 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCT-Eval: Benchmarking Chinese Text-to-Table Performance in Large Language Models
May 20, 2024Text-to-Table aims to generate structured tables to convey the key information from unstructured documents. Existing text-to-table datasets are typically oriented English, limiting the research in non-English languages. Meanwhile, the emergence of large language models (LLMs) has shown great success as general task solvers in multi-lingual settings (e.g., ChatGPT), theoretically enabling text-to-table in other languages. In this paper, we propose a Chinese text-to-table dataset, CT-Eval, to benchmark LLMs on this task. Our preliminary analysis of English text-to-table datasets highlights two key factors for dataset construction: data diversity and data hallucination. Inspired by this, the CT-Eval dataset selects a popular Chinese multidisciplinary online encyclopedia as the source and covers 28 domains to ensure data diversity. To minimize data hallucination, we first train an LLM to judge and filter out the task samples with hallucination, then employ human annotators to clean the hallucinations in the validation and testing sets. After this process, CT-Eval contains 88.6K task samples. Using CT-Eval, we evaluate the performance of open-source and closed-source LLMs. Our results reveal that zero-shot LLMs (including GPT-4) still have a significant performance gap compared with human judgment. Furthermore, after fine-tuning, open-source LLMs can significantly improve their text-to-table ability, outperforming GPT-4 by a large margin. In short, CT-Eval not only helps researchers evaluate and quickly understand the Chinese text-to-table ability of existing LLMs but also serves as a valuable resource to significantly improve the text-to-table performance of LLMs.
Self-supervised Document Clustering Based on BERT with Data Augment
Nov 26, 2020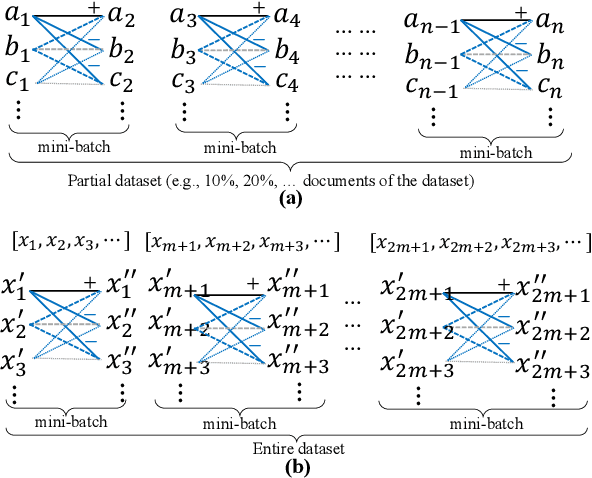
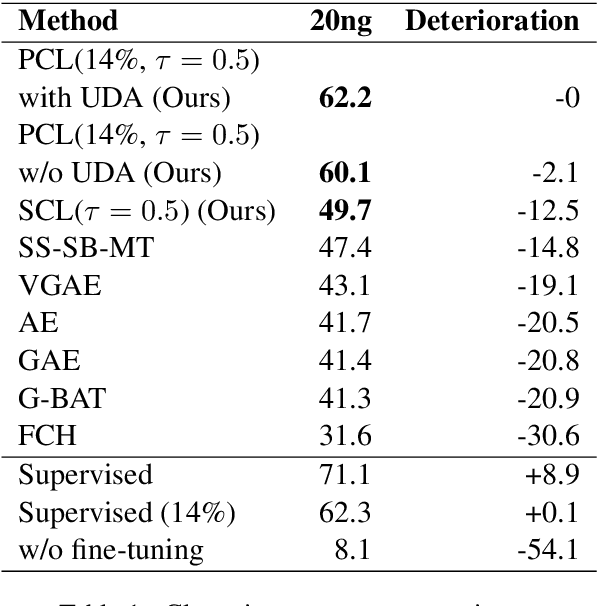
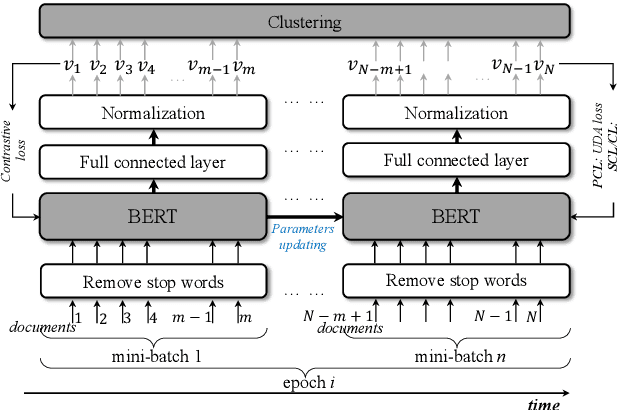

Contrastive learning is a good way to pursue discriminative unsupervised learning, which can inherit advantages and experiences of well-studied deep models without complexly novel model designing. In this paper, we propose two learning method for document clustering, the one is a partial contrastive learning with unsupervised data augment, and the other is a self-supervised contrastive learning. Both methods achieve state-of-the-art results in clustering accuracy when compared to recently proposed unsupervised clustering approaches.
Hair Segmentation on Time-of-Flight RGBD Images
Mar 11, 2019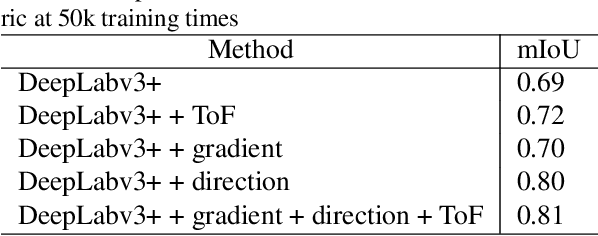
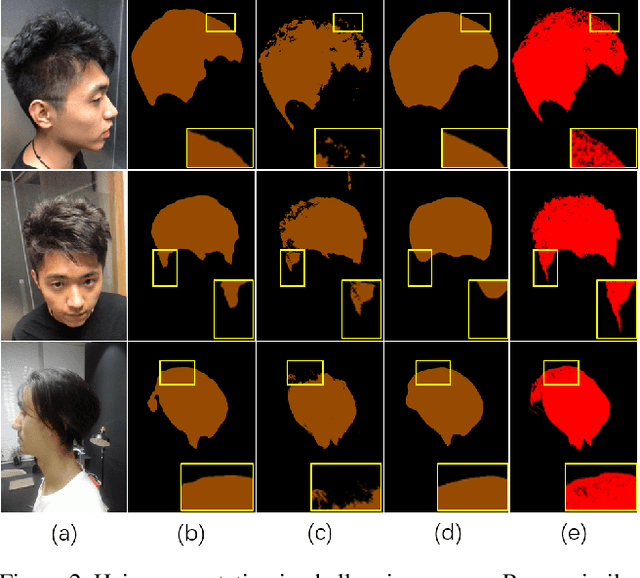
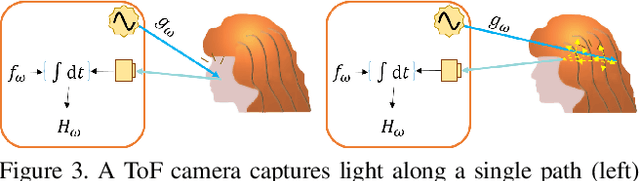
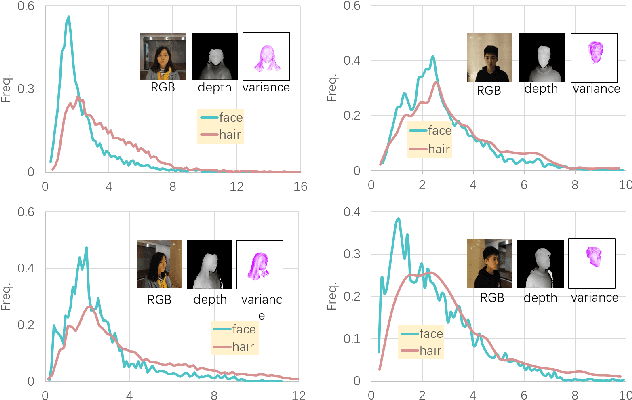
Robust segmentation of hair from portrait images remains challenging: hair does not conform to a uniform shape, style or even color; dark hair in particular lacks features. We present a novel computational imaging solution that tackles the problem from both input and processing fronts. We explore using Time-of-Flight (ToF) RGBD sensors on recent mobile devices. We first conduct a comprehensive analysis to show that scattering and inter-reflection cause different noise patterns on hair vs. non-hair regions on ToF images, by changing the light path and/or combining multiple paths. We then develop a deep network based approach that employs both ToF depth map and the RGB gradient maps to produce an initial hair segmentation with labeled hair components. We then refine the result by imposing ToF noise prior under the conditional random field. We collect the first ToF RGBD hair dataset with 20k+ head images captured on 30 human subjects with a variety of hairstyles at different view angles. Comprehensive experiments show that our approach outperforms the RGB based techniques in accuracy and robustness and can handle traditionally challenging cases such as dark hair, similar hair/background, similar hair/foreground, etc.
Sparse Photometric 3D Face Reconstruction Guided by Morphable Models
Nov 29, 2017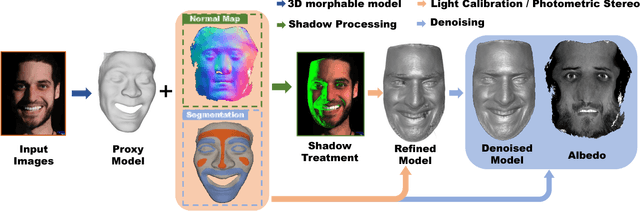
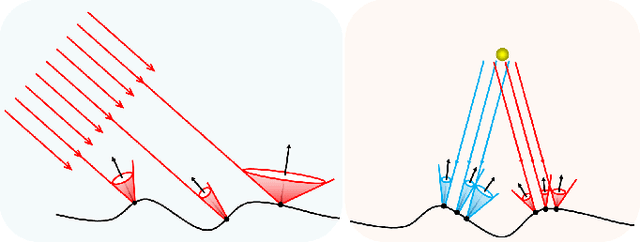
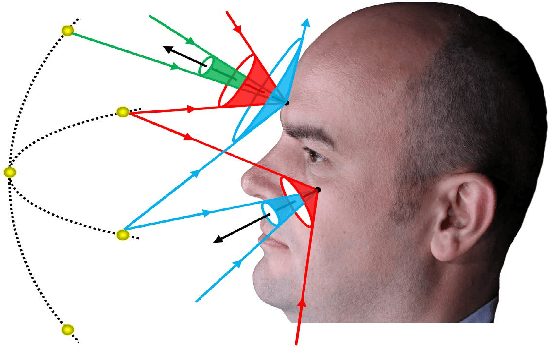

We present a novel 3D face reconstruction technique that leverages sparse photometric stereo (PS) and latest advances on face registration/modeling from a single image. We observe that 3D morphable faces approach provides a reasonable geometry proxy for light position calibration. Specifically, we develop a robust optimization technique that can calibrate per-pixel lighting direction and illumination at a very high precision without assuming uniform surface albedos. Next, we apply semantic segmentation on input images and the geometry proxy to refine hairy vs. bare skin regions using tailored filters. Experiments on synthetic and real data show that by using a very small set of images, our technique is able to reconstruct fine geometric details such as wrinkles, eyebrows, whelks, pores, etc, comparable to and sometimes surpassing movie quality productions.