 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBending the Scaling Law Curve in Large-Scale Recommendation Systems
Feb 19, 2026Learning from user interaction history through sequential models has become a cornerstone of large-scale recommender systems. Recent advances in large language models have revealed promising scaling laws, sparking a surge of research into long-sequence modeling and deeper architectures for recommendation tasks. However, many recent approaches rely heavily on cross-attention mechanisms to address the quadratic computational bottleneck in sequential modeling, which can limit the representational power gained from self-attention. We present ULTRA-HSTU, a novel sequential recommendation model developed through end-to-end model and system co-design. By innovating in the design of input sequences, sparse attention mechanisms, and model topology, ULTRA-HSTU achieves substantial improvements in both model quality and efficiency. Comprehensive benchmarking demonstrates that ULTRA-HSTU achieves remarkable scaling efficiency gains -- over 5x faster training scaling and 21x faster inference scaling compared to conventional models -- while delivering superior recommendation quality. Our solution is fully deployed at scale, serving billions of users daily and driving significant 4% to 8% consumption and engagement improvements in real-world production environments.
Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations
Feb 27, 2024



Large-scale recommendation systems are characterized by their reliance on high cardinality, heterogeneous features and the need to handle tens of billions of user actions on a daily basis. Despite being trained on huge volume of data with thousands of features, most Deep Learning Recommendation Models (DLRMs) in industry fail to scale with compute. Inspired by success achieved by Transformers in language and vision domains, we revisit fundamental design choices in recommendation systems. We reformulate recommendation problems as sequential transduction tasks within a generative modeling framework (``Generative Recommenders''), and propose a new architecture, HSTU, designed for high cardinality, non-stationary streaming recommendation data. HSTU outperforms baselines over synthetic and public datasets by up to 65.8\% in NDCG, and is 5.3x to 15.2x faster than FlashAttention2-based Transformers on 8192 length sequences. HSTU-based Generative Recommenders, with 1.5 trillion parameters, improve metrics in online A/B tests by 12.4\% and have been deployed on multiple surfaces of a large internet platform with billions of users. More importantly, the model quality of Generative Recommenders empirically scales as a power-law of training compute across three orders of magnitude, up to GPT-3/LLaMa-2 scale, which reduces carbon footprint needed for future model developments, and further paves the way for the first foundational models in recommendations.
Adversarial Refinement Network for Human Motion Prediction
Nov 24, 2020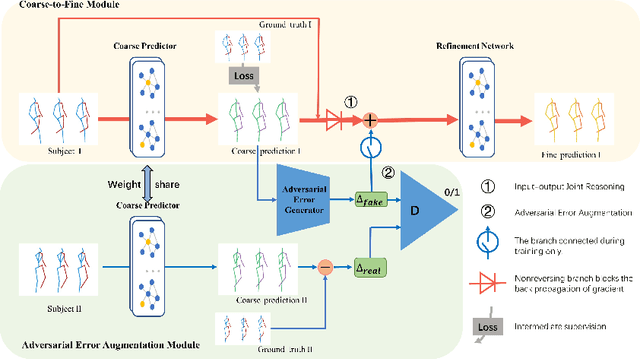
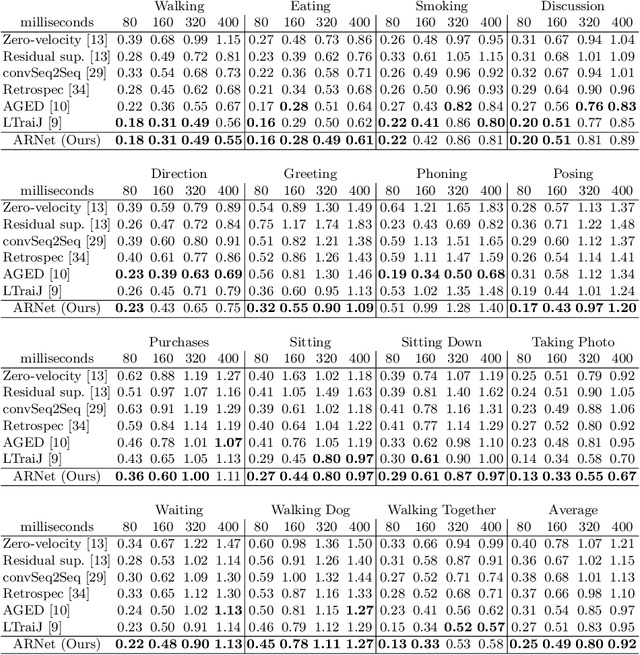
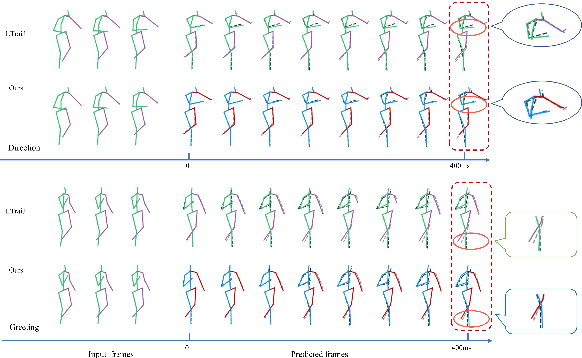
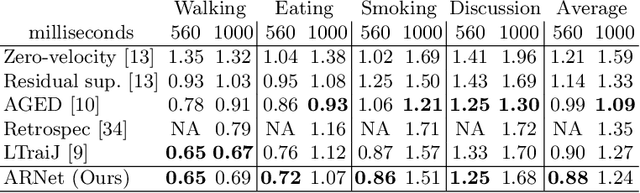
Human motion prediction aims to predict future 3D skeletal sequences by giving a limited human motion as inputs. Two popular methods, recurrent neural networks and feed-forward deep networks, are able to predict rough motion trend, but motion details such as limb movement may be lost. To predict more accurate future human motion, we propose an Adversarial Refinement Network (ARNet) following a simple yet effective coarse-to-fine mechanism with novel adversarial error augmentation. Specifically, we take both the historical motion sequences and coarse prediction as input of our cascaded refinement network to predict refined human motion and strengthen the refinement network with adversarial error augmentation. During training, we deliberately introduce the error distribution by learning through the adversarial mechanism among different subjects. In testing, our cascaded refinement network alleviates the prediction error from the coarse predictor resulting in a finer prediction robustly. This adversarial error augmentation provides rich error cases as input to our refinement network, leading to better generalization performance on the testing dataset. We conduct extensive experiments on three standard benchmark datasets and show that our proposed ARNet outperforms other state-of-the-art methods, especially on challenging aperiodic actions in both short-term and long-term predictions.
Adversarial Semantic Data Augmentation for Human Pose Estimation
Aug 03, 2020
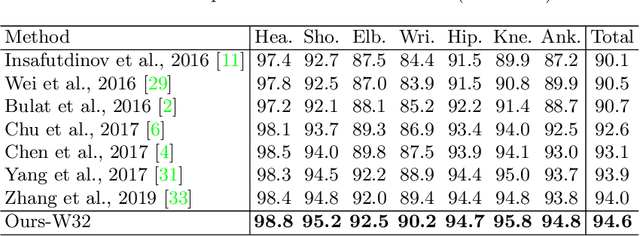
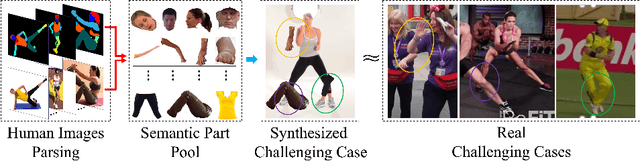
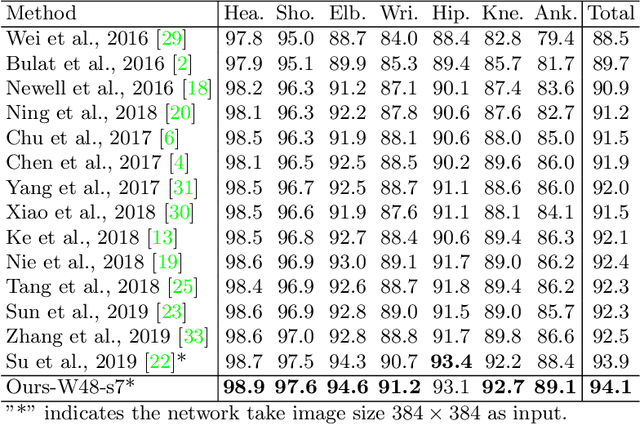
Human pose estimation is the task of localizing body keypoints from still images. The state-of-the-art methods suffer from insufficient examples of challenging cases such as symmetric appearance, heavy occlusion and nearby person. To enlarge the amounts of challenging cases, previous methods augmented images by cropping and pasting image patches with weak semantics, which leads to unrealistic appearance and limited diversity. We instead propose Semantic Data Augmentation (SDA), a method that augments images by pasting segmented body parts with various semantic granularity. Furthermore, we propose Adversarial Semantic Data Augmentation (ASDA), which exploits a generative network to dynamiclly predict tailored pasting configuration. Given off-the-shelf pose estimation network as discriminator, the generator seeks the most confusing transformation to increase the loss of the discriminator while the discriminator takes the generated sample as input and learns from it. The whole pipeline is optimized in an adversarial manner. State-of-the-art results are achieved on challenging benchmarks.
Anti-Confusing: Region-Aware Network for Human Pose Estimation
May 27, 2019
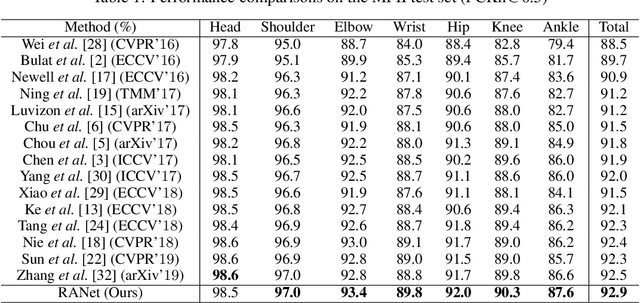
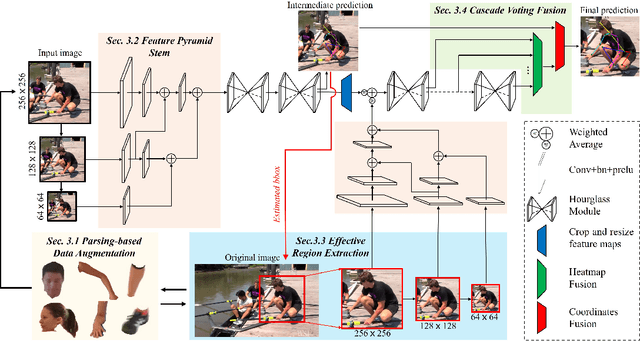
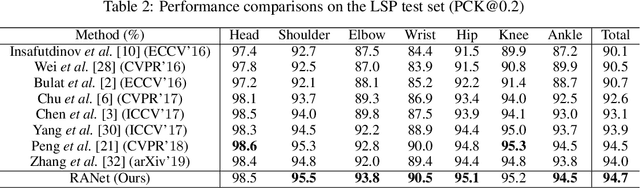
In this work, we propose a novel framework named Region-Aware Network (RANet), which learns the ability of anti-confusing in case of heavy occlusion, nearby person and symmetric appearance, for human pose estimation. Specifically, the proposed method addresses three key aspects, i.e., data augmentation, feature learning and prediction fusion, respectively. First, we propose Parsing-based Data Augmentation (PDA) to generate abundant data that synthesizes confusing textures. Second, we not only propose a Feature Pyramid Stem (FPS) to learn stronger low-level features in lower stage; but also incorporate an Effective Region Extraction (ERE) module to excavate better target-specific features. Third, we introduce Cascade Voting Fusion (CVF) to explicitly exclude the inferior predictions and fuse the rest effective predictions for the final pose estimation. Extensive experimental results on two popular benchmarks, i.e. MPII and LSP, demonstrate the effectiveness of our method against the state-of-the-art competitors. Especially on easily-confusable joints, our method makes significant improvement.
A Learning-based Framework for Hybrid Depth-from-Defocus and Stereo Matching
Aug 06, 2018
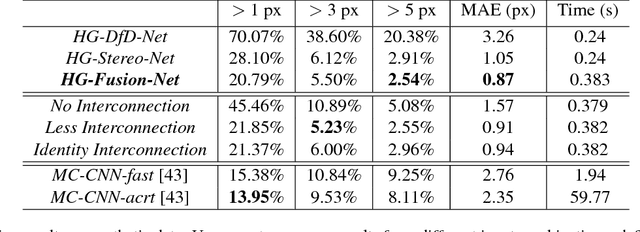


Depth from defocus (DfD) and stereo matching are two most studied passive depth sensing schemes. The techniques are essentially complementary: DfD can robustly handle repetitive textures that are problematic for stereo matching whereas stereo matching is insensitive to defocus blurs and can handle large depth range. In this paper, we present a unified learning-based technique to conduct hybrid DfD and stereo matching. Our input is image triplets: a stereo pair and a defocused image of one of the stereo views. We first apply depth-guided light field rendering to construct a comprehensive training dataset for such hybrid sensing setups. Next, we adopt the hourglass network architecture to separately conduct depth inference from DfD and stereo. Finally, we exploit different connection methods between the two separate networks for integrating them into a unified solution to produce high fidelity 3D disparity maps. Comprehensive experiments on real and synthetic data show that our new learning-based hybrid 3D sensing technique can significantly improve accuracy and robustness in 3D reconstruction.
Sparse Photometric 3D Face Reconstruction Guided by Morphable Models
Nov 29, 2017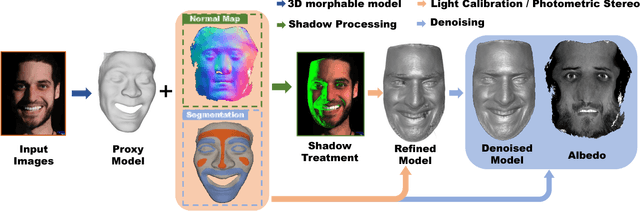
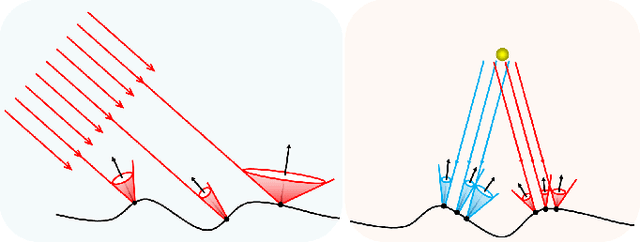
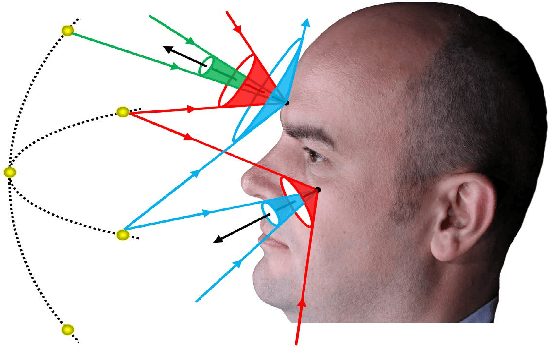

We present a novel 3D face reconstruction technique that leverages sparse photometric stereo (PS) and latest advances on face registration/modeling from a single image. We observe that 3D morphable faces approach provides a reasonable geometry proxy for light position calibration. Specifically, we develop a robust optimization technique that can calibrate per-pixel lighting direction and illumination at a very high precision without assuming uniform surface albedos. Next, we apply semantic segmentation on input images and the geometry proxy to refine hairy vs. bare skin regions using tailored filters. Experiments on synthetic and real data show that by using a very small set of images, our technique is able to reconstruct fine geometric details such as wrinkles, eyebrows, whelks, pores, etc, comparable to and sometimes surpassing movie quality productions.