 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR$^2$PO: Decoupling Training Trajectories from Inference Responses for LLM Reasoning
Jan 17, 2026Reinforcement learning has become a central paradigm for improving LLM reasoning. However, existing methods use a single policy to produce both inference responses and training optimization trajectories. The objective conflict between generating stable inference responses and diverse training trajectories leads to insufficient exploration, which harms reasoning capability. In this paper, to address the problem, we propose R$^2$PO (Residual Rollout Policy Optimization), which introduces a lightweight Residual Rollout-Head atop the policy to decouple training trajectories from inference responses, enabling controlled trajectory diversification during training while keeping inference generation stable. Experiments across multiple benchmarks show that our method consistently outperforms baselines, achieving average accuracy gains of 3.1% on MATH-500 and 2.4% on APPS, while also reducing formatting errors and mitigating length bias for stable optimization. Our code is publicly available at https://github.com/RRPO-ARR/Code.
LOGIN: A Large Language Model Consulted Graph Neural Network Training Framework
May 22, 2024



Recent prevailing works on graph machine learning typically follow a similar methodology that involves designing advanced variants of graph neural networks (GNNs) to maintain the superior performance of GNNs on different graphs. In this paper, we aim to streamline the GNN design process and leverage the advantages of Large Language Models (LLMs) to improve the performance of GNNs on downstream tasks. We formulate a new paradigm, coined "LLMs-as-Consultants," which integrates LLMs with GNNs in an interactive manner. A framework named LOGIN (LLM Consulted GNN training) is instantiated, empowering the interactive utilization of LLMs within the GNN training process. First, we attentively craft concise prompts for spotted nodes, carrying comprehensive semantic and topological information, and serving as input to LLMs. Second, we refine GNNs by devising a complementary coping mechanism that utilizes the responses from LLMs, depending on their correctness. We empirically evaluate the effectiveness of LOGIN on node classification tasks across both homophilic and heterophilic graphs. The results illustrate that even basic GNN architectures, when employed within the proposed LLMs-as-Consultants paradigm, can achieve comparable performance to advanced GNNs with intricate designs. Our codes are available at https://github.com/QiaoYRan/LOGIN.
Bridged-GNN: Knowledge Bridge Learning for Effective Knowledge Transfer
Aug 18, 2023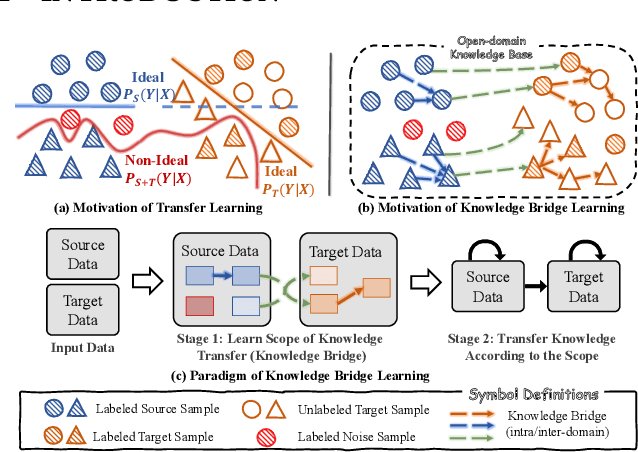



The data-hungry problem, characterized by insufficiency and low-quality of data, poses obstacles for deep learning models. Transfer learning has been a feasible way to transfer knowledge from high-quality external data of source domains to limited data of target domains, which follows a domain-level knowledge transfer to learn a shared posterior distribution. However, they are usually built on strong assumptions, e.g., the domain invariant posterior distribution, which is usually unsatisfied and may introduce noises, resulting in poor generalization ability on target domains. Inspired by Graph Neural Networks (GNNs) that aggregate information from neighboring nodes, we redefine the paradigm as learning a knowledge-enhanced posterior distribution for target domains, namely Knowledge Bridge Learning (KBL). KBL first learns the scope of knowledge transfer by constructing a Bridged-Graph that connects knowledgeable samples to each target sample and then performs sample-wise knowledge transfer via GNNs.KBL is free from strong assumptions and is robust to noises in the source data. Guided by KBL, we propose the Bridged-GNN} including an Adaptive Knowledge Retrieval module to build Bridged-Graph and a Graph Knowledge Transfer module. Comprehensive experiments on both un-relational and relational data-hungry scenarios demonstrate the significant improvements of Bridged-GNN compared with SOTA methods
Predicting the Silent Majority on Graphs: Knowledge Transferable Graph Neural Network
Feb 02, 2023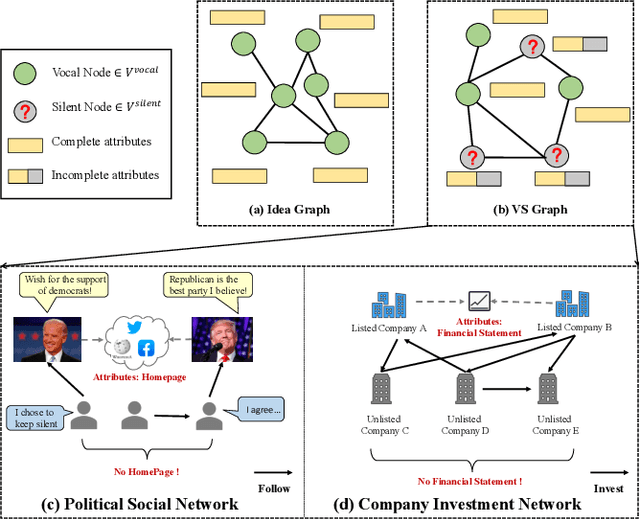

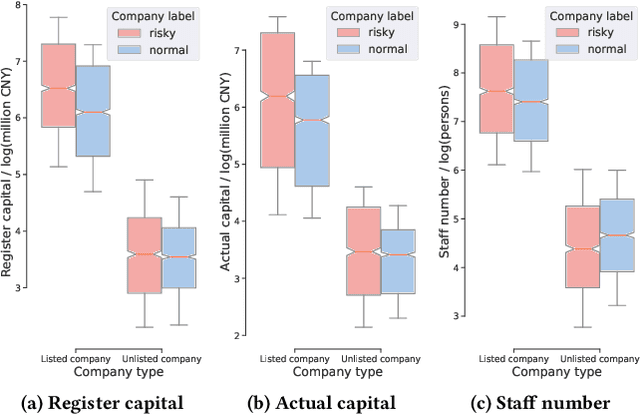
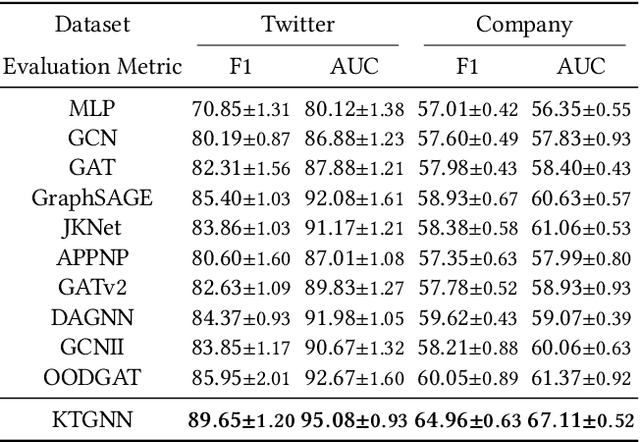
Graphs consisting of vocal nodes ("the vocal minority") and silent nodes ("the silent majority"), namely VS-Graph, are ubiquitous in the real world. The vocal nodes tend to have abundant features and labels. In contrast, silent nodes only have incomplete features and rare labels, e.g., the description and political tendency of politicians (vocal) are abundant while not for ordinary people (silent) on the twitter's social network. Predicting the silent majority remains a crucial yet challenging problem. However, most existing message-passing based GNNs assume that all nodes belong to the same domain, without considering the missing features and distribution-shift between domains, leading to poor ability to deal with VS-Graph. To combat the above challenges, we propose Knowledge Transferable Graph Neural Network (KT-GNN), which models distribution shifts during message passing and representation learning by transferring knowledge from vocal nodes to silent nodes. Specifically, we design the domain-adapted "feature completion and message passing mechanism" for node representation learning while preserving domain difference. And a knowledge transferable classifier based on KL-divergence is followed. Comprehensive experiments on real-world scenarios (i.e., company financial risk assessment and political elections) demonstrate the superior performance of our method. Our source code has been open sourced.
Company-as-Tribe: Company Financial Risk Assessment on Tribe-Style Graph with Hierarchical Graph Neural Networks
Jan 31, 2023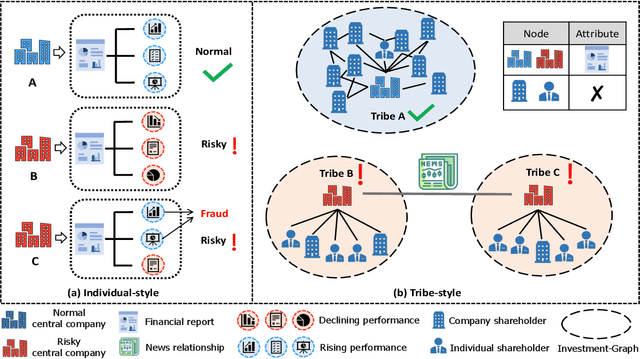
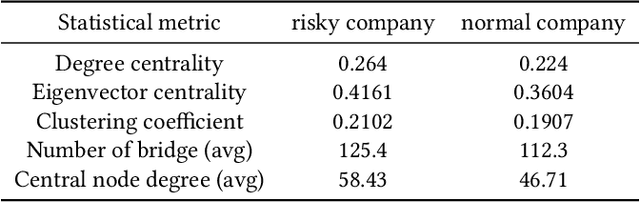
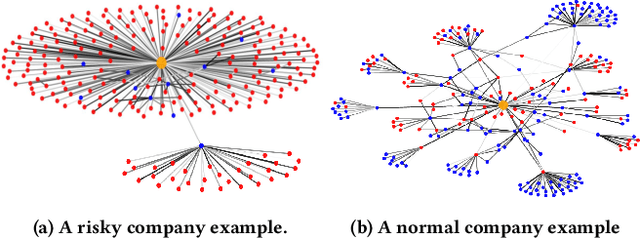

Company financial risk is ubiquitous and early risk assessment for listed companies can avoid considerable losses. Traditional methods mainly focus on the financial statements of companies and lack the complex relationships among them. However, the financial statements are often biased and lagged, making it difficult to identify risks accurately and timely. To address the challenges, we redefine the problem as \textbf{company financial risk assessment on tribe-style graph} by taking each listed company and its shareholders as a tribe and leveraging financial news to build inter-tribe connections. Such tribe-style graphs present different patterns to distinguish risky companies from normal ones. However, most nodes in the tribe-style graph lack attributes, making it difficult to directly adopt existing graph learning methods (e.g., Graph Neural Networks(GNNs)). In this paper, we propose a novel Hierarchical Graph Neural Network (TH-GNN) for Tribe-style graphs via two levels, with the first level to encode the structure pattern of the tribes with contrastive learning, and the second level to diffuse information based on the inter-tribe relations, achieving effective and efficient risk assessment. Extensive experiments on the real-world company dataset show that our method achieves significant improvements on financial risk assessment over previous competing methods. Also, the extensive ablation studies and visualization comprehensively show the effectiveness of our method.