 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaLMFlow: Volterra Flow Matching using Causal Language Models
Oct 03, 2024We introduce CaLMFlow (Causal Language Models for Flow Matching), a novel framework that casts flow matching as a Volterra integral equation (VIE), leveraging the power of large language models (LLMs) for continuous data generation. CaLMFlow enables the direct application of LLMs to learn complex flows by formulating flow matching as a sequence modeling task, bridging discrete language modeling and continuous generative modeling. Our method implements tokenization across space and time, thereby solving a VIE over these domains. This approach enables efficient handling of high-dimensional data and outperforms ODE solver-dependent methods like conditional flow matching (CFM). We demonstrate CaLMFlow's effectiveness on synthetic and real-world data, including single-cell perturbation response prediction, showcasing its ability to incorporate textual context and generalize to unseen conditions. Our results highlight LLM-driven flow matching as a promising paradigm in generative modeling, offering improved scalability, flexibility, and context-awareness.
AMPNet: Attention as Message Passing for Graph Neural Networks
Oct 17, 2022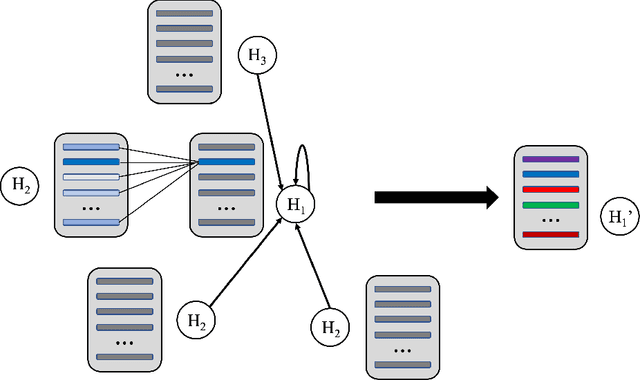
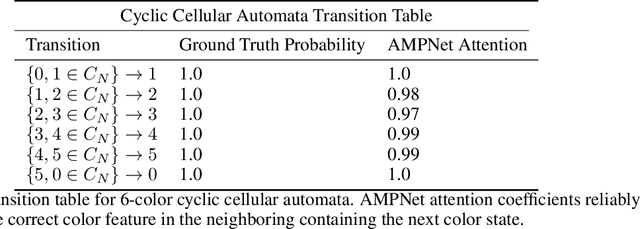
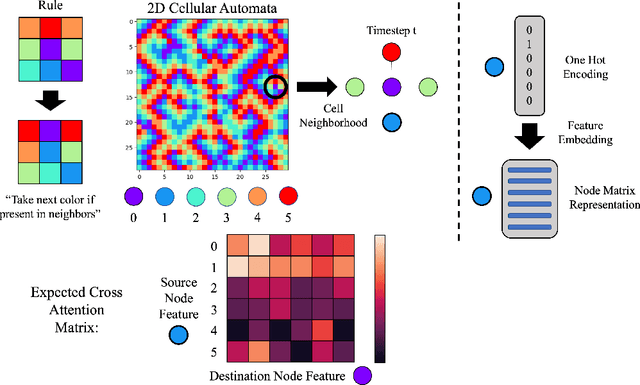
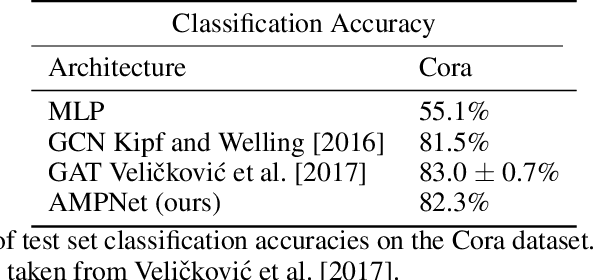
Feature-level interactions between nodes can carry crucial information for understanding complex interactions in graph-structured data. Current interpretability techniques, however, are limited in their ability to capture feature-level interactions between different nodes. In this work, we propose AMPNet, a general Graph Neural Network (GNN) architecture for uncovering feature-level interactions between different spatial locations within graph-structured data. Our framework applies a multiheaded attention operation during message-passing to contextualize messages based on the feature interactions between different nodes. We evaluate AMPNet on several benchmark and real-world datasets, and develop a synthetic benchmark based on cyclic cellular automata to test the ability of our framework to recover cyclic patterns in node states based on feature-interactions. We also propose several methods for addressing the scalability of our architecture to large graphs, including subgraph sampling during training and node feature downsampling.