 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Retrieval with Learned Similarities
Jul 22, 2024



Retrieval plays a fundamental role in recommendation systems, search, and natural language processing by efficiently finding relevant items from a large corpus given a query. Dot products have been widely used as the similarity function in such retrieval tasks, thanks to Maximum Inner Product Search (MIPS) that enabled efficient retrieval based on dot products. However, state-of-the-art retrieval algorithms have migrated to learned similarities. Such algorithms vary in form; the queries can be represented with multiple embeddings, complex neural networks can be deployed, the item ids can be decoded directly from queries using beam search, and multiple approaches can be combined in hybrid solutions. Unfortunately, we lack efficient solutions for retrieval in these state-of-the-art setups. Our work investigates techniques for approximate nearest neighbor search with learned similarity functions. We first prove that Mixture-of-Logits (MoL) is a universal approximator, and can express all learned similarity functions. We next propose techniques to retrieve the approximate top K results using MoL with a tight bound. We finally compare our techniques with existing approaches, showing that MoL sets new state-of-the-art results on recommendation retrieval tasks, and our approximate top-k retrieval with learned similarities outperforms baselines by up to two orders of magnitude in latency, while achieving > .99 recall rate of exact algorithms.
Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations
Feb 27, 2024



Large-scale recommendation systems are characterized by their reliance on high cardinality, heterogeneous features and the need to handle tens of billions of user actions on a daily basis. Despite being trained on huge volume of data with thousands of features, most Deep Learning Recommendation Models (DLRMs) in industry fail to scale with compute. Inspired by success achieved by Transformers in language and vision domains, we revisit fundamental design choices in recommendation systems. We reformulate recommendation problems as sequential transduction tasks within a generative modeling framework (``Generative Recommenders''), and propose a new architecture, HSTU, designed for high cardinality, non-stationary streaming recommendation data. HSTU outperforms baselines over synthetic and public datasets by up to 65.8\% in NDCG, and is 5.3x to 15.2x faster than FlashAttention2-based Transformers on 8192 length sequences. HSTU-based Generative Recommenders, with 1.5 trillion parameters, improve metrics in online A/B tests by 12.4\% and have been deployed on multiple surfaces of a large internet platform with billions of users. More importantly, the model quality of Generative Recommenders empirically scales as a power-law of training compute across three orders of magnitude, up to GPT-3/LLaMa-2 scale, which reduces carbon footprint needed for future model developments, and further paves the way for the first foundational models in recommendations.
Revisiting Neural Retrieval on Accelerators
Jun 06, 2023



Retrieval finds a small number of relevant candidates from a large corpus for information retrieval and recommendation applications. A key component of retrieval is to model (user, item) similarity, which is commonly represented as the dot product of two learned embeddings. This formulation permits efficient inference, commonly known as Maximum Inner Product Search (MIPS). Despite its popularity, dot products cannot capture complex user-item interactions, which are multifaceted and likely high rank. We hence examine non-dot-product retrieval settings on accelerators, and propose \textit{mixture of logits} (MoL), which models (user, item) similarity as an adaptive composition of elementary similarity functions. This new formulation is expressive, capable of modeling high rank (user, item) interactions, and further generalizes to the long tail. When combined with a hierarchical retrieval strategy, \textit{h-indexer}, we are able to scale up MoL to 100M corpus on a single GPU with latency comparable to MIPS baselines. On public datasets, our approach leads to uplifts of up to 77.3\% in hit rate (HR). Experiments on a large recommendation surface at Meta showed strong metric gains and reduced popularity bias, validating the proposed approach's performance and improved generalization.
Model-Agnostic Graph Regularization for Few-Shot Learning
Feb 14, 2021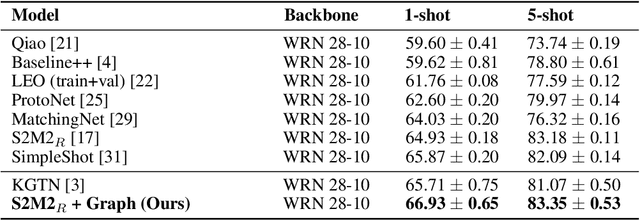
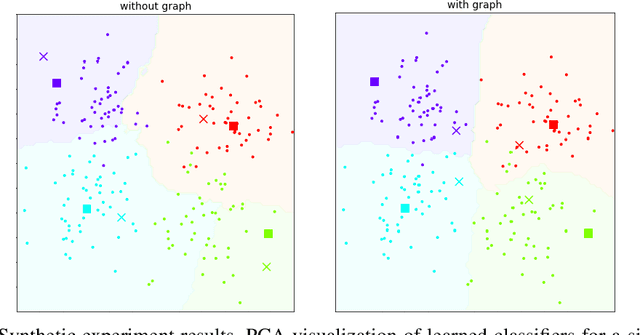
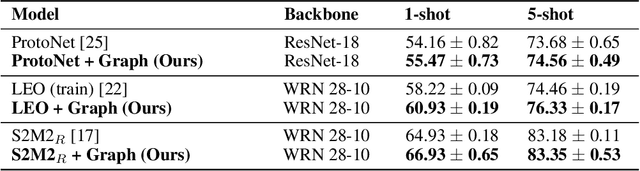
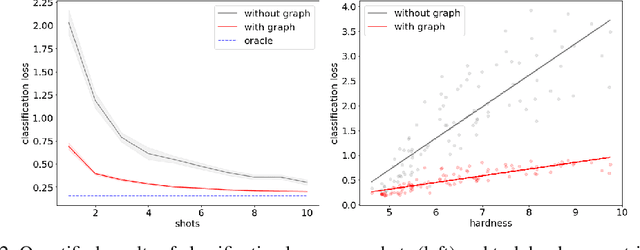
In many domains, relationships between categories are encoded in the knowledge graph. Recently, promising results have been achieved by incorporating knowledge graph as side information in hard classification tasks with severely limited data. However, prior models consist of highly complex architectures with many sub-components that all seem to impact performance. In this paper, we present a comprehensive empirical study on graph embedded few-shot learning. We introduce a graph regularization approach that allows a deeper understanding of the impact of incorporating graph information between labels. Our proposed regularization is widely applicable and model-agnostic, and boosts the performance of any few-shot learning model, including fine-tuning, metric-based, and optimization-based meta-learning. Our approach improves the performance of strong base learners by up to 2% on Mini-ImageNet and 6.7% on ImageNet-FS, outperforming state-of-the-art graph embedded methods. Additional analyses reveal that graph regularizing models result in a lower loss for more difficult tasks, such as those with fewer shots and less informative support examples.
Generating Representative Headlines for News Stories
Feb 01, 2020
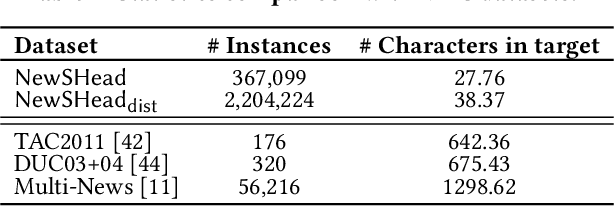
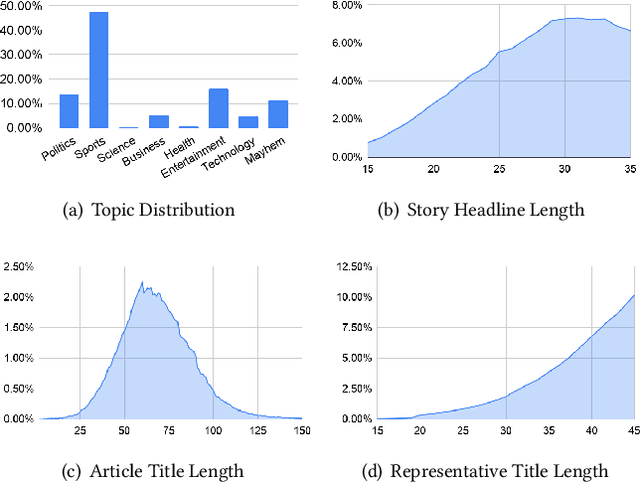

Millions of news articles are published online every day, which can be overwhelming for readers to follow. Grouping articles that are reporting the same event into news stories is a common way of assisting readers in their news consumption. However, it remains a challenging research problem to efficiently and effectively generate a representative headline for each story. Automatic summarization of a document set has been studied for decades, while few studies have focused on generating representative headlines for a set of articles. Unlike summaries, which aim to capture most information with least redundancy, headlines aim to capture information jointly shared by the story articles in short length, and exclude information that is too specific to each individual article. In this work, we study the problem of generating representative headlines for news stories. We develop a distant supervision approach to train large-scale generation models without any human annotation. This approach centers on two technical components. First, we propose a multi-level pre-training framework that incorporates massive unlabeled corpus with different quality-vs.-quantity balance at different levels. We show that models trained within this framework outperform those trained with pure human curated corpus. Second, we propose a novel self-voting-based article attention layer to extract salient information shared by multiple articles. We show that models that incorporate this layer are robust to potential noises in news stories and outperform existing baselines with or without noises. We can further enhance our model by incorporating human labels, and we show our distant supervision approach significantly reduces the demand on labeled data.