 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Learning for Insertion-based Generation
Jun 01, 2026Non-monotonic sequence generation methods, such as masked diffusion models, provide a flexible alternative to left-to-right autoregressive modeling by allowing tokens to be generated in non-fixed and prescribed orders. Despite their practical advantages, most existing non-monotonic models are order-agnostic and rely on a fixed-length grid, limiting their ability to support variable-length generation and adaptive insertion order. In this work, we introduce a probabilistic framework for learning insertion order in variable-length insertion models. We formalize a bijective correspondence between insertion trajectories and permutations, which enables an exact reparameterization of the data likelihood as a sum over permutations. Building on this result, we propose the Insertion Process (IP), a stochastic generative model that jointly learns where to insert, what to insert, and when to terminate, trained via permutation-based variational inference. Unlike prior fixed-canvas approaches, IP natively supports variable-length generation and learns data-driven preferences over insertion orders. Experiments on goal-conditioned planning and molecular string generation demonstrate that learning insertion order improves both modeling quality and generalization in domains without a canonical left-to-right structure.
Learning Permutation Distributions via Reflected Diffusion on Ranks
Mar 18, 2026The finite symmetric group S_n provides a natural domain for permutations, yet learning probability distributions on S_n is challenging due to its factorially growing size and discrete, non-Euclidean structure. Recent permutation diffusion methods define forward noising via shuffle-based random walks (e.g., riffle shuffles) and learn reverse transitions with Plackett-Luce (PL) variants, but the resulting trajectories can be abrupt and increasingly hard to denoise as n grows. We propose Soft-Rank Diffusion, a discrete diffusion framework that replaces shuffle-based corruption with a structured soft-rank forward process: we lift permutations to a continuous latent representation of order by relaxing discrete ranks into soft ranks, yielding smoother and more tractable trajectories. For the reverse process, we introduce contextualized generalized Plackett-Luce (cGPL) denoisers that generalize prior PL-style parameterizations and improve expressivity for sequential decision structures. Experiments on sorting and combinatorial optimization benchmarks show that Soft-Rank Diffusion consistently outperforms prior diffusion baselines, with particularly strong gains in long-sequence and intrinsically sequential settings.
SciDesignBench: Benchmarking and Improving Language Models for Scientific Inverse Design
Mar 13, 2026Many of the most important problems in science and engineering are inverse problems: given a desired outcome, find a design that achieves it. Evaluating whether a candidate meets the spec is often routine; a binding energy can be computed, a reactor yield simulated, a pharmacokinetic profile predicted. But searching a combinatorial design space for inputs that satisfy those targets is fundamentally harder. We introduce SciDesignBench, a benchmark of 520 simulator-grounded tasks across 14 scientific domains and five settings spanning single-shot design, short-horizon feedback, long-horizon refinement, and seed-design optimization. On the 10-domain shared-core subset, the best zero-shot model reaches only 29.0% success despite substantially higher parse rates. Simulator feedback helps, but the leaderboard changes with horizon: Sonnet 4.5 is strongest in one-turn de novo design, whereas Opus 4.6 is strongest after 20 turns of simulator-grounded refinement. Providing a starting seed design reshuffles the leaderboard again, demonstrating that constrained modification requires a fundamentally different capability from unconstrained de novo generation. We then introduce RLSF, a simulator-feedback training recipe. An RLSF-tuned 8B model raises single-turn success rates by 8-17 percentage points across three domains. Together, these results position simulator-grounded inverse design as both a benchmark for scientific reasoning and a practical substrate for amortizing expensive test-time compute into model weights.
COAST: Intelligent Time-Adaptive Neural Operators
Feb 12, 2025
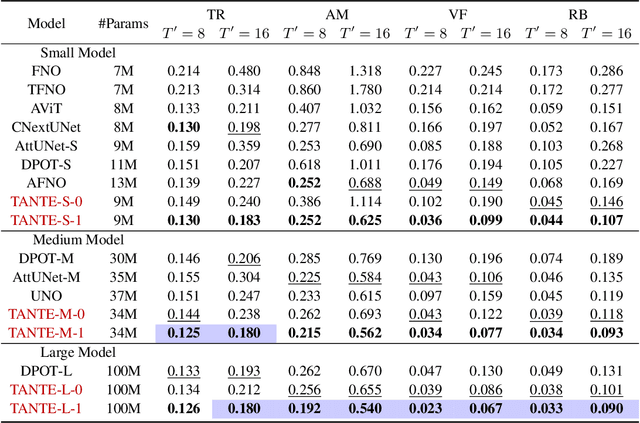
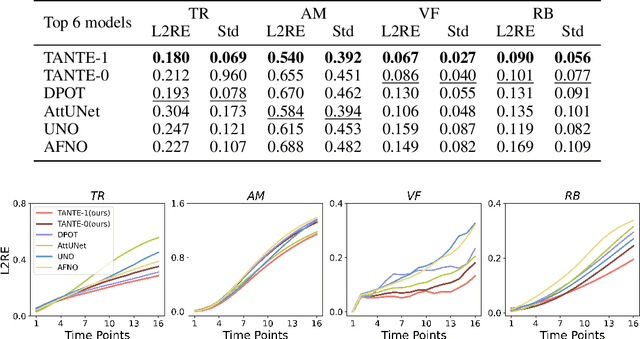
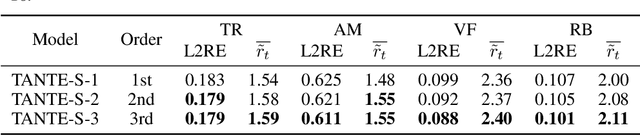
We introduce Causal Operator with Adaptive Solver Transformer (COAST), a novel neural operator learning method that leverages a causal language model (CLM) framework to dynamically adapt time steps. Our method predicts both the evolution of a system and its optimal time step, intelligently balancing computational efficiency and accuracy. We find that COAST generates variable step sizes that correlate with the underlying system intrinsicities, both within and across dynamical systems. Within a single trajectory, smaller steps are taken in regions of high complexity, while larger steps are employed in simpler regions. Across different systems, more complex dynamics receive more granular time steps. Benchmarked on diverse systems with varied dynamics, COAST consistently outperforms state-of-the-art methods, achieving superior performance in both efficiency and accuracy. This work underscores the potential of CLM-based intelligent adaptive solvers for scalable operator learning of dynamical systems.
Intelligence at the Edge of Chaos
Oct 03, 2024We explore the emergence of intelligent behavior in artificial systems by investigating how the complexity of rule-based systems influences the capabilities of models trained to predict these rules. Our study focuses on elementary cellular automata (ECA), simple yet powerful one-dimensional systems that generate behaviors ranging from trivial to highly complex. By training distinct Large Language Models (LLMs) on different ECAs, we evaluated the relationship between the complexity of the rules' behavior and the intelligence exhibited by the LLMs, as reflected in their performance on downstream tasks. Our findings reveal that rules with higher complexity lead to models exhibiting greater intelligence, as demonstrated by their performance on reasoning and chess move prediction tasks. Both uniform and periodic systems, and often also highly chaotic systems, resulted in poorer downstream performance, highlighting a sweet spot of complexity conducive to intelligence. We conjecture that intelligence arises from the ability to predict complexity and that creating intelligence may require only exposure to complexity.
CaLMFlow: Volterra Flow Matching using Causal Language Models
Oct 03, 2024We introduce CaLMFlow (Causal Language Models for Flow Matching), a novel framework that casts flow matching as a Volterra integral equation (VIE), leveraging the power of large language models (LLMs) for continuous data generation. CaLMFlow enables the direct application of LLMs to learn complex flows by formulating flow matching as a sequence modeling task, bridging discrete language modeling and continuous generative modeling. Our method implements tokenization across space and time, thereby solving a VIE over these domains. This approach enables efficient handling of high-dimensional data and outperforms ODE solver-dependent methods like conditional flow matching (CFM). We demonstrate CaLMFlow's effectiveness on synthetic and real-world data, including single-cell perturbation response prediction, showcasing its ability to incorporate textual context and generalize to unseen conditions. Our results highlight LLM-driven flow matching as a promising paradigm in generative modeling, offering improved scalability, flexibility, and context-awareness.
Operator Learning Meets Numerical Analysis: Improving Neural Networks through Iterative Methods
Oct 02, 2023Deep neural networks, despite their success in numerous applications, often function without established theoretical foundations. In this paper, we bridge this gap by drawing parallels between deep learning and classical numerical analysis. By framing neural networks as operators with fixed points representing desired solutions, we develop a theoretical framework grounded in iterative methods for operator equations. Under defined conditions, we present convergence proofs based on fixed point theory. We demonstrate that popular architectures, such as diffusion models and AlphaFold, inherently employ iterative operator learning. Empirical assessments highlight that performing iterations through network operators improves performance. We also introduce an iterative graph neural network, PIGN, that further demonstrates benefits of iterations. Our work aims to enhance the understanding of deep learning by merging insights from numerical analysis, potentially guiding the design of future networks with clearer theoretical underpinnings and improved performance.
Continuous Spatiotemporal Transformers
Jan 31, 2023



Modeling spatiotemporal dynamical systems is a fundamental challenge in machine learning. Transformer models have been very successful in NLP and computer vision where they provide interpretable representations of data. However, a limitation of transformers in modeling continuous dynamical systems is that they are fundamentally discrete time and space models and thus have no guarantees regarding continuous sampling. To address this challenge, we present the Continuous Spatiotemporal Transformer (CST), a new transformer architecture that is designed for the modeling of continuous systems. This new framework guarantees a continuous and smooth output via optimization in Sobolev space. We benchmark CST against traditional transformers as well as other spatiotemporal dynamics modeling methods and achieve superior performance in a number of tasks on synthetic and real systems, including learning brain dynamics from calcium imaging data.
AMPNet: Attention as Message Passing for Graph Neural Networks
Oct 17, 2022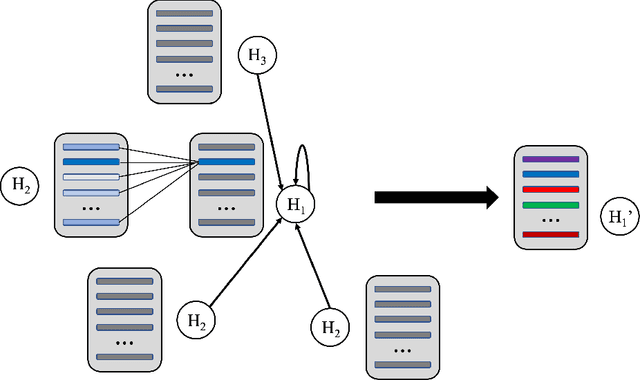
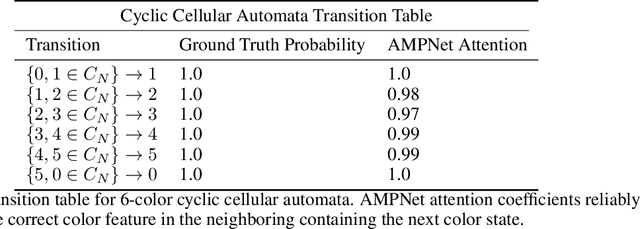
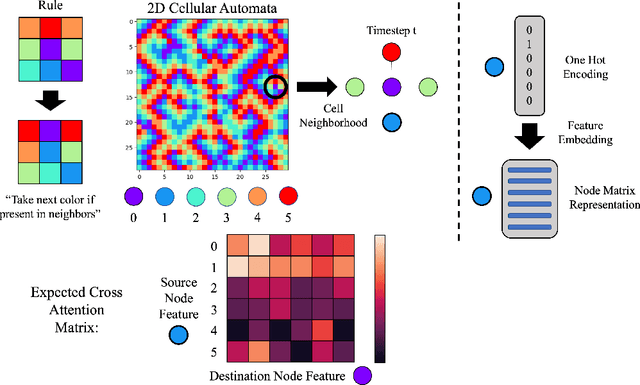
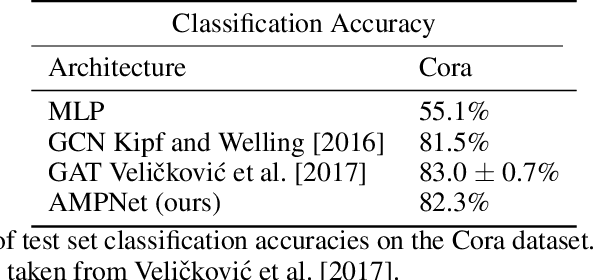
Feature-level interactions between nodes can carry crucial information for understanding complex interactions in graph-structured data. Current interpretability techniques, however, are limited in their ability to capture feature-level interactions between different nodes. In this work, we propose AMPNet, a general Graph Neural Network (GNN) architecture for uncovering feature-level interactions between different spatial locations within graph-structured data. Our framework applies a multiheaded attention operation during message-passing to contextualize messages based on the feature interactions between different nodes. We evaluate AMPNet on several benchmark and real-world datasets, and develop a synthetic benchmark based on cyclic cellular automata to test the ability of our framework to recover cyclic patterns in node states based on feature-interactions. We also propose several methods for addressing the scalability of our architecture to large graphs, including subgraph sampling during training and node feature downsampling.
Neural Integral Equations
Oct 12, 2022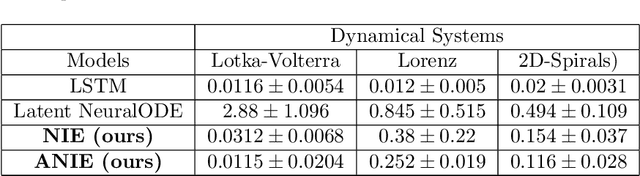

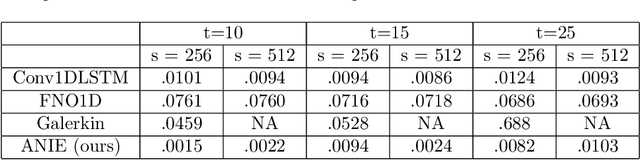
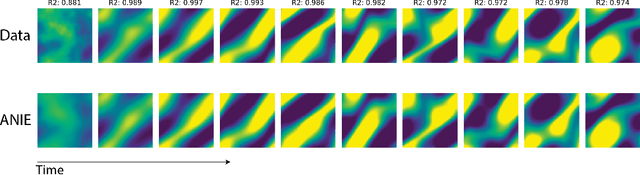
Integral equations (IEs) are functional equations defined through integral operators, where the unknown function is integrated over a possibly multidimensional space. Important applications of IEs have been found throughout theoretical and applied sciences, including in physics, chemistry, biology, and engineering; often in the form of inverse problems. IEs are especially useful since differential equations, e.g. ordinary differential equations (ODEs), and partial differential equations (PDEs) can be formulated in an integral version which is often more convenient to solve. Moreover, unlike ODEs and PDEs, IEs can model inherently non-local dynamical systems, such as ones with long distance spatiotemporal relations. While efficient algorithms exist for solving given IEs, no method exists that can learn an integral equation and its associated dynamics from data alone. In this article, we introduce Neural Integral Equations (NIE), a method that learns an unknown integral operator from data through a solver. We also introduce an attentional version of NIE, called Attentional Neural Integral Equations (ANIE), where the integral is replaced by self-attention, which improves scalability and provides interpretability. We show that learning dynamics via integral equations is faster than doing so via other continuous methods, such as Neural ODEs. Finally, we show that ANIE outperforms other methods on several benchmark tasks in ODE, PDE, and IE systems of synthetic and real-world data.