 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters
Jun 01, 2026Parameter-efficient fine-tuning (PEFT) is usually treated as a cheaper alternative to full fine-tuning. We study a broader role: small trainable adapters as persistent local state on top of strong shared foundation models. In this framing, the base model provides shared competence while adapters carry instance-specific behavior such as preferences, skills, tool habits, and memory-like updates. We organize the problem around three scaling axes: Scale Up, where stronger shared priors make small local updates more useful; Scale Down, where we study how small adapters can be while remaining reliable; and Scale Out, where many persistent adapted instances coexist. MinT provides one infrastructure example for managing adapter identity, revision, provenance, evaluation, and serving residency. Together, the results suggest that PEFT can be a compact substrate for persistent personal models rather than only a budget substitute for full fine-tuning.
Learning Permutation Distributions via Reflected Diffusion on Ranks
Mar 18, 2026The finite symmetric group S_n provides a natural domain for permutations, yet learning probability distributions on S_n is challenging due to its factorially growing size and discrete, non-Euclidean structure. Recent permutation diffusion methods define forward noising via shuffle-based random walks (e.g., riffle shuffles) and learn reverse transitions with Plackett-Luce (PL) variants, but the resulting trajectories can be abrupt and increasingly hard to denoise as n grows. We propose Soft-Rank Diffusion, a discrete diffusion framework that replaces shuffle-based corruption with a structured soft-rank forward process: we lift permutations to a continuous latent representation of order by relaxing discrete ranks into soft ranks, yielding smoother and more tractable trajectories. For the reverse process, we introduce contextualized generalized Plackett-Luce (cGPL) denoisers that generalize prior PL-style parameterizations and improve expressivity for sequential decision structures. Experiments on sorting and combinatorial optimization benchmarks show that Soft-Rank Diffusion consistently outperforms prior diffusion baselines, with particularly strong gains in long-sequence and intrinsically sequential settings.
AutoQRA: Joint Optimization of Mixed-Precision Quantization and Low-rank Adapters for Efficient LLM Fine-Tuning
Feb 25, 2026Quantization followed by parameter-efficient fine-tuning has emerged as a promising paradigm for downstream adaptation under tight GPU memory constraints. However, this sequential pipeline fails to leverage the intricate interaction between quantization bit-width and LoRA rank. Specifically, a carefully optimized quantization allocation with low quantization error does not always translate to strong fine-tuning performance, and different bit-width and rank configurations can lead to significantly varying outcomes under the same memory budget. To address this limitation, we propose AutoQRA, a joint optimization framework that simultaneously optimizes the bit-width and LoRA rank configuration for each layer during the mixed quantized fine-tuning process. To tackle the challenges posed by the large discrete search space and the high evaluation cost associated with frequent fine-tuning iterations, AutoQRA decomposes the optimization process into two stages. First, it first conducts a global multi-fidelity evolutionary search, where the initial population is warm-started by injecting layer-wise importance priors. This stage employs specific operators and a performance model to efficiently screen candidate configurations. Second, trust-region Bayesian optimization is applied to locally refine promising regions of the search space and identify optimal configurations under the given memory budget. This approach enables active compensation for quantization noise in specific layers during training. Experiments show that AutoQRA achieves performance close to full-precision fine-tuning with a memory footprint comparable to uniform 4-bit methods.
Shared Nature, Unique Nurture: PRISM for Pluralistic Reasoning via In-context Structure Modeling
Feb 24, 2026Large Language Models (LLMs) are converging towards a singular Artificial Hivemind, where shared Nature (pre-training priors) result in a profound collapse of distributional diversity, limiting the distinct perspectives necessary for creative exploration and scientific discovery. To address this, we propose to equip models with inference-time Nurture (individualized epistemic trajectories) using Epistemic Evolution paradigm, progressing through explore, internalize, and express. We instantiate this via PRISM (Pluralistic Reasoning via In-context Structure Modeling), a model-agnostic system that augments LLM with dynamic On-the-fly Epistemic Graphs. On three creativity benchmarks, PRISM achieves state-of-the-art novelty and significantly expands distributional diversity. Moreover, we evaluate the real-world utility via a challenging rare-disease diagnosis benchmark. Results demonstrate that PRISM successfully uncovers correct long-tail diagnoses that standard LLM miss, confirming that its divergence stems from meaningful exploration rather than incoherent noise. Overall, this work establishes a new paradigm for Pluralistic AI, moving beyond monolithic consensus toward a diverse ecosystem of unique cognitive individuals capable of collective, multi-perspective discovery.
Inaccuracy of an E-Dictionary and Its Influence on Chinese Language Users
Apr 01, 2025Electronic dictionaries have largely replaced paper dictionaries and become central tools for L2 learners seeking to expand their vocabulary. Users often assume these resources are reliable and rarely question the validity of the definitions provided. The accuracy of major E-dictionaries is seldom scrutinized, and little attention has been paid to how their corpora are constructed. Research on dictionary use, particularly the limitations of electronic dictionaries, remains scarce. This study adopts a combined method of experimentation, user survey, and dictionary critique to examine Youdao, one of the most widely used E-dictionaries in China. The experiment involved a translation task paired with retrospective reflection. Participants were asked to translate sentences containing words that are insufficiently or inaccurately defined in Youdao. Their consultation behavior was recorded to analyze how faulty definitions influenced comprehension. Results show that incomplete or misleading definitions can cause serious misunderstandings. Additionally, students exhibited problematic consultation habits. The study further explores how such flawed definitions originate, highlighting issues in data processing and the integration of AI and machine learning technologies in dictionary construction. The findings suggest a need for better training in dictionary literacy for users, as well as improvements in the underlying AI models used to build E-dictionaries.
COAST: Intelligent Time-Adaptive Neural Operators
Feb 12, 2025
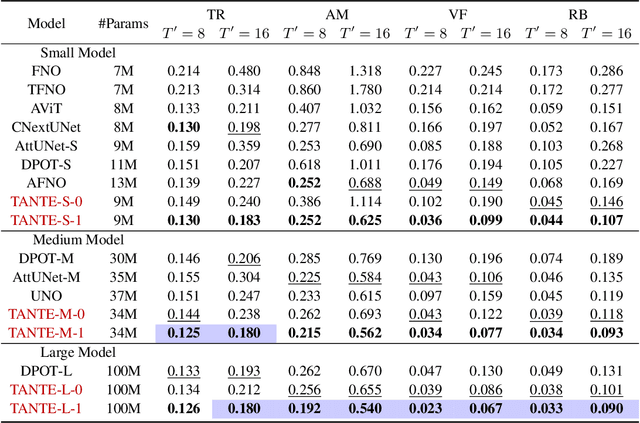
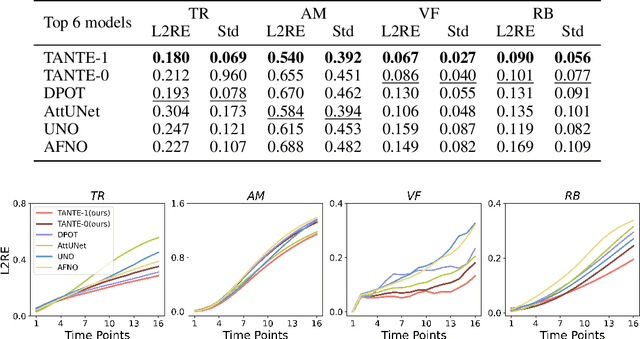
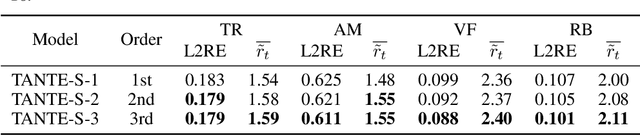
We introduce Causal Operator with Adaptive Solver Transformer (COAST), a novel neural operator learning method that leverages a causal language model (CLM) framework to dynamically adapt time steps. Our method predicts both the evolution of a system and its optimal time step, intelligently balancing computational efficiency and accuracy. We find that COAST generates variable step sizes that correlate with the underlying system intrinsicities, both within and across dynamical systems. Within a single trajectory, smaller steps are taken in regions of high complexity, while larger steps are employed in simpler regions. Across different systems, more complex dynamics receive more granular time steps. Benchmarked on diverse systems with varied dynamics, COAST consistently outperforms state-of-the-art methods, achieving superior performance in both efficiency and accuracy. This work underscores the potential of CLM-based intelligent adaptive solvers for scalable operator learning of dynamical systems.
AutoMixQ: Self-Adjusting Quantization for High Performance Memory-Efficient Fine-Tuning
Nov 21, 2024Fine-tuning large language models (LLMs) under resource constraints is a significant challenge in deep learning. Low-Rank Adaptation (LoRA), pruning, and quantization are all effective methods for improving resource efficiency. However, combining them directly often results in suboptimal performance, especially with uniform quantization across all model layers. This is due to the complex, uneven interlayer relationships introduced by pruning, necessitating more refined quantization strategies. To address this, we propose AutoMixQ, an end-to-end optimization framework that selects optimal quantization configurations for each LLM layer. AutoMixQ leverages lightweight performance models to guide the selection process, significantly reducing time and computational resources compared to exhaustive search methods. By incorporating Pareto optimality, AutoMixQ balances memory usage and performance, approaching the upper bounds of model capability under strict resource constraints. Our experiments on widely used benchmarks show that AutoMixQ reduces memory consumption while achieving superior performance. For example, at a 30\% pruning rate in LLaMA-7B, AutoMixQ achieved 66.21\% on BoolQ compared to 62.45\% for LoRA and 58.96\% for LoftQ, while reducing memory consumption by 35.5\% compared to LoRA and 27.5\% compared to LoftQ.
Intelligence at the Edge of Chaos
Oct 03, 2024We explore the emergence of intelligent behavior in artificial systems by investigating how the complexity of rule-based systems influences the capabilities of models trained to predict these rules. Our study focuses on elementary cellular automata (ECA), simple yet powerful one-dimensional systems that generate behaviors ranging from trivial to highly complex. By training distinct Large Language Models (LLMs) on different ECAs, we evaluated the relationship between the complexity of the rules' behavior and the intelligence exhibited by the LLMs, as reflected in their performance on downstream tasks. Our findings reveal that rules with higher complexity lead to models exhibiting greater intelligence, as demonstrated by their performance on reasoning and chess move prediction tasks. Both uniform and periodic systems, and often also highly chaotic systems, resulted in poorer downstream performance, highlighting a sweet spot of complexity conducive to intelligence. We conjecture that intelligence arises from the ability to predict complexity and that creating intelligence may require only exposure to complexity.
RankAdaptor: Hierarchical Dynamic Low-Rank Adaptation for Structural Pruned LLMs
Jun 22, 2024
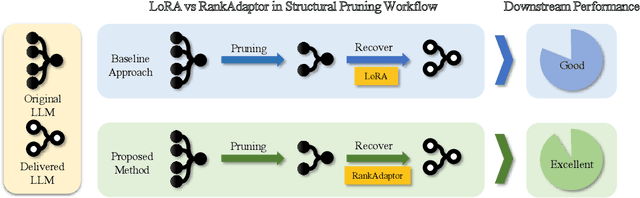
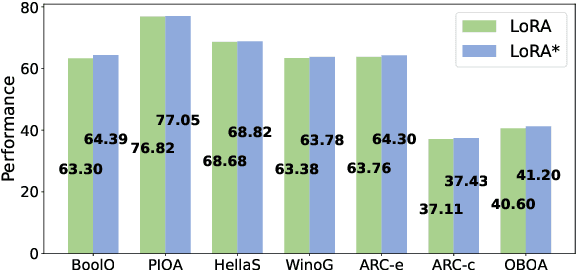
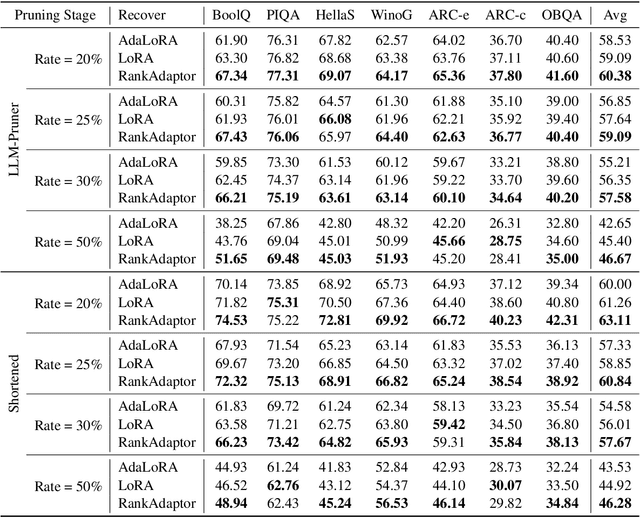
The efficient compression of large language models (LLMs) is becoming increasingly popular. However, recovering the accuracy of compressed LLMs is still a major challenge. Structural pruning with standard Low-Rank Adaptation (LoRA) is a common technique in current LLM compression. In structural pruning, the model architecture is modified unevenly, resulting in suboptimal performance in various downstream tasks via standard LoRA with fixed rank. To address this problem, we introduce RankAdaptor, an efficient fine-tuning method with hierarchical dynamic rank scheduling for pruned LLMs. An end-to-end automatic optimization flow is developed that utilizes a lightweight performance model to determine the different ranks during fine-tuning. Comprehensive experiments on popular benchmarks show that RankAdaptor consistently outperforms standard LoRA with structural pruning over different pruning settings. Without increasing the trainable parameters, RankAdaptor further reduces the accuracy performance gap between the recovery of the pruned model and the original model compared to standard LoRA.