 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Weak LLMs Speak with Confidence, Preference Alignment Gets Stronger
Mar 05, 2026Preference alignment is an essential step in adapting large language models (LLMs) to human values, but existing approaches typically depend on costly human annotations or large-scale API-based models. We explore whether a weak LLM can instead act as an effective annotator. We surprisingly find that selecting only a subset of a weak LLM's highly confident samples leads to substantially better performance than using full human annotations. Building on this insight, we propose Confidence-Weighted Preference Optimization (CW-PO), a general framework that re-weights training samples by a weak LLM's confidence and can be applied across different preference optimization objectives. Notably, the model aligned by CW-PO with just 20% of human annotations outperforms the model trained with 100% of annotations under standard DPO. These results suggest that weak LLMs, when paired with confidence weighting, can dramatically reduce the cost of preference alignment while even outperforming methods trained on fully human-labeled data.
Meta-RL Induces Exploration in Language Agents
Dec 18, 2025Reinforcement learning (RL) has enabled the training of large language model (LLM) agents to interact with the environment and to solve multi-turn long-horizon tasks. However, the RL-trained agents often struggle in tasks that require active exploration and fail to efficiently adapt from trial-and-error experiences. In this paper, we present LaMer, a general Meta-RL framework that enables LLM agents to actively explore and learn from the environment feedback at test time. LaMer consists of two key components: (i) a cross-episode training framework to encourage exploration and long-term rewards optimization; and (ii) in-context policy adaptation via reflection, allowing the agent to adapt their policy from task feedback signal without gradient update. Experiments across diverse environments show that LaMer significantly improves performance over RL baselines, with 11%, 14%, and 19% performance gains on Sokoban, MineSweeper and Webshop, respectively. Moreover, LaMer also demonstrates better generalization to more challenging or previously unseen tasks compared to the RL-trained agents. Overall, our results demonstrate that Meta-RL provides a principled approach to induce exploration in language agents, enabling more robust adaptation to novel environments through learned exploration strategies.
Large (Vision) Language Models are Unsupervised In-Context Learners
Apr 03, 2025Recent advances in large language and vision-language models have enabled zero-shot inference, allowing models to solve new tasks without task-specific training. Various adaptation techniques such as prompt engineering, In-Context Learning (ICL), and supervised fine-tuning can further enhance the model's performance on a downstream task, but they require substantial manual effort to construct effective prompts or labeled examples. In this work, we introduce a joint inference framework for fully unsupervised adaptation, eliminating the need for manual prompt engineering and labeled examples. Unlike zero-shot inference, which makes independent predictions, the joint inference makes predictions simultaneously for all inputs in a given task. Since direct joint inference involves computationally expensive optimization, we develop efficient approximation techniques, leading to two unsupervised adaptation methods: unsupervised fine-tuning and unsupervised ICL. We demonstrate the effectiveness of our methods across diverse tasks and models, including language-only Llama-3.1 on natural language processing tasks, reasoning-oriented Qwen2.5-Math on grade school math problems, vision-language OpenFlamingo on vision tasks, and the API-only access GPT-4o model on massive multi-discipline tasks. Our experiments demonstrate substantial improvements over the standard zero-shot approach, including 39% absolute improvement on the challenging GSM8K math reasoning dataset. Remarkably, despite being fully unsupervised, our framework often performs on par with supervised approaches that rely on ground truth labels.
Cross-domain Open-world Discovery
Jun 17, 2024



In many real-world applications, test data may commonly exhibit categorical shifts, characterized by the emergence of novel classes, as well as distribution shifts arising from feature distributions different from the ones the model was trained on. However, existing methods either discover novel classes in the open-world setting or assume domain shifts without the ability to discover novel classes. In this work, we consider a cross-domain open-world discovery setting, where the goal is to assign samples to seen classes and discover unseen classes under a domain shift. To address this challenging problem, we present CROW, a prototype-based approach that introduces a cluster-then-match strategy enabled by a well-structured representation space of foundation models. In this way, CROW discovers novel classes by robustly matching clusters with previously seen classes, followed by fine-tuning the representation space using an objective designed for cross-domain open-world discovery. Extensive experimental results on image classification benchmark datasets demonstrate that CROW outperforms alternative baselines, achieving an 8% average performance improvement across 75 experimental settings.
Let Go of Your Labels with Unsupervised Transfer
Jun 11, 2024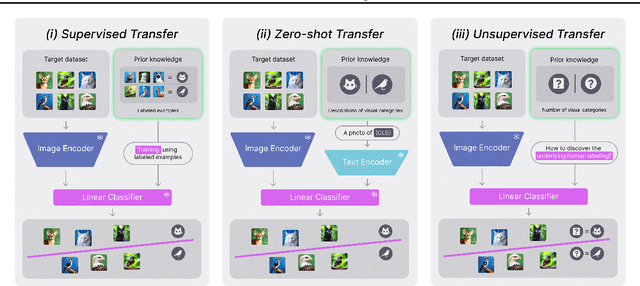
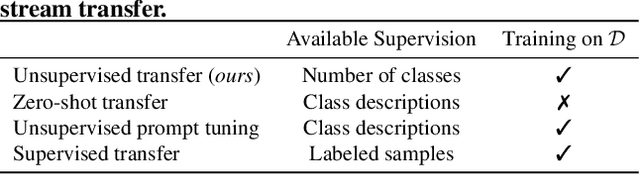
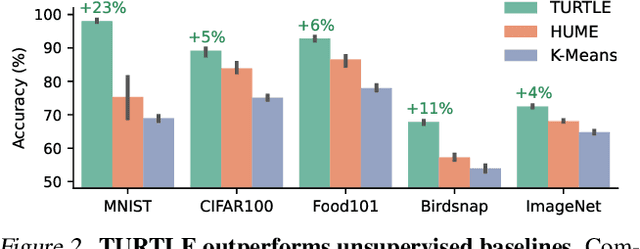

Foundation vision-language models have enabled remarkable zero-shot transferability of the pre-trained representations to a wide range of downstream tasks. However, to solve a new task, zero-shot transfer still necessitates human guidance to define visual categories that appear in the data. Here, we show that fully unsupervised transfer emerges when searching for the labeling of a dataset that induces maximal margin classifiers in representation spaces of different foundation models. We present TURTLE, a fully unsupervised method that effectively employs this guiding principle to uncover the underlying labeling of a downstream dataset without any supervision and task-specific representation learning. We evaluate TURTLE on a diverse benchmark suite of 26 datasets and show that it achieves new state-of-the-art unsupervised performance. Furthermore, TURTLE, although being fully unsupervised, outperforms zero-shot transfer baselines on a wide range of datasets. In particular, TURTLE matches the average performance of CLIP zero-shot on 26 datasets by employing the same representation space, spanning a wide range of architectures and model sizes. By guiding the search for the underlying labeling using the representation spaces of two foundation models, TURTLE surpasses zero-shot transfer and unsupervised prompt tuning baselines, demonstrating the surprising power and effectiveness of unsupervised transfer.
The Pursuit of Human Labeling: A New Perspective on Unsupervised Learning
Nov 06, 2023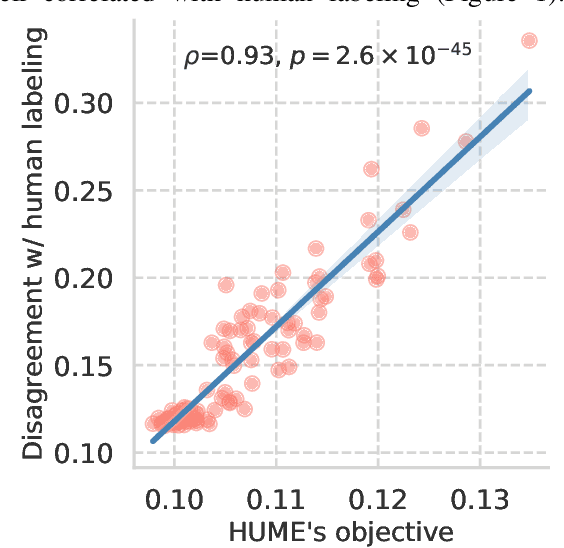
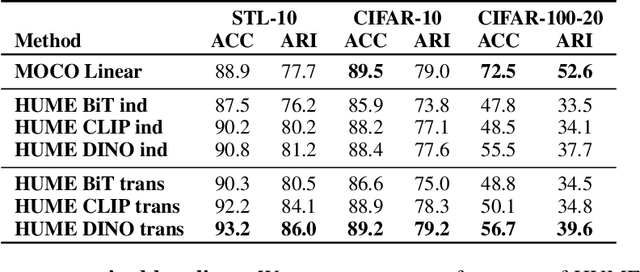
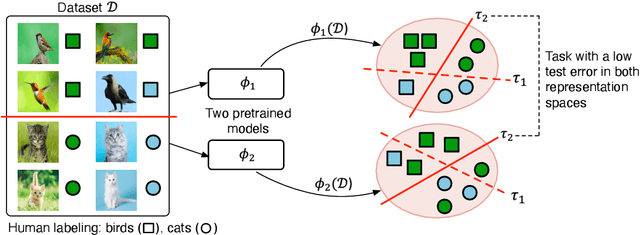

We present HUME, a simple model-agnostic framework for inferring human labeling of a given dataset without any external supervision. The key insight behind our approach is that classes defined by many human labelings are linearly separable regardless of the representation space used to represent a dataset. HUME utilizes this insight to guide the search over all possible labelings of a dataset to discover an underlying human labeling. We show that the proposed optimization objective is strikingly well-correlated with the ground truth labeling of the dataset. In effect, we only train linear classifiers on top of pretrained representations that remain fixed during training, making our framework compatible with any large pretrained and self-supervised model. Despite its simplicity, HUME outperforms a supervised linear classifier on top of self-supervised representations on the STL-10 dataset by a large margin and achieves comparable performance on the CIFAR-10 dataset. Compared to the existing unsupervised baselines, HUME achieves state-of-the-art performance on four benchmark image classification datasets including the large-scale ImageNet-1000 dataset. Altogether, our work provides a fundamentally new view to tackle unsupervised learning by searching for consistent labelings between different representation spaces.
AMPNet: Attention as Message Passing for Graph Neural Networks
Oct 17, 2022
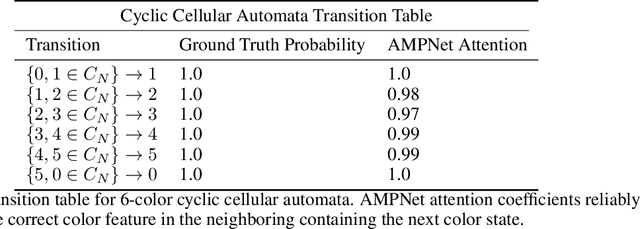
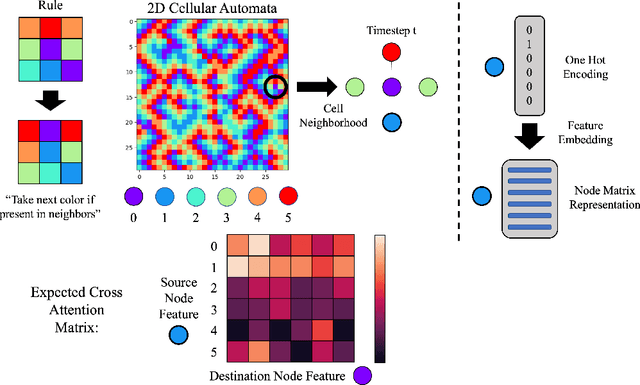
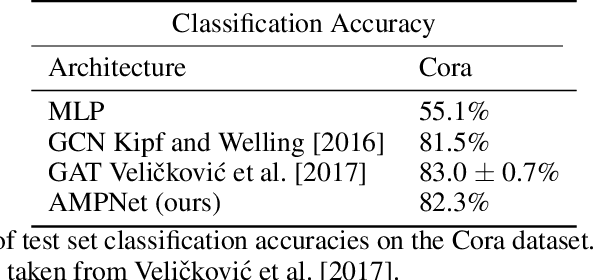
Feature-level interactions between nodes can carry crucial information for understanding complex interactions in graph-structured data. Current interpretability techniques, however, are limited in their ability to capture feature-level interactions between different nodes. In this work, we propose AMPNet, a general Graph Neural Network (GNN) architecture for uncovering feature-level interactions between different spatial locations within graph-structured data. Our framework applies a multiheaded attention operation during message-passing to contextualize messages based on the feature interactions between different nodes. We evaluate AMPNet on several benchmark and real-world datasets, and develop a synthetic benchmark based on cyclic cellular automata to test the ability of our framework to recover cyclic patterns in node states based on feature-interactions. We also propose several methods for addressing the scalability of our architecture to large graphs, including subgraph sampling during training and node feature downsampling.
Model-Agnostic Graph Regularization for Few-Shot Learning
Feb 14, 2021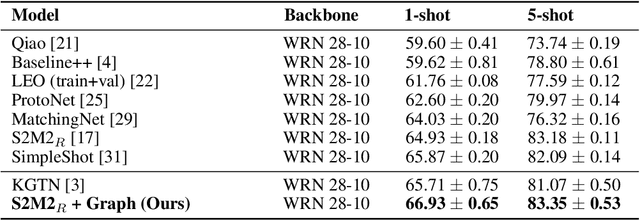
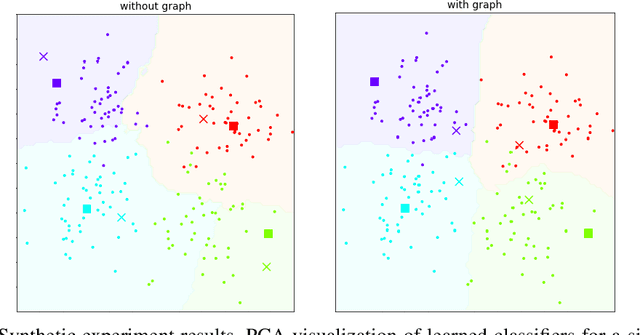
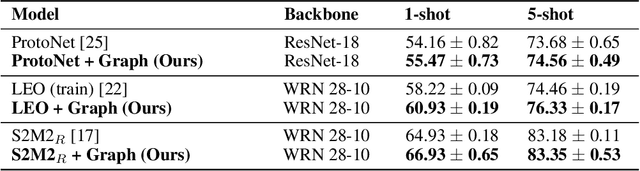
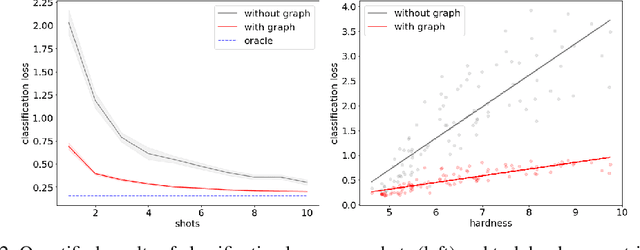
In many domains, relationships between categories are encoded in the knowledge graph. Recently, promising results have been achieved by incorporating knowledge graph as side information in hard classification tasks with severely limited data. However, prior models consist of highly complex architectures with many sub-components that all seem to impact performance. In this paper, we present a comprehensive empirical study on graph embedded few-shot learning. We introduce a graph regularization approach that allows a deeper understanding of the impact of incorporating graph information between labels. Our proposed regularization is widely applicable and model-agnostic, and boosts the performance of any few-shot learning model, including fine-tuning, metric-based, and optimization-based meta-learning. Our approach improves the performance of strong base learners by up to 2% on Mini-ImageNet and 6.7% on ImageNet-FS, outperforming state-of-the-art graph embedded methods. Additional analyses reveal that graph regularizing models result in a lower loss for more difficult tasks, such as those with fewer shots and less informative support examples.
Open-World Semi-Supervised Learning
Feb 06, 2021
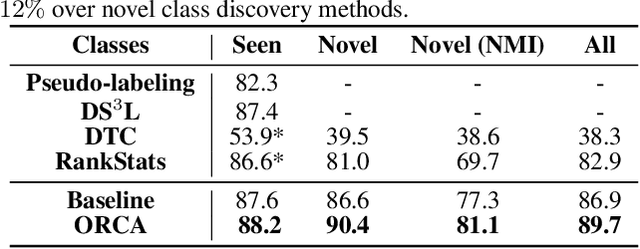
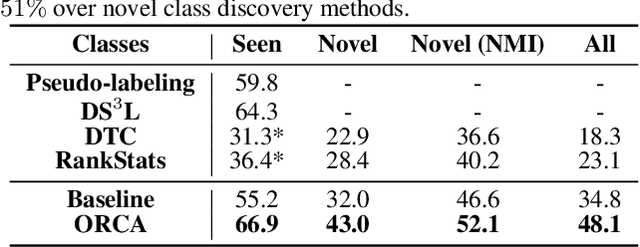
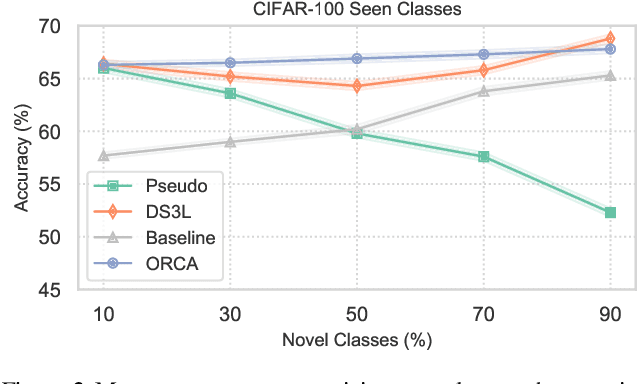
Supervised and semi-supervised learning methods have been traditionally designed for the closed-world setting based on the assumption that unlabeled test data contains only classes previously encountered in the labeled training data. However, the real world is inherently open and dynamic, and thus novel, previously unseen classes may appear in the test data or during the model deployment. Here, we introduce a new open-world semi-supervised learning setting in which the model is required to recognize previously seen classes, as well as to discover novel classes never seen in the labeled dataset. To tackle the problem, we propose ORCA, an approach that learns to simultaneously classify and cluster the data. ORCA classifies examples from the unlabeled dataset to previously seen classes, or forms a novel class by grouping similar examples together. The key idea in ORCA is in introducing uncertainty based adaptive margin that effectively circumvents the bias caused by the imbalance of variance between seen and novel classes/clusters. We demonstrate that ORCA accurately discovers novel classes and assigns samples to previously seen classes on benchmark image classification datasets, including CIFAR and ImageNet. Remarkably, despite solving the harder task ORCA outperforms semi-supervised methods on seen classes, as well as novel class discovery methods on novel classes, achieving 7% and 151% improvements on seen and novel classes in the ImageNet dataset.
Concept Learners for Generalizable Few-Shot Learning
Jul 14, 2020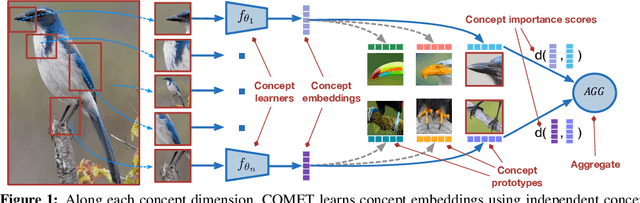
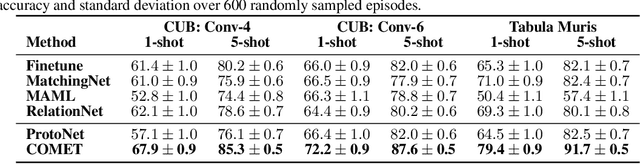

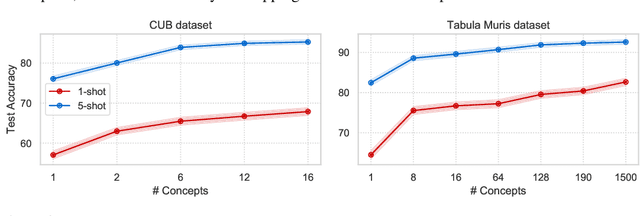
Developing algorithms that are able to generalize to a novel task given only a few labeled examples represents a fundamental challenge in closing the gap between machine- and human-level performance. The core of human cognition lies in the structured, reusable concepts that help us to rapidly adapt to new tasks and provide reasoning behind our decisions. However, existing meta-learning methods learn complex representations across prior labeled tasks without imposing any structure on the learned representations. Here we propose COMET, a meta-learning method that improves generalization ability by learning to learn along human-interpretable concept dimensions. Instead of learning a joint unstructured metric space, COMET learns mappings of high-level concepts into semi-structured metric spaces, and effectively combines the outputs of independent concept learners. We evaluate our model on few-shot tasks from diverse domains, including a benchmark image classification dataset and a novel single-cell dataset from a biological domain developed in our work. COMET significantly outperforms strong meta-learning baselines, achieving $9$-$12\%$ average improvement on the most challenging $1$-shot learning tasks, while unlike existing methods also providing interpretations behind the model's predictions.