 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree of Preferences for Diversified Recommendation
Dec 24, 2025Diversified recommendation has attracted increasing attention from both researchers and practitioners, which can effectively address the homogeneity of recommended items. Existing approaches predominantly aim to infer the diversity of user preferences from observed user feedback. Nonetheless, due to inherent data biases, the observed data may not fully reflect user interests, where underexplored preferences can be overwhelmed or remain unmanifested. Failing to capture these preferences can lead to suboptimal diversity in recommendations. To fill this gap, this work aims to study diversified recommendation from a data-bias perspective. Inspired by the outstanding performance of large language models (LLMs) in zero-shot inference leveraging world knowledge, we propose a novel approach that utilizes LLMs' expertise to uncover underexplored user preferences from observed behavior, ultimately providing diverse and relevant recommendations. To achieve this, we first introduce Tree of Preferences (ToP), an innovative structure constructed to model user preferences from coarse to fine. ToP enables LLMs to systematically reason over the user's rationale behind their behavior, thereby uncovering their underexplored preferences. To guide diversified recommendations using uncovered preferences, we adopt a data-centric approach, identifying candidate items that match user preferences and generating synthetic interactions that reflect underexplored preferences. These interactions are integrated to train a general recommender for diversification. Moreover, we scale up overall efficiency by dynamically selecting influential users during optimization. Extensive evaluations of both diversity and relevance show that our approach outperforms existing methods in most cases and achieves near-optimal performance in others, with reasonable inference latency.
How to Use Graph Data in the Wild to Help Graph Anomaly Detection?
Jun 04, 2025In recent years, graph anomaly detection has found extensive applications in various domains such as social, financial, and communication networks. However, anomalies in graph-structured data present unique challenges, including label scarcity, ill-defined anomalies, and varying anomaly types, making supervised or semi-supervised methods unreliable. Researchers often adopt unsupervised approaches to address these challenges, assuming that anomalies deviate significantly from the normal data distribution. Yet, when the available data is insufficient, capturing the normal distribution accurately and comprehensively becomes difficult. To overcome this limitation, we propose to utilize external graph data (i.e., graph data in the wild) to help anomaly detection tasks. This naturally raises the question: How can we use external data to help graph anomaly detection tasks? To answer this question, we propose a framework called Wild-GAD. It is built upon a unified database, UniWildGraph, which comprises a large and diverse collection of graph data with broad domain coverage, ample data volume, and a unified feature space. Further, we develop selection criteria based on representativity and diversity to identify the most suitable external data for anomaly detection task. Extensive experiments on six real-world datasets demonstrate the effectiveness of Wild-GAD. Compared to the baseline methods, our framework has an average 18% AUCROC and 32% AUCPR improvement over the best-competing methods.
An Empirical Study of Many-to-Many Summarization with Large Language Models
May 19, 2025
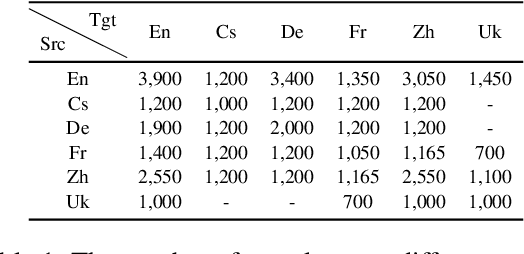
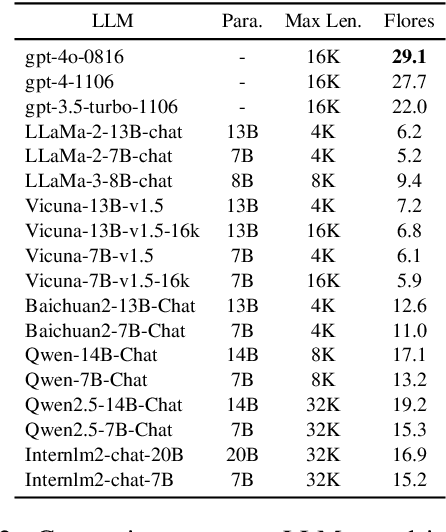
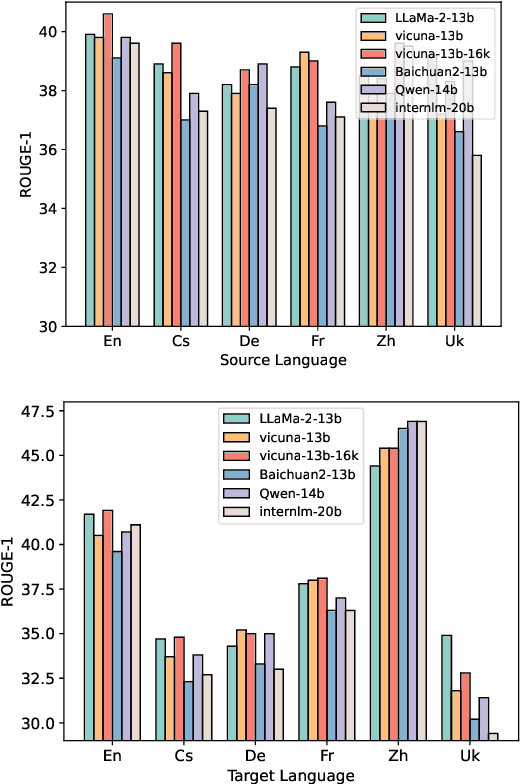
Many-to-many summarization (M2MS) aims to process documents in any language and generate the corresponding summaries also in any language. Recently, large language models (LLMs) have shown strong multi-lingual abilities, giving them the potential to perform M2MS in real applications. This work presents a systematic empirical study on LLMs' M2MS ability. Specifically, we first reorganize M2MS data based on eight previous domain-specific datasets. The reorganized data contains 47.8K samples spanning five domains and six languages, which could be used to train and evaluate LLMs. Then, we benchmark 18 LLMs in a zero-shot manner and an instruction-tuning manner. Fine-tuned traditional models (e.g., mBART) are also conducted for comparisons. Our experiments reveal that, zero-shot LLMs achieve competitive results with fine-tuned traditional models. After instruct-tuning, open-source LLMs can significantly improve their M2MS ability, and outperform zero-shot LLMs (including GPT-4) in terms of automatic evaluations. In addition, we demonstrate that this task-specific improvement does not sacrifice the LLMs' general task-solving abilities. However, as revealed by our human evaluation, LLMs still face the factuality issue, and the instruction tuning might intensify the issue. Thus, how to control factual errors becomes the key when building LLM summarizers in real applications, and is worth noting in future research.
Rethinking Time Encoding via Learnable Transformation Functions
May 01, 2025Effectively modeling time information and incorporating it into applications or models involving chronologically occurring events is crucial. Real-world scenarios often involve diverse and complex time patterns, which pose significant challenges for time encoding methods. While previous methods focus on capturing time patterns, many rely on specific inductive biases, such as using trigonometric functions to model periodicity. This narrow focus on single-pattern modeling makes them less effective in handling the diversity and complexities of real-world time patterns. In this paper, we investigate to improve the existing commonly used time encoding methods and introduce Learnable Transformation-based Generalized Time Encoding (LeTE). We propose using deep function learning techniques to parameterize non-linear transformations in time encoding, making them learnable and capable of modeling generalized time patterns, including diverse and complex temporal dynamics. By enabling learnable transformations, LeTE encompasses previous methods as specific cases and allows seamless integration into a wide range of tasks. Through extensive experiments across diverse domains, we demonstrate the versatility and effectiveness of LeTE.
Unifying Text Semantics and Graph Structures for Temporal Text-attributed Graphs with Large Language Models
Mar 18, 2025Temporal graph neural networks (TGNNs) have shown remarkable performance in temporal graph modeling. However, real-world temporal graphs often possess rich textual information, giving rise to temporal text-attributed graphs (TTAGs). Such combination of dynamic text semantics and evolving graph structures introduces heightened complexity. Existing TGNNs embed texts statically and rely heavily on encoding mechanisms that biasedly prioritize structural information, overlooking the temporal evolution of text semantics and the essential interplay between semantics and structures for synergistic reinforcement. To tackle these issues, we present \textbf{{Cross}}, a novel framework that seamlessly extends existing TGNNs for TTAG modeling. The key idea is to employ the advanced large language models (LLMs) to extract the dynamic semantics in text space and then generate expressive representations unifying both semantics and structures. Specifically, we propose a Temporal Semantics Extractor in the {Cross} framework, which empowers the LLM to offer the temporal semantic understanding of node's evolving contexts of textual neighborhoods, facilitating semantic dynamics. Subsequently, we introduce the Semantic-structural Co-encoder, which collaborates with the above Extractor for synthesizing illuminating representations by jointly considering both semantic and structural information while encouraging their mutual reinforcement. Extensive experimental results on four public datasets and one practical industrial dataset demonstrate {Cross}'s significant effectiveness and robustness.
Boosting Diffusion-Based Text Image Super-Resolution Model Towards Generalized Real-World Scenarios
Mar 11, 2025Restoring low-resolution text images presents a significant challenge, as it requires maintaining both the fidelity and stylistic realism of the text in restored images. Existing text image restoration methods often fall short in hard situations, as the traditional super-resolution models cannot guarantee clarity, while diffusion-based methods fail to maintain fidelity. In this paper, we introduce a novel framework aimed at improving the generalization ability of diffusion models for text image super-resolution (SR), especially promoting fidelity. First, we propose a progressive data sampling strategy that incorporates diverse image types at different stages of training, stabilizing the convergence and improving the generalization. For the network architecture, we leverage a pre-trained SR prior to provide robust spatial reasoning capabilities, enhancing the model's ability to preserve textual information. Additionally, we employ a cross-attention mechanism to better integrate textual priors. To further reduce errors in textual priors, we utilize confidence scores to dynamically adjust the importance of textual features during training. Extensive experiments on real-world datasets demonstrate that our approach not only produces text images with more realistic visual appearances but also improves the accuracy of text structure.
Can Graph Neural Networks Expose Training Data Properties? An Efficient Risk Assessment Approach
Nov 06, 2024



Graph neural networks (GNNs) have attracted considerable attention due to their diverse applications. However, the scarcity and quality limitations of graph data present challenges to their training process in practical settings. To facilitate the development of effective GNNs, companies and researchers often seek external collaboration. Yet, directly sharing data raises privacy concerns, motivating data owners to train GNNs on their private graphs and share the trained models. Unfortunately, these models may still inadvertently disclose sensitive properties of their training graphs (e.g., average default rate in a transaction network), leading to severe consequences for data owners. In this work, we study graph property inference attack to identify the risk of sensitive property information leakage from shared models. Existing approaches typically train numerous shadow models for developing such attack, which is computationally intensive and impractical. To address this issue, we propose an efficient graph property inference attack by leveraging model approximation techniques. Our method only requires training a small set of models on graphs, while generating a sufficient number of approximated shadow models for attacks. To enhance diversity while reducing errors in the approximated models, we apply edit distance to quantify the diversity within a group of approximated models and introduce a theoretically guaranteed criterion to evaluate each model's error. Subsequently, we propose a novel selection mechanism to ensure that the retained approximated models achieve high diversity and low error. Extensive experiments across six real-world scenarios demonstrate our method's substantial improvement, with average increases of 2.7% in attack accuracy and 4.1% in ROC-AUC, while being 6.5$\times$ faster compared to the best baseline.
Unleashing the Power of Emojis in Texts via Self-supervised Graph Pre-Training
Sep 26, 2024
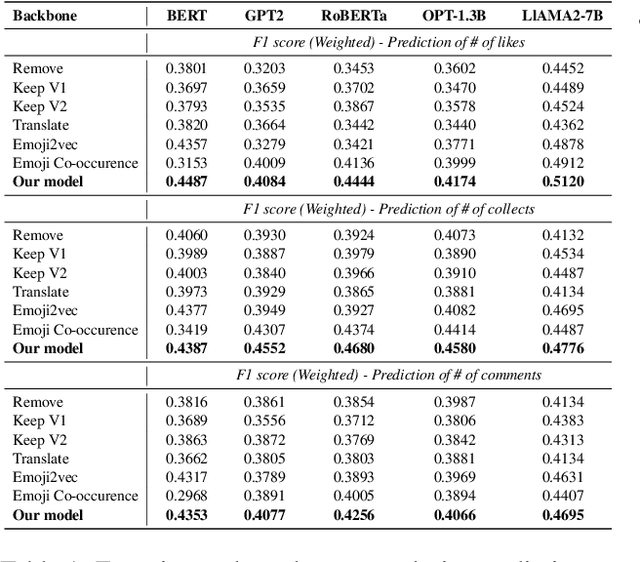
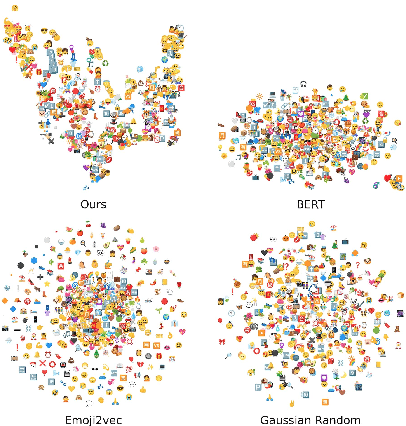
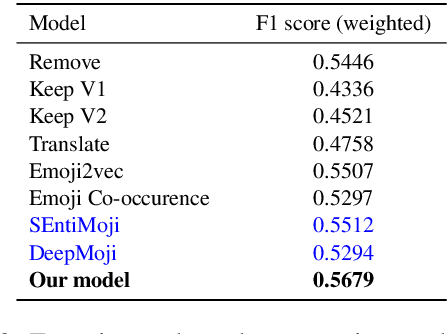
Emojis have gained immense popularity on social platforms, serving as a common means to supplement or replace text. However, existing data mining approaches generally either completely ignore or simply treat emojis as ordinary Unicode characters, which may limit the model's ability to grasp the rich semantic information in emojis and the interaction between emojis and texts. Thus, it is necessary to release the emoji's power in social media data mining. To this end, we first construct a heterogeneous graph consisting of three types of nodes, i.e. post, word and emoji nodes to improve the representation of different elements in posts. The edges are also well-defined to model how these three elements interact with each other. To facilitate the sharing of information among post, word and emoji nodes, we propose a graph pre-train framework for text and emoji co-modeling, which contains two graph pre-training tasks: node-level graph contrastive learning and edge-level link reconstruction learning. Extensive experiments on the Xiaohongshu and Twitter datasets with two types of downstream tasks demonstrate that our approach proves significant improvement over previous strong baseline methods.
Can Modifying Data Address Graph Domain Adaptation?
Jul 27, 2024



Graph neural networks (GNNs) have demonstrated remarkable success in numerous graph analytical tasks. Yet, their effectiveness is often compromised in real-world scenarios due to distribution shifts, limiting their capacity for knowledge transfer across changing environments or domains. Recently, Unsupervised Graph Domain Adaptation (UGDA) has been introduced to resolve this issue. UGDA aims to facilitate knowledge transfer from a labeled source graph to an unlabeled target graph. Current UGDA efforts primarily focus on model-centric methods, such as employing domain invariant learning strategies and designing model architectures. However, our critical examination reveals the limitations inherent to these model-centric methods, while a data-centric method allowed to modify the source graph provably demonstrates considerable potential. This insight motivates us to explore UGDA from a data-centric perspective. By revisiting the theoretical generalization bound for UGDA, we identify two data-centric principles for UGDA: alignment principle and rescaling principle. Guided by these principles, we propose GraphAlign, a novel UGDA method that generates a small yet transferable graph. By exclusively training a GNN on this new graph with classic Empirical Risk Minimization (ERM), GraphAlign attains exceptional performance on the target graph. Extensive experiments under various transfer scenarios demonstrate the GraphAlign outperforms the best baselines by an average of 2.16%, training on the generated graph as small as 0.25~1% of the original training graph.
Unveiling Privacy Vulnerabilities: Investigating the Role of Structure in Graph Data
Jul 26, 2024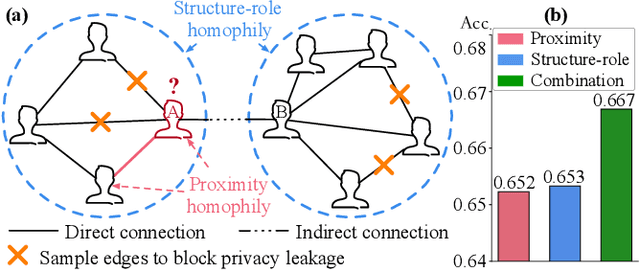
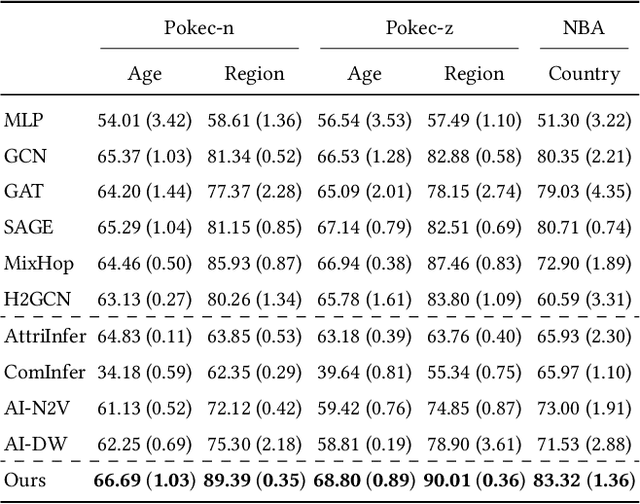
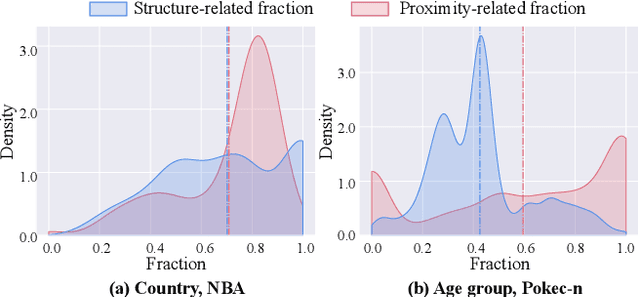
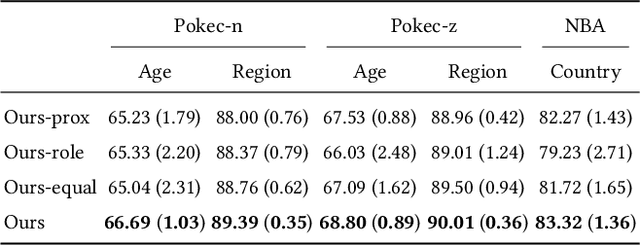
The public sharing of user information opens the door for adversaries to infer private data, leading to privacy breaches and facilitating malicious activities. While numerous studies have concentrated on privacy leakage via public user attributes, the threats associated with the exposure of user relationships, particularly through network structure, are often neglected. This study aims to fill this critical gap by advancing the understanding and protection against privacy risks emanating from network structure, moving beyond direct connections with neighbors to include the broader implications of indirect network structural patterns. To achieve this, we first investigate the problem of Graph Privacy Leakage via Structure (GPS), and introduce a novel measure, the Generalized Homophily Ratio, to quantify the various mechanisms contributing to privacy breach risks in GPS. Based on this insight, we develop a novel graph private attribute inference attack, which acts as a pivotal tool for evaluating the potential for privacy leakage through network structures under worst-case scenarios. To protect users' private data from such vulnerabilities, we propose a graph data publishing method incorporating a learnable graph sampling technique, effectively transforming the original graph into a privacy-preserving version. Extensive experiments demonstrate that our attack model poses a significant threat to user privacy, and our graph data publishing method successfully achieves the optimal privacy-utility trade-off compared to baselines.