 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Permutation Distributions via Reflected Diffusion on Ranks
Mar 18, 2026The finite symmetric group S_n provides a natural domain for permutations, yet learning probability distributions on S_n is challenging due to its factorially growing size and discrete, non-Euclidean structure. Recent permutation diffusion methods define forward noising via shuffle-based random walks (e.g., riffle shuffles) and learn reverse transitions with Plackett-Luce (PL) variants, but the resulting trajectories can be abrupt and increasingly hard to denoise as n grows. We propose Soft-Rank Diffusion, a discrete diffusion framework that replaces shuffle-based corruption with a structured soft-rank forward process: we lift permutations to a continuous latent representation of order by relaxing discrete ranks into soft ranks, yielding smoother and more tractable trajectories. For the reverse process, we introduce contextualized generalized Plackett-Luce (cGPL) denoisers that generalize prior PL-style parameterizations and improve expressivity for sequential decision structures. Experiments on sorting and combinatorial optimization benchmarks show that Soft-Rank Diffusion consistently outperforms prior diffusion baselines, with particularly strong gains in long-sequence and intrinsically sequential settings.
COAST: Intelligent Time-Adaptive Neural Operators
Feb 12, 2025
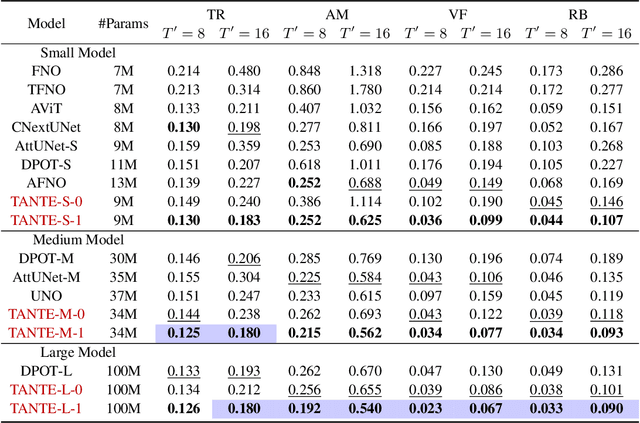
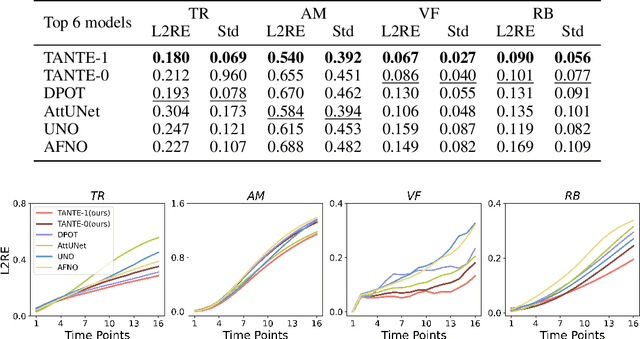
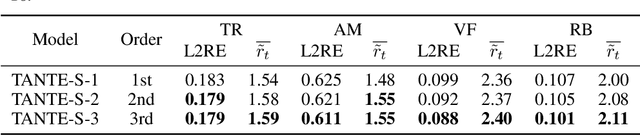
We introduce Causal Operator with Adaptive Solver Transformer (COAST), a novel neural operator learning method that leverages a causal language model (CLM) framework to dynamically adapt time steps. Our method predicts both the evolution of a system and its optimal time step, intelligently balancing computational efficiency and accuracy. We find that COAST generates variable step sizes that correlate with the underlying system intrinsicities, both within and across dynamical systems. Within a single trajectory, smaller steps are taken in regions of high complexity, while larger steps are employed in simpler regions. Across different systems, more complex dynamics receive more granular time steps. Benchmarked on diverse systems with varied dynamics, COAST consistently outperforms state-of-the-art methods, achieving superior performance in both efficiency and accuracy. This work underscores the potential of CLM-based intelligent adaptive solvers for scalable operator learning of dynamical systems.
Intelligence at the Edge of Chaos
Oct 03, 2024We explore the emergence of intelligent behavior in artificial systems by investigating how the complexity of rule-based systems influences the capabilities of models trained to predict these rules. Our study focuses on elementary cellular automata (ECA), simple yet powerful one-dimensional systems that generate behaviors ranging from trivial to highly complex. By training distinct Large Language Models (LLMs) on different ECAs, we evaluated the relationship between the complexity of the rules' behavior and the intelligence exhibited by the LLMs, as reflected in their performance on downstream tasks. Our findings reveal that rules with higher complexity lead to models exhibiting greater intelligence, as demonstrated by their performance on reasoning and chess move prediction tasks. Both uniform and periodic systems, and often also highly chaotic systems, resulted in poorer downstream performance, highlighting a sweet spot of complexity conducive to intelligence. We conjecture that intelligence arises from the ability to predict complexity and that creating intelligence may require only exposure to complexity.
CaLMFlow: Volterra Flow Matching using Causal Language Models
Oct 03, 2024We introduce CaLMFlow (Causal Language Models for Flow Matching), a novel framework that casts flow matching as a Volterra integral equation (VIE), leveraging the power of large language models (LLMs) for continuous data generation. CaLMFlow enables the direct application of LLMs to learn complex flows by formulating flow matching as a sequence modeling task, bridging discrete language modeling and continuous generative modeling. Our method implements tokenization across space and time, thereby solving a VIE over these domains. This approach enables efficient handling of high-dimensional data and outperforms ODE solver-dependent methods like conditional flow matching (CFM). We demonstrate CaLMFlow's effectiveness on synthetic and real-world data, including single-cell perturbation response prediction, showcasing its ability to incorporate textual context and generalize to unseen conditions. Our results highlight LLM-driven flow matching as a promising paradigm in generative modeling, offering improved scalability, flexibility, and context-awareness.
Operator Learning Meets Numerical Analysis: Improving Neural Networks through Iterative Methods
Oct 02, 2023Deep neural networks, despite their success in numerous applications, often function without established theoretical foundations. In this paper, we bridge this gap by drawing parallels between deep learning and classical numerical analysis. By framing neural networks as operators with fixed points representing desired solutions, we develop a theoretical framework grounded in iterative methods for operator equations. Under defined conditions, we present convergence proofs based on fixed point theory. We demonstrate that popular architectures, such as diffusion models and AlphaFold, inherently employ iterative operator learning. Empirical assessments highlight that performing iterations through network operators improves performance. We also introduce an iterative graph neural network, PIGN, that further demonstrates benefits of iterations. Our work aims to enhance the understanding of deep learning by merging insights from numerical analysis, potentially guiding the design of future networks with clearer theoretical underpinnings and improved performance.