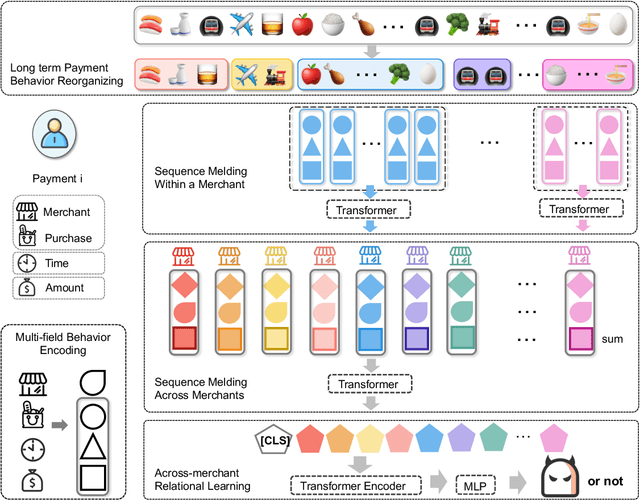
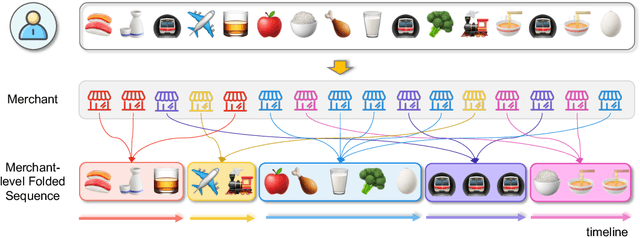
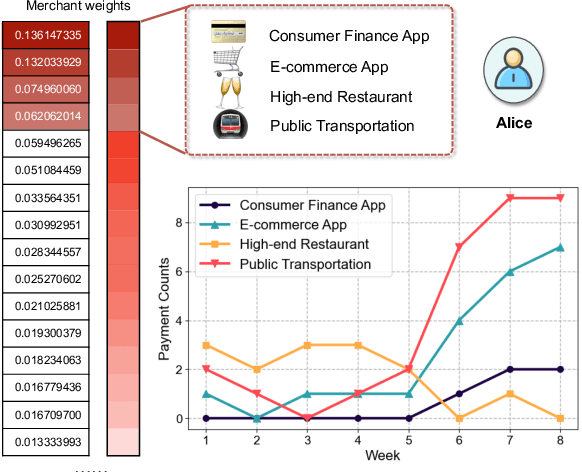
Online inclusive financial services encounter significant financial risks due to their expansive user base and low default costs. By real-world practice, we reveal that utilizing longer-term user payment behaviors can enhance models' ability to forecast financial risks. However, learning long behavior sequences is non-trivial for deep sequential models. Additionally, the diverse fields of payment behaviors carry rich information, requiring thorough exploitation. These factors collectively complicate the task of long-term user behavior modeling. To tackle these challenges, we propose a Long-term Payment Behavior Sequence Folding method, referred to as LBSF. In LBSF, payment behavior sequences are folded based on merchants, using the merchant field as an intrinsic grouping criterion, which enables informative parallelism without reliance on external knowledge. Meanwhile, we maximize the utility of payment details through a multi-field behavior encoding mechanism. Subsequently, behavior aggregation at the merchant level followed by relational learning across merchants facilitates comprehensive user financial representation. We evaluate LBSF on the financial risk assessment task using a large-scale real-world dataset. The results demonstrate that folding long behavior sequences based on internal behavioral cues effectively models long-term patterns and changes, thereby generating more accurate user financial profiles for practical applications.