 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Agnostic Graph Regularization for Few-Shot Learning
Paper and Code
Feb 14, 2021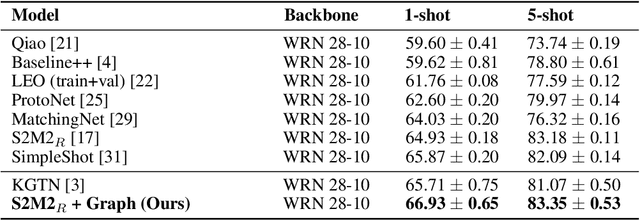
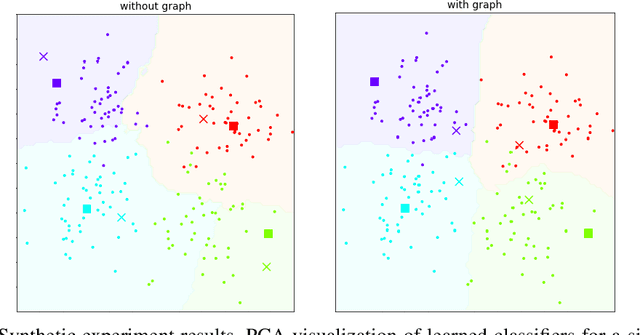
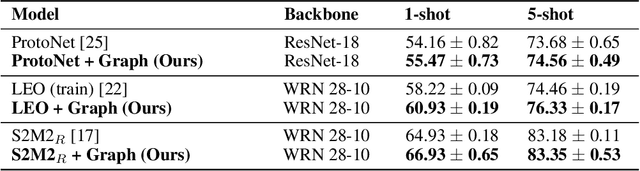
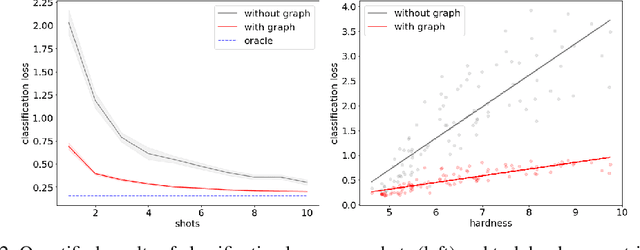
In many domains, relationships between categories are encoded in the knowledge graph. Recently, promising results have been achieved by incorporating knowledge graph as side information in hard classification tasks with severely limited data. However, prior models consist of highly complex architectures with many sub-components that all seem to impact performance. In this paper, we present a comprehensive empirical study on graph embedded few-shot learning. We introduce a graph regularization approach that allows a deeper understanding of the impact of incorporating graph information between labels. Our proposed regularization is widely applicable and model-agnostic, and boosts the performance of any few-shot learning model, including fine-tuning, metric-based, and optimization-based meta-learning. Our approach improves the performance of strong base learners by up to 2% on Mini-ImageNet and 6.7% on ImageNet-FS, outperforming state-of-the-art graph embedded methods. Additional analyses reveal that graph regularizing models result in a lower loss for more difficult tasks, such as those with fewer shots and less informative support examples.