 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Models, Strong Priors: Architectural Inductive Bias for Parameter-Efficient Neural PDE Solvers
May 25, 2026Neural PDE solvers have followed the scaling trajectory of vision and language, with recent foundation models reaching billions of parameters. We argue that scale is a poor substitute for architectural inductive bias in this domain: structured priors deliver outsized parameter efficiency, and the pattern of where they succeed and fail is itself informative about what they capture. We instantiate this argument in WaveLiT, an architecture combining a discrete wavelet transform for lossless multi-resolution tokenization, an augmented linear attention block, a shared-weight multiscale feature pyramid, and a wavelet-domain auxiliary loss. Bespoke 1-10M-parameter WaveLiT models compete with foundation models of 100-1000$\times$ their size across eight TheWell benchmarks, with the largest gains on wave and acoustic-dominated benchmarks where the wavelet-multiscale prior fits the dominant dynamical structure and small per-step errors do not compound geometrically under rollout. Trained jointly across all eight benchmarks, a 10M-parameter foundation variant exhibits a structured, physically interpretable transfer pattern -- strongest where the wavelet-multiscale prior matches the dynamics, weakest on chaotic advection-dominated flows. The entire pipeline trains on a single GPU. The results suggest that small-model PDE performance is shaped by architectural inductive bias rather than scale, and that the structure of a prior's failures is a useful empirical signal about its content.
A Mutual Information Lower Bound for Multimodal Regression Active Learning
May 14, 2026Active learning for continuous regression has lacked an acquisition function that targets epistemic uncertainty when the predictive distribution is multimodal: variance misses modal disagreement, and information-theoretic targets like BALD are designed for discrete outputs. We introduce a Two-Index framework that makes this separation explicit: one stochastic index selects among competing model hypotheses (epistemic source), while a second governs within-hypothesis randomness (aleatoric source). An entropy decomposition within the framework identifies the mutual information between the output and the epistemic index as a principled acquisition objective, and we prove this quantity vanishes as the model is trained on growing datasets, confirming that it captures exactly the uncertainty data can resolve. Because this mutual information is intractable for continuous outputs, we derive the Mutual Information Lower Bound (MI-LB) acquisition function, a closed-form approximation for Mixture Density Network ensembles. On benchmarks featuring multimodal systems, MI-LB matches or beats every baseline evaluated and is the only method to do so consistently -- geometric and Fisher-based baselines compete only when the input space already encodes the multimodality, and collapse otherwise.
When PINNs Go Wrong: Pseudo-Time Stepping Against Spurious Solutions
Apr 26, 2026Physics-informed neural networks (PINNs) provide a promising machine learning framework for solving partial differential equations, but their training often breaks down on challenging problems, sometimes converging to physically incorrect solutions despite achieving small residual losses. This failure, we argue, is not merely an optimization difficulty. Rather, it reflects a fundamental weakness of the empirical PDE residual loss, which can admit trivial or spurious solutions during training. From this perspective, we revisit pseudo-time stepping, a technique that has recently shown strong empirical success in PINNs. We show that its main benefit is not simply to ease optimization; instead, when combined with collocation-point resampling, it helps reveal and avoid spurious solutions. At the same time, we find that the effectiveness of pseudo-time stepping depends critically on the choice of step size, which cannot be tuned reliably from the training loss alone. To overcome this limitation, we propose an adaptive pseudo-time stepping strategy that selects the step size from a finite-difference surrogate of the local residual Jacobian, yielding the largest step permitted by local stability without per-problem tuning. Across a diverse set of PDE benchmarks, the proposed method consistently improves both accuracy and robustness. Together, these findings provide a clearer understanding of why PINNs fail and suggest a practical pathway toward more reliable physics-informed learning. All code and data accompanying this manuscript are available at https://github.com/sifanexisted/jaxpi2.
Self-Flow-Matching assisted Full Waveform Inversion
Mar 13, 2026Full-waveform inversion (FWI) is a high-resolution seismic imaging method that estimates subsurface velocity by matching simulated and recorded waveforms. However, FWI is highly nonlinear, prone to cycle skipping, and sensitive to noise, particularly when low frequencies are missing or the initial model is poor, leading to failures under imperfect acquisition. Diffusion-regularized FWI introduces generative priors to encourage geologically realistic models, but these priors typically require costly offline pretraining and can deteriorate under distribution shift. Moreover, they assume Gaussian initialization and a fixed noise schedule, in which it is unclear how to map a deterministic FWI iterate and its starting model to a well-defined diffusion time or noise level. To address these limitations, we introduce Self-Flow-Matching assisted Full-Waveform Inversion (SFM-FWI), a physics-driven framework that eliminates the need for large-scale offline pretraining while avoiding the noise-level alignment ambiguity. SFM-FWI leverages flow matching to learn a transport field without assuming Gaussian initialization or a predefined noise schedule, so the initial model can be used directly as the starting point of the dynamics. Our approach trains a single flow network online using the governing physics and observed data. At each outer iteration, we build an interpolated model and update the flow by backpropagating the FWI data misfit, providing self-supervision without external training pairs. Experiments on challenging synthetic benchmarks show that SFM-FWI delivers more accurate reconstructions, greater noise robustness, and more stable convergence than standard FWI and pretraining-free regularization methods.
Multimodal Scientific Learning Beyond Diffusions and Flows
Feb 01, 2026Scientific machine learning (SciML) increasingly requires models that capture multimodal conditional uncertainty arising from ill-posed inverse problems, multistability, and chaotic dynamics. While recent work has favored highly expressive implicit generative models such as diffusion and flow-based methods, these approaches are often data-hungry, computationally costly, and misaligned with the structured solution spaces frequently found in scientific problems. We demonstrate that Mixture Density Networks (MDNs) provide a principled yet largely overlooked alternative for multimodal uncertainty quantification in SciML. As explicit parametric density estimators, MDNs impose an inductive bias tailored to low-dimensional, multimodal physics, enabling direct global allocation of probability mass across distinct solution branches. This structure delivers strong data efficiency, allowing reliable recovery of separated modes in regimes where scientific data is scarce. We formalize these insights through a unified probabilistic framework contrasting explicit and implicit distribution networks, and demonstrate empirically that MDNs achieve superior generalization, interpretability, and sample efficiency across a range of inverse, multistable, and chaotic scientific regression tasks.
PhysicsCorrect: A Training-Free Approach for Stable Neural PDE Simulations
Jul 03, 2025



Neural networks have emerged as powerful surrogates for solving partial differential equations (PDEs), offering significant computational speedups over traditional methods. However, these models suffer from a critical limitation: error accumulation during long-term rollouts, where small inaccuracies compound exponentially, eventually causing complete divergence from physically valid solutions. We present PhysicsCorrect, a training-free correction framework that enforces PDE consistency at each prediction step by formulating correction as a linearized inverse problem based on PDE residuals. Our key innovation is an efficient caching strategy that precomputes the Jacobian and its pseudoinverse during an offline warm-up phase, reducing computational overhead by two orders of magnitude compared to standard correction approaches. Across three representative PDE systems -- Navier-Stokes fluid dynamics, wave equations, and the chaotic Kuramoto-Sivashinsky equation -- PhysicsCorrect reduces prediction errors by up to 100x while adding negligible inference time (under 5\%). The framework integrates seamlessly with diverse architectures including Fourier Neural Operators, UNets, and Vision Transformers, effectively transforming unstable neural surrogates into reliable simulation tools that bridge the gap between deep learning's computational efficiency and the physical fidelity demanded by practical scientific applications.
Active Learning Design: Modeling Force Output for Axisymmetric Soft Pneumatic Actuators
Apr 01, 2025Soft pneumatic actuators (SPA) made from elastomeric materials can provide large strain and large force. The behavior of locally strain-restricted hyperelastic materials under inflation has been investigated thoroughly for shape reconfiguration, but requires further investigation for trajectories involving external force. In this work we model force-pressure-height relationships for a concentrically strain-limited class of soft pneumatic actuators and demonstrate the use of this model to design SPA response for object lifting. We predict relationships under different loadings by solving energy minimization equations and verify this theory by using an automated test rig to collect rich data for n=22 Ecoflex 00-30 membranes. We collect this data using an active learning pipeline to efficiently model the design space. We show that this learned material model outperforms the theory-based model and naive curve-fitting approaches. We use our model to optimize membrane design for different lift tasks and compare this performance to other designs. These contributions represent a step towards understanding the natural response for this class of actuator and embodying intelligent lifts in a single-pressure input actuator system.
On conditional diffusion models for PDE simulations
Oct 21, 2024
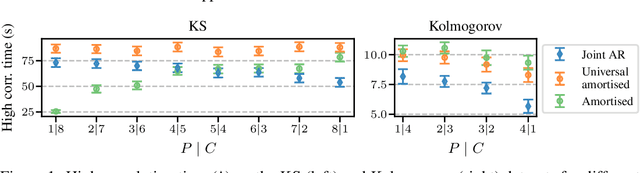
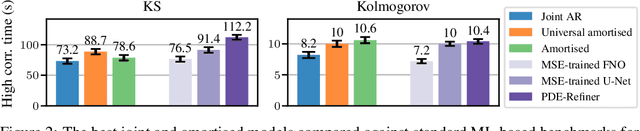

Modelling partial differential equations (PDEs) is of crucial importance in science and engineering, and it includes tasks ranging from forecasting to inverse problems, such as data assimilation. However, most previous numerical and machine learning approaches that target forecasting cannot be applied out-of-the-box for data assimilation. Recently, diffusion models have emerged as a powerful tool for conditional generation, being able to flexibly incorporate observations without retraining. In this work, we perform a comparative study of score-based diffusion models for forecasting and assimilation of sparse observations. In particular, we focus on diffusion models that are either trained in a conditional manner, or conditioned after unconditional training. We address the shortcomings of existing models by proposing 1) an autoregressive sampling approach that significantly improves performance in forecasting, 2) a new training strategy for conditional score-based models that achieves stable performance over a range of history lengths, and 3) a hybrid model which employs flexible pre-training conditioning on initial conditions and flexible post-training conditioning to handle data assimilation. We empirically show that these modifications are crucial for successfully tackling the combination of forecasting and data assimilation, a task commonly encountered in real-world scenarios.
Score Neural Operator: A Generative Model for Learning and Generalizing Across Multiple Probability Distributions
Oct 11, 2024
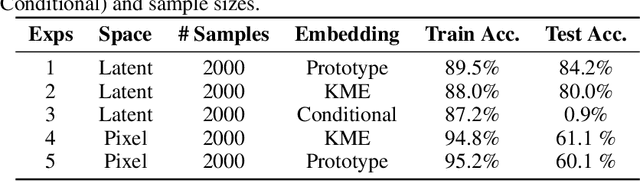
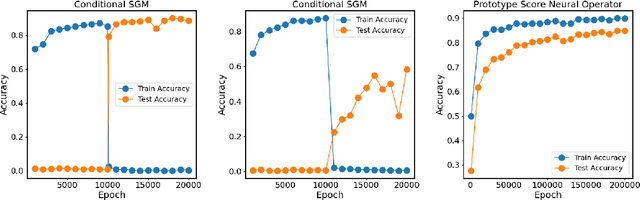
Most existing generative models are limited to learning a single probability distribution from the training data and cannot generalize to novel distributions for unseen data. An architecture that can generate samples from both trained datasets and unseen probability distributions would mark a significant breakthrough. Recently, score-based generative models have gained considerable attention for their comprehensive mode coverage and high-quality image synthesis, as they effectively learn an operator that maps a probability distribution to its corresponding score function. In this work, we introduce the $\emph{Score Neural Operator}$, which learns the mapping from multiple probability distributions to their score functions within a unified framework. We employ latent space techniques to facilitate the training of score matching, which tends to over-fit in the original image pixel space, thereby enhancing sample generation quality. Our trained Score Neural Operator demonstrates the ability to predict score functions of probability measures beyond the training space and exhibits strong generalization performance in both 2-dimensional Gaussian Mixture Models and 1024-dimensional MNIST double-digit datasets. Importantly, our approach offers significant potential for few-shot learning applications, where a single image from a new distribution can be leveraged to generate multiple distinct images from that distribution.
Deep Learning Alternatives of the Kolmogorov Superposition Theorem
Oct 02, 2024
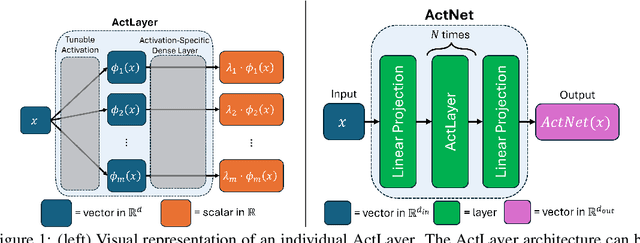
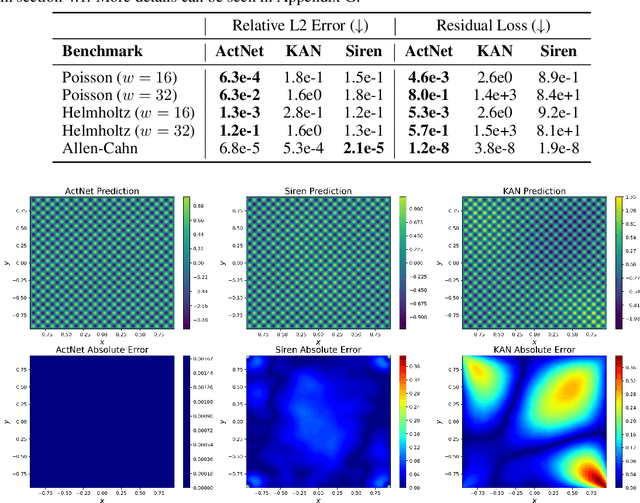
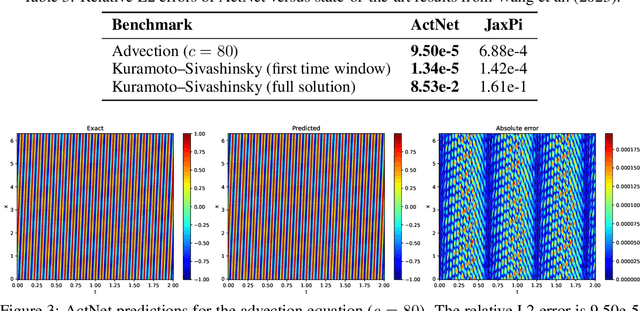
This paper explores alternative formulations of the Kolmogorov Superposition Theorem (KST) as a foundation for neural network design. The original KST formulation, while mathematically elegant, presents practical challenges due to its limited insight into the structure of inner and outer functions and the large number of unknown variables it introduces. Kolmogorov-Arnold Networks (KANs) leverage KST for function approximation, but they have faced scrutiny due to mixed results compared to traditional multilayer perceptrons (MLPs) and practical limitations imposed by the original KST formulation. To address these issues, we introduce ActNet, a scalable deep learning model that builds on the KST and overcomes many of the drawbacks of Kolmogorov's original formulation. We evaluate ActNet in the context of Physics-Informed Neural Networks (PINNs), a framework well-suited for leveraging KST's strengths in low-dimensional function approximation, particularly for simulating partial differential equations (PDEs). In this challenging setting, where models must learn latent functions without direct measurements, ActNet consistently outperforms KANs across multiple benchmarks and is competitive against the current best MLP-based approaches. These results present ActNet as a promising new direction for KST-based deep learning applications, particularly in scientific computing and PDE simulation tasks.