 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnforcing hidden physics in physics-informed neural networks
Nov 18, 2025Physics-informed neural networks (PINNs) represent a new paradigm for solving partial differential equations (PDEs) by integrating physical laws into the learning process of neural networks. However, despite their foundational role, the hidden irreversibility implied by the Second Law of Thermodynamics is often neglected during training, leading to unphysical solutions or even training failures in conventional PINNs. In this paper, we identify this critical gap and introduce a simple, generalized, yet robust irreversibility-regularized strategy that enforces hidden physical laws as soft constraints during training. This approach ensures that the learned solutions consistently respect the intrinsic one-way nature of irreversible physical processes. Across a wide range of benchmarks spanning traveling wave propagation, steady combustion, ice melting, corrosion evolution, and crack propagation, we demonstrate that our regularization scheme reduces predictive errors by more than an order of magnitude, while requiring only minimal modification to existing PINN frameworks. We believe that the proposed framework is broadly applicable to a wide class of PDE-governed physical systems and will have significant impact within the scientific machine learning community.
FunDiff: Diffusion Models over Function Spaces for Physics-Informed Generative Modeling
Jun 09, 2025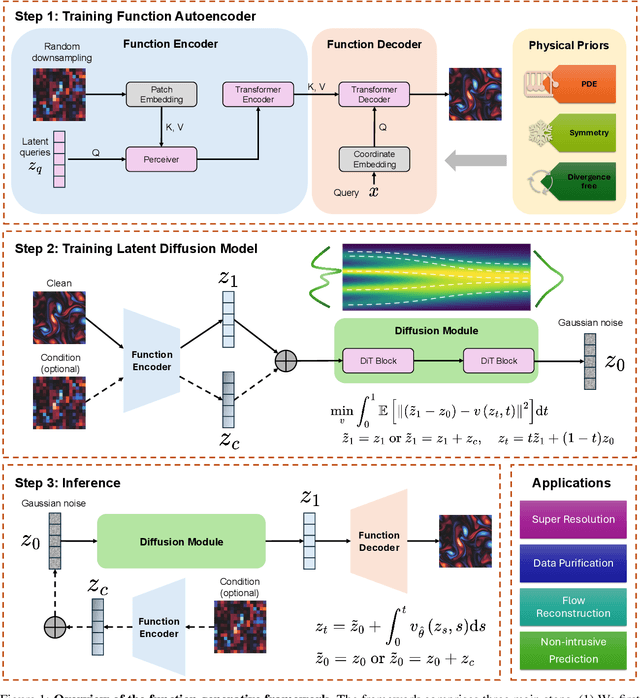
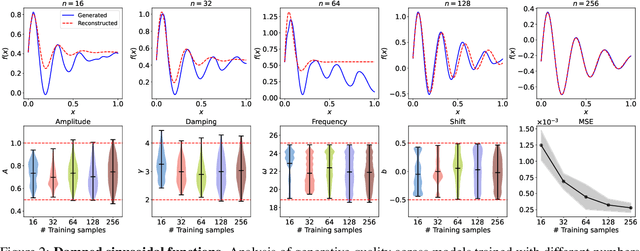
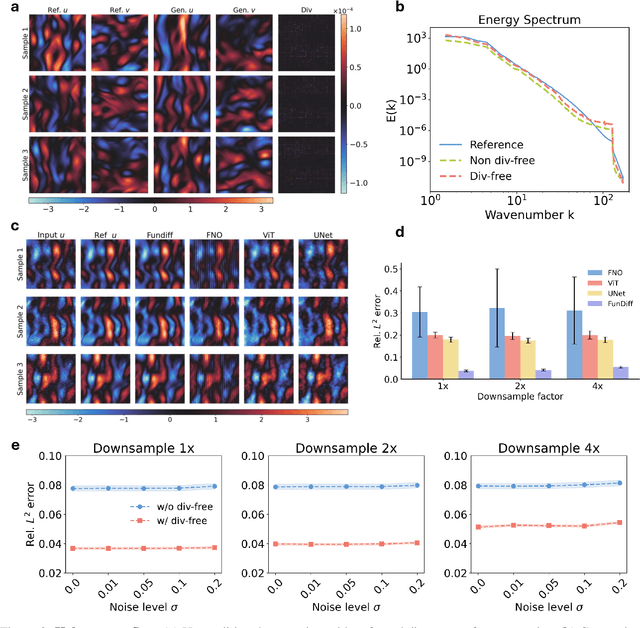
Recent advances in generative modeling -- particularly diffusion models and flow matching -- have achieved remarkable success in synthesizing discrete data such as images and videos. However, adapting these models to physical applications remains challenging, as the quantities of interest are continuous functions governed by complex physical laws. Here, we introduce $\textbf{FunDiff}$, a novel framework for generative modeling in function spaces. FunDiff combines a latent diffusion process with a function autoencoder architecture to handle input functions with varying discretizations, generate continuous functions evaluable at arbitrary locations, and seamlessly incorporate physical priors. These priors are enforced through architectural constraints or physics-informed loss functions, ensuring that generated samples satisfy fundamental physical laws. We theoretically establish minimax optimality guarantees for density estimation in function spaces, showing that diffusion-based estimators achieve optimal convergence rates under suitable regularity conditions. We demonstrate the practical effectiveness of FunDiff across diverse applications in fluid dynamics and solid mechanics. Empirical results show that our method generates physically consistent samples with high fidelity to the target distribution and exhibits robustness to noisy and low-resolution data. Code and datasets are publicly available at https://github.com/sifanexisted/fundiff.
Sharp-PINNs: staggered hard-constrained physics-informed neural networks for phase field modelling of corrosion
Feb 17, 2025Physics-informed neural networks have shown significant potential in solving partial differential equations (PDEs) across diverse scientific fields. However, their performance often deteriorates when addressing PDEs with intricate and strongly coupled solutions. In this work, we present a novel Sharp-PINN framework to tackle complex phase field corrosion problems. Instead of minimizing all governing PDE residuals simultaneously, the Sharp-PINNs introduce a staggered training scheme that alternately minimizes the residuals of Allen-Cahn and Cahn-Hilliard equations, which govern the corrosion system. To further enhance its efficiency and accuracy, we design an advanced neural network architecture that integrates random Fourier features as coordinate embeddings, employs a modified multi-layer perceptron as the primary backbone, and enforces hard constraints in the output layer. This framework is benchmarked through simulations of corrosion problems with multiple pits, where the staggered training scheme and network architecture significantly improve both the efficiency and accuracy of PINNs. Moreover, in three-dimensional cases, our approach is 5-10 times faster than traditional finite element methods while maintaining competitive accuracy, demonstrating its potential for real-world engineering applications in corrosion prediction.
COAST: Intelligent Time-Adaptive Neural Operators
Feb 12, 2025
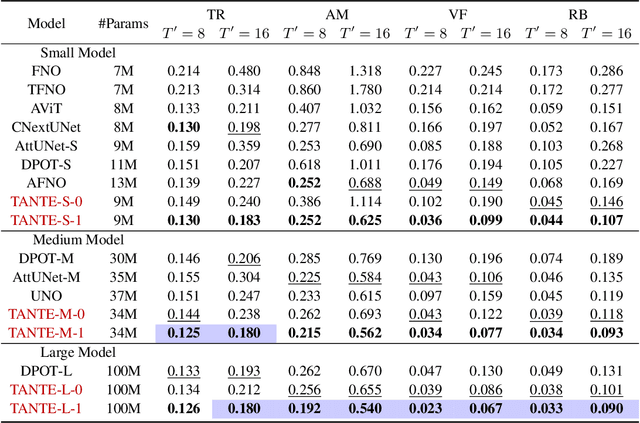
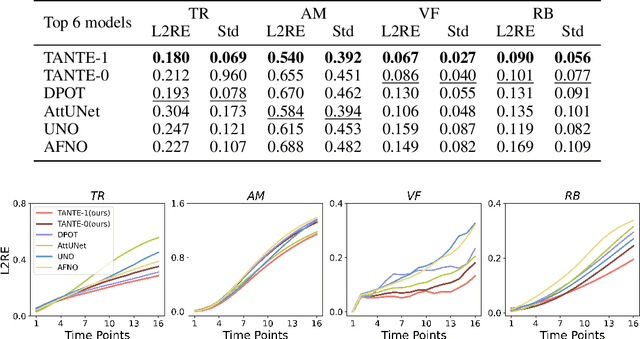
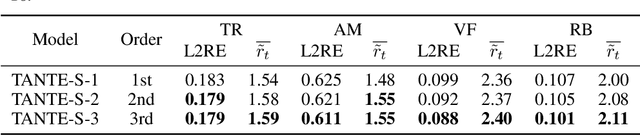
We introduce Causal Operator with Adaptive Solver Transformer (COAST), a novel neural operator learning method that leverages a causal language model (CLM) framework to dynamically adapt time steps. Our method predicts both the evolution of a system and its optimal time step, intelligently balancing computational efficiency and accuracy. We find that COAST generates variable step sizes that correlate with the underlying system intrinsicities, both within and across dynamical systems. Within a single trajectory, smaller steps are taken in regions of high complexity, while larger steps are employed in simpler regions. Across different systems, more complex dynamics receive more granular time steps. Benchmarked on diverse systems with varied dynamics, COAST consistently outperforms state-of-the-art methods, achieving superior performance in both efficiency and accuracy. This work underscores the potential of CLM-based intelligent adaptive solvers for scalable operator learning of dynamical systems.
Disk2Planet: A Robust and Automated Machine Learning Tool for Parameter Inference in Disk-Planet Systems
Sep 25, 2024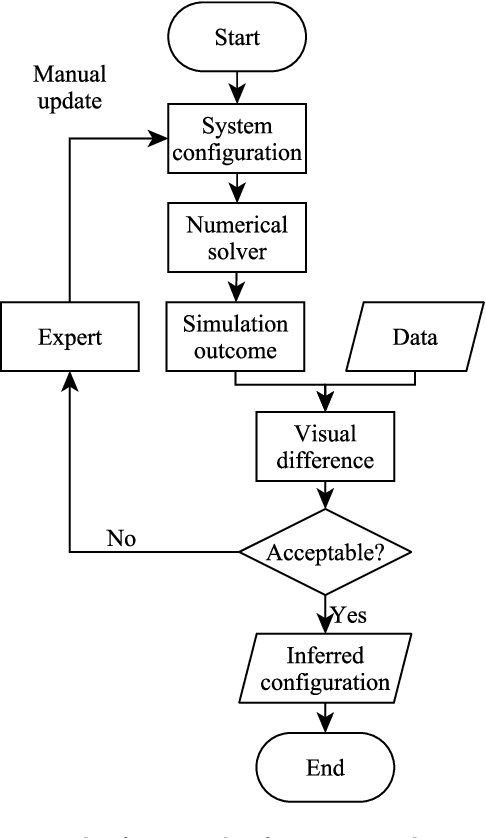
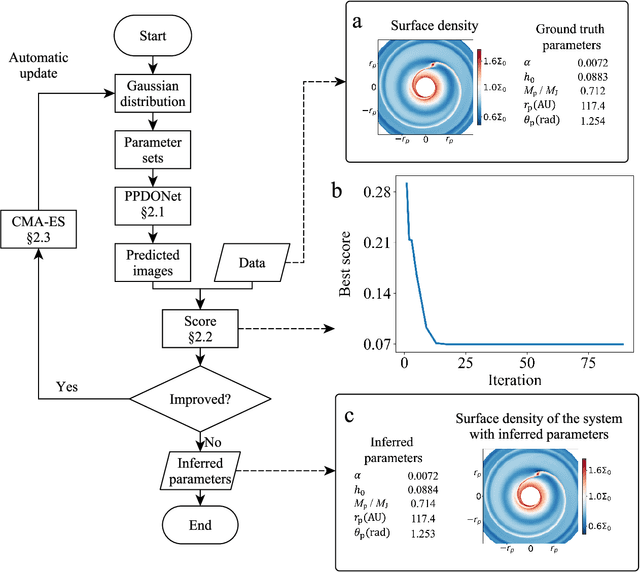
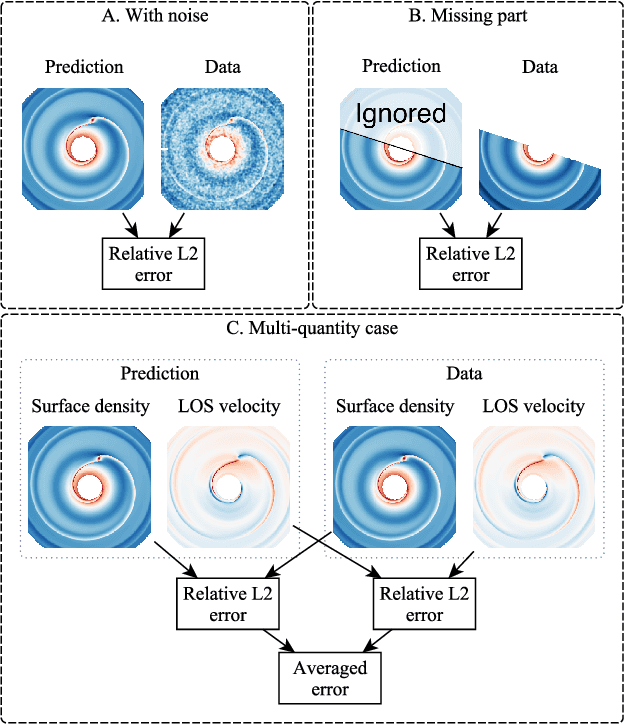
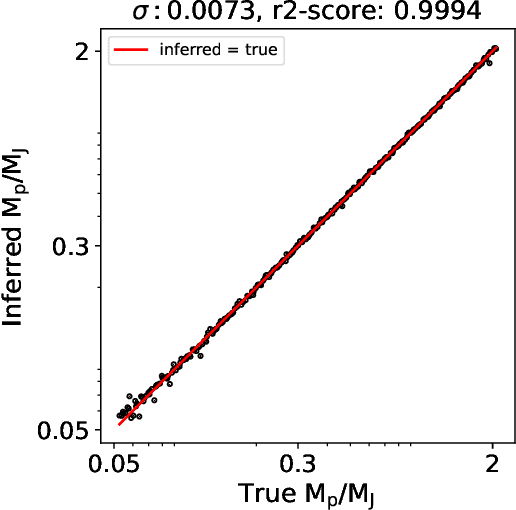
We introduce Disk2Planet, a machine learning-based tool to infer key parameters in disk-planet systems from observed protoplanetary disk structures. Disk2Planet takes as input the disk structures in the form of two-dimensional density and velocity maps, and outputs disk and planet properties, that is, the Shakura--Sunyaev viscosity, the disk aspect ratio, the planet--star mass ratio, and the planet's radius and azimuth. We integrate the Covariance Matrix Adaptation Evolution Strategy (CMA--ES), an evolutionary algorithm tailored for complex optimization problems, and the Protoplanetary Disk Operator Network (PPDONet), a neural network designed to predict solutions of disk--planet interactions. Our tool is fully automated and can retrieve parameters in one system in three minutes on an Nvidia A100 graphics processing unit. We empirically demonstrate that our tool achieves percent-level or higher accuracy, and is able to handle missing data and unknown levels of noise.
The Key of Parameter Skew in Federated Learning
Aug 21, 2024



Federated Learning (FL) has emerged as an excellent solution for performing deep learning on different data owners without exchanging raw data. However, statistical heterogeneity in FL presents a key challenge, leading to a phenomenon of skewness in local model parameter distributions that researchers have largely overlooked. In this work, we propose the concept of parameter skew to describe the phenomenon that can substantially affect the accuracy of global model parameter estimation. Additionally, we introduce FedSA, an aggregation strategy to obtain a high-quality global model, to address the implication from parameter skew. Specifically, we categorize parameters into high-dispersion and low-dispersion groups based on the coefficient of variation. For high-dispersion parameters, Micro-Classes (MIC) and Macro-Classes (MAC) represent the dispersion at the micro and macro levels, respectively, forming the foundation of FedSA. To evaluate the effectiveness of FedSA, we conduct extensive experiments with different FL algorithms on three computer vision datasets. FedSA outperforms eight state-of-the-art baselines by about 4.7% in test accuracy.
Bridging Operator Learning and Conditioned Neural Fields: A Unifying Perspective
May 22, 2024Operator learning is an emerging area of machine learning which aims to learn mappings between infinite dimensional function spaces. Here we uncover a connection between operator learning architectures and conditioned neural fields from computer vision, providing a unified perspective for examining differences between popular operator learning models. We find that many commonly used operator learning models can be viewed as neural fields with conditioning mechanisms restricted to point-wise and/or global information. Motivated by this, we propose the Continuous Vision Transformer (CViT), a novel neural operator architecture that employs a vision transformer encoder and uses cross-attention to modulate a base field constructed with a trainable grid-based positional encoding of query coordinates. Despite its simplicity, CViT achieves state-of-the-art results across challenging benchmarks in climate modeling and fluid dynamics. Our contributions can be viewed as a first step towards adapting advanced computer vision architectures for building more flexible and accurate machine learning models in physical sciences.
PirateNets: Physics-informed Deep Learning with Residual Adaptive Networks
Feb 05, 2024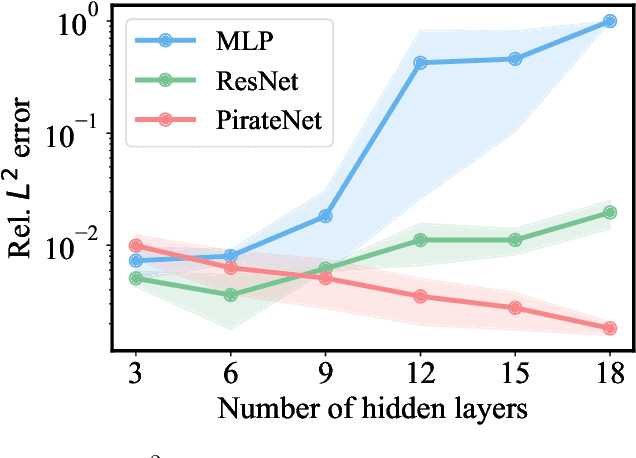

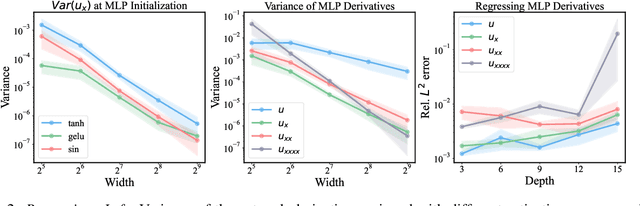
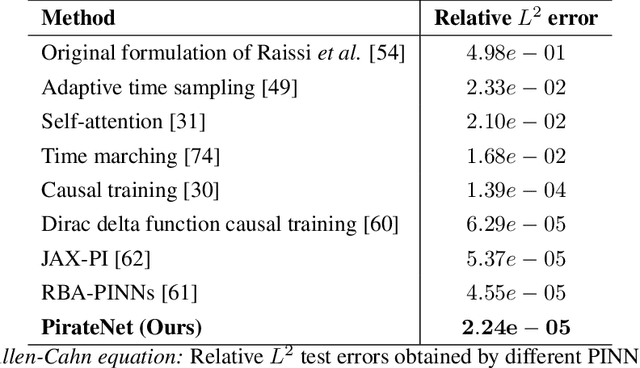
While physics-informed neural networks (PINNs) have become a popular deep learning framework for tackling forward and inverse problems governed by partial differential equations (PDEs), their performance is known to degrade when larger and deeper neural network architectures are employed. Our study identifies that the root of this counter-intuitive behavior lies in the use of multi-layer perceptron (MLP) architectures with non-suitable initialization schemes, which result in poor trainablity for the network derivatives, and ultimately lead to an unstable minimization of the PDE residual loss. To address this, we introduce Physics-informed Residual Adaptive Networks (PirateNets), a novel architecture that is designed to facilitate stable and efficient training of deep PINN models. PirateNets leverage a novel adaptive residual connection, which allows the networks to be initialized as shallow networks that progressively deepen during training. We also show that the proposed initialization scheme allows us to encode appropriate inductive biases corresponding to a given PDE system into the network architecture. We provide comprehensive empirical evidence showing that PirateNets are easier to optimize and can gain accuracy from considerably increased depth, ultimately achieving state-of-the-art results across various benchmarks. All code and data accompanying this manuscript will be made publicly available at \url{https://github.com/PredictiveIntelligenceLab/jaxpi}.
Learning Only On Boundaries: a Physics-Informed Neural operator for Solving Parametric Partial Differential Equations in Complex Geometries
Aug 24, 2023Recently deep learning surrogates and neural operators have shown promise in solving partial differential equations (PDEs). However, they often require a large amount of training data and are limited to bounded domains. In this work, we present a novel physics-informed neural operator method to solve parametrized boundary value problems without labeled data. By reformulating the PDEs into boundary integral equations (BIEs), we can train the operator network solely on the boundary of the domain. This approach reduces the number of required sample points from $O(N^d)$ to $O(N^{d-1})$, where $d$ is the domain's dimension, leading to a significant acceleration of the training process. Additionally, our method can handle unbounded problems, which are unattainable for existing physics-informed neural networks (PINNs) and neural operators. Our numerical experiments show the effectiveness of parametrized complex geometries and unbounded problems.
An Expert's Guide to Training Physics-informed Neural Networks
Aug 16, 2023



Physics-informed neural networks (PINNs) have been popularized as a deep learning framework that can seamlessly synthesize observational data and partial differential equation (PDE) constraints. Their practical effectiveness however can be hampered by training pathologies, but also oftentimes by poor choices made by users who lack deep learning expertise. In this paper we present a series of best practices that can significantly improve the training efficiency and overall accuracy of PINNs. We also put forth a series of challenging benchmark problems that highlight some of the most prominent difficulties in training PINNs, and present comprehensive and fully reproducible ablation studies that demonstrate how different architecture choices and training strategies affect the test accuracy of the resulting models. We show that the methods and guiding principles put forth in this study lead to state-of-the-art results and provide strong baselines that future studies should use for comparison purposes. To this end, we also release a highly optimized library in JAX that can be used to reproduce all results reported in this paper, enable future research studies, as well as facilitate easy adaptation to new use-case scenarios.