 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoLT: Joint Probabilistic Predictions on Tabular Data Using LLMs
Feb 17, 2025We introduce a simple method for probabilistic predictions on tabular data based on Large Language Models (LLMs) called JoLT (Joint LLM Process for Tabular data). JoLT uses the in-context learning capabilities of LLMs to define joint distributions over tabular data conditioned on user-specified side information about the problem, exploiting the vast repository of latent problem-relevant knowledge encoded in LLMs. JoLT defines joint distributions for multiple target variables with potentially heterogeneous data types without any data conversion, data preprocessing, special handling of missing data, or model training, making it accessible and efficient for practitioners. Our experiments show that JoLT outperforms competitive methods on low-shot single-target and multi-target tabular classification and regression tasks. Furthermore, we show that JoLT can automatically handle missing data and perform data imputation by leveraging textual side information. We argue that due to its simplicity and generality, JoLT is an effective approach for a wide variety of real prediction problems.
On conditional diffusion models for PDE simulations
Oct 21, 2024
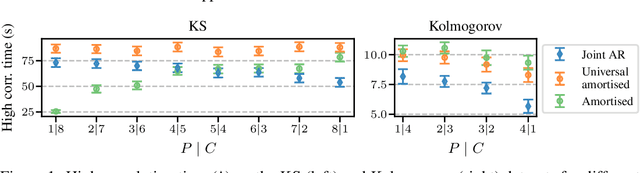
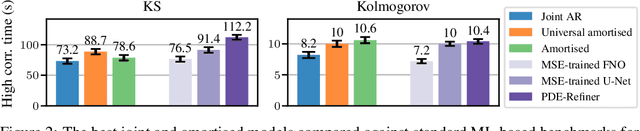

Modelling partial differential equations (PDEs) is of crucial importance in science and engineering, and it includes tasks ranging from forecasting to inverse problems, such as data assimilation. However, most previous numerical and machine learning approaches that target forecasting cannot be applied out-of-the-box for data assimilation. Recently, diffusion models have emerged as a powerful tool for conditional generation, being able to flexibly incorporate observations without retraining. In this work, we perform a comparative study of score-based diffusion models for forecasting and assimilation of sparse observations. In particular, we focus on diffusion models that are either trained in a conditional manner, or conditioned after unconditional training. We address the shortcomings of existing models by proposing 1) an autoregressive sampling approach that significantly improves performance in forecasting, 2) a new training strategy for conditional score-based models that achieves stable performance over a range of history lengths, and 3) a hybrid model which employs flexible pre-training conditioning on initial conditions and flexible post-training conditioning to handle data assimilation. We empirically show that these modifications are crucial for successfully tackling the combination of forecasting and data assimilation, a task commonly encountered in real-world scenarios.
Denoising Diffusion Probabilistic Models in Six Simple Steps
Feb 10, 2024Denoising Diffusion Probabilistic Models (DDPMs) are a very popular class of deep generative model that have been successfully applied to a diverse range of problems including image and video generation, protein and material synthesis, weather forecasting, and neural surrogates of partial differential equations. Despite their ubiquity it is hard to find an introduction to DDPMs which is simple, comprehensive, clean and clear. The compact explanations necessary in research papers are not able to elucidate all of the different design steps taken to formulate the DDPM and the rationale of the steps that are presented is often omitted to save space. Moreover, the expositions are typically presented from the variational lower bound perspective which is unnecessary and arguably harmful as it obfuscates why the method is working and suggests generalisations that do not perform well in practice. On the other hand, perspectives that take the continuous time-limit are beautiful and general, but they have a high barrier-to-entry as they require background knowledge of stochastic differential equations and probability flow. In this note, we distill down the formulation of the DDPM into six simple steps each of which comes with a clear rationale. We assume that the reader is familiar with fundamental topics in machine learning including basic probabilistic modelling, Gaussian distributions, maximum likelihood estimation, and deep learning.
Transformer Neural Autoregressive Flows
Jan 03, 2024



Density estimation, a central problem in machine learning, can be performed using Normalizing Flows (NFs). NFs comprise a sequence of invertible transformations, that turn a complex target distribution into a simple one, by exploiting the change of variables theorem. Neural Autoregressive Flows (NAFs) and Block Neural Autoregressive Flows (B-NAFs) are arguably the most perfomant members of the NF family. However, they suffer scalability issues and training instability due to the constraints imposed on the network structure. In this paper, we propose a novel solution to these challenges by exploiting transformers to define a new class of neural flows called Transformer Neural Autoregressive Flows (T-NAFs). T-NAFs treat each dimension of a random variable as a separate input token, using attention masking to enforce an autoregressive constraint. We take an amortization-inspired approach where the transformer outputs the parameters of an invertible transformation. The experimental results demonstrate that T-NAFs consistently match or outperform NAFs and B-NAFs across multiple datasets from the UCI benchmark. Remarkably, T-NAFs achieve these results using an order of magnitude fewer parameters than previous approaches, without composing multiple flows.
Diffusion-Augmented Neural Processes
Nov 16, 2023Over the last few years, Neural Processes have become a useful modelling tool in many application areas, such as healthcare and climate sciences, in which data are scarce and prediction uncertainty estimates are indispensable. However, the current state of the art in the field (AR CNPs; Bruinsma et al., 2023) presents a few issues that prevent its widespread deployment. This work proposes an alternative, diffusion-based approach to NPs which, through conditioning on noised datasets, addresses many of these limitations, whilst also exceeding SOTA performance.
On the Efficacy of Differentially Private Few-shot Image Classification
Feb 02, 2023There has been significant recent progress in training differentially private (DP) models which achieve accuracy that approaches the best non-private models. These DP models are typically pretrained on large public datasets and then fine-tuned on downstream datasets that are (i) relatively large, and (ii) similar in distribution to the pretraining data. However, in many applications including personalization, it is crucial to perform well in the few-shot setting, as obtaining large amounts of labeled data may be problematic; and on images from a wide variety of domains for use in various specialist settings. To understand under which conditions few-shot DP can be effective, we perform an exhaustive set of experiments that reveals how the accuracy and vulnerability to attack of few-shot DP image classification models are affected as the number of shots per class, privacy level, model architecture, dataset, and subset of learnable parameters in the model vary. We show that to achieve DP accuracy on par with non-private models, the shots per class must be increased as the privacy level increases by as much as 32$\times$ for CIFAR-100 at $\epsilon=1$. We also find that few-shot non-private models are highly susceptible to membership inference attacks. DP provides clear mitigation against the attacks, but a small $\epsilon$ is required to effectively prevent them. Finally, we evaluate DP federated learning systems and establish state-of-the-art performance on the challenging FLAIR federated learning benchmark.
Contextual Squeeze-and-Excitation for Efficient Few-Shot Image Classification
Jun 20, 2022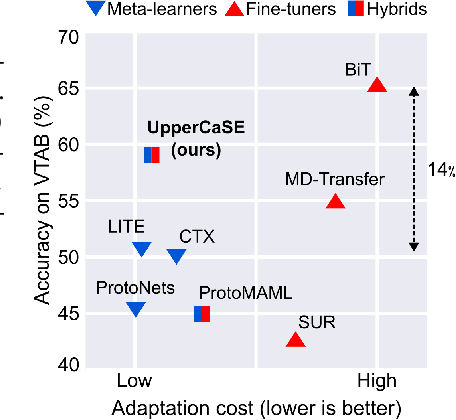
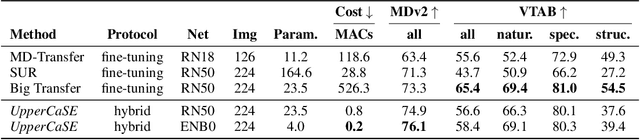
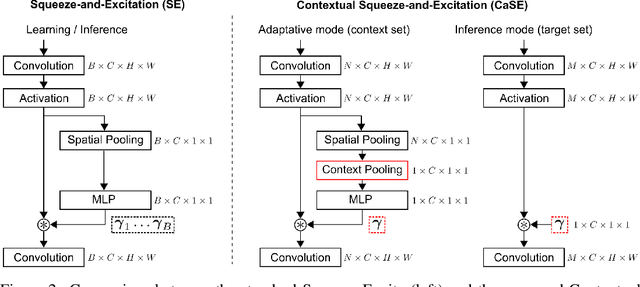
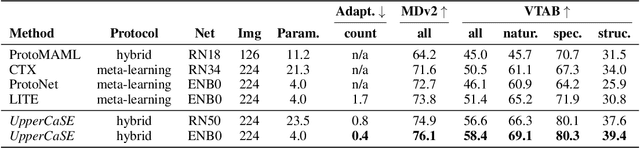
Recent years have seen a growth in user-centric applications that require effective knowledge transfer across tasks in the low-data regime. An example is personalization, where a pretrained system is adapted by learning on small amounts of labeled data belonging to a specific user. This setting requires high accuracy under low computational complexity, therefore the Pareto frontier of accuracy vs.~adaptation cost plays a crucial role. In this paper we push this Pareto frontier in the few-shot image classification setting with two key contributions: (i) a new adaptive block called Contextual Squeeze-and-Excitation (CaSE) that adjusts a pretrained neural network on a new task to significantly improve performance with a single forward pass of the user data (context), and (ii) a hybrid training protocol based on Coordinate-Descent called UpperCaSE that exploits meta-trained CaSE blocks and fine-tuning routines for efficient adaptation. UpperCaSE achieves a new state-of-the-art accuracy relative to meta-learners on the 26 datasets of VTAB+MD and on a challenging real-world personalization benchmark (ORBIT), narrowing the gap with leading fine-tuning methods with the benefit of orders of magnitude lower adaptation cost.
FiT: Parameter Efficient Few-shot Transfer Learning for Personalized and Federated Image Classification
Jun 17, 2022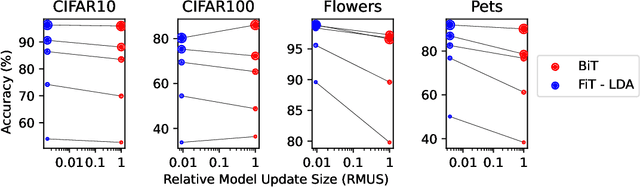
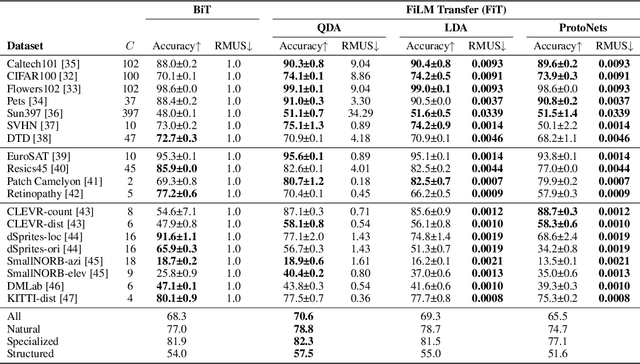

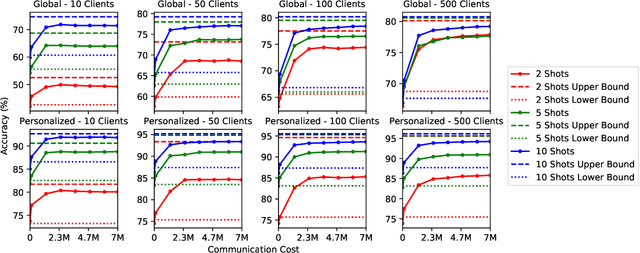
Modern deep learning systems are increasingly deployed in situations such as personalization and federated learning where it is necessary to support i) learning on small amounts of data, and ii) communication efficient distributed training protocols. In this work we develop FiLM Transfer (FiT) which fulfills these requirements in the image classification setting. FiT uses an automatically configured Naive Bayes classifier on top of a fixed backbone that has been pretrained on large image datasets. Parameter efficient FiLM layers are used to modulate the backbone, shaping the representation for the downstream task. The network is trained via an episodic fine-tuning protocol. The approach is parameter efficient which is key for enabling few-shot learning, inexpensive model updates for personalization, and communication efficient federated learning. We experiment with FiT on a wide range of downstream datasets and show that it achieves better classification accuracy than the state-of-the-art Big Transfer (BiT) algorithm at low-shot and on the challenging VTAB-1k benchmark, with fewer than 1% of the updateable parameters. Finally, we demonstrate the parameter efficiency of FiT in distributed low-shot applications including model personalization and federated learning where model update size is an important performance metric.
Fast Bi-layer Neural Synthesis of One-Shot Realistic Head Avatars
Aug 24, 2020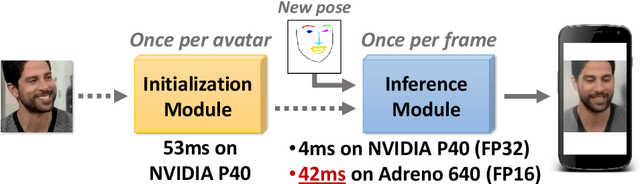
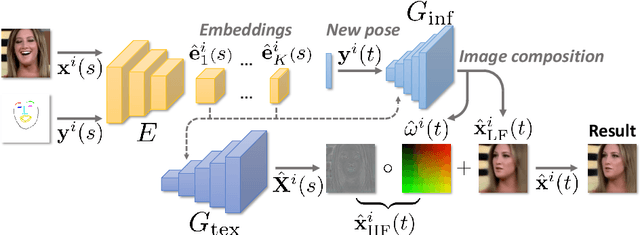
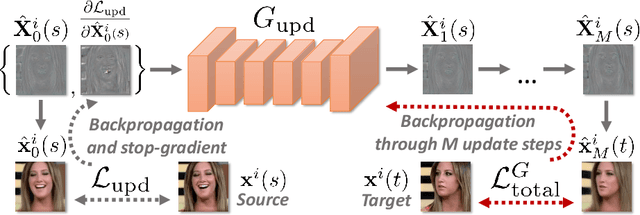
We propose a neural rendering-based system that creates head avatars from a single photograph. Our approach models a person's appearance by decomposing it into two layers. The first layer is a pose-dependent coarse image that is synthesized by a small neural network. The second layer is defined by a pose-independent texture image that contains high-frequency details. The texture image is generated offline, warped and added to the coarse image to ensure a high effective resolution of synthesized head views. We compare our system to analogous state-of-the-art systems in terms of visual quality and speed. The experiments show significant inference speedup over previous neural head avatar models for a given visual quality. We also report on a real-time smartphone-based implementation of our system.
Textured Neural Avatars
May 21, 2019
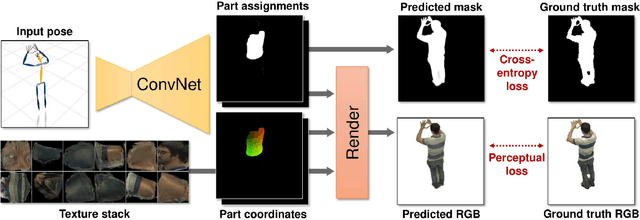


We present a system for learning full-body neural avatars, i.e. deep networks that produce full-body renderings of a person for varying body pose and camera position. Our system takes the middle path between the classical graphics pipeline and the recent deep learning approaches that generate images of humans using image-to-image translation. In particular, our system estimates an explicit two-dimensional texture map of the model surface. At the same time, it abstains from explicit shape modeling in 3D. Instead, at test time, the system uses a fully-convolutional network to directly map the configuration of body feature points w.r.t. the camera to the 2D texture coordinates of individual pixels in the image frame. We show that such a system is capable of learning to generate realistic renderings while being trained on videos annotated with 3D poses and foreground masks. We also demonstrate that maintaining an explicit texture representation helps our system to achieve better generalization compared to systems that use direct image-to-image translation.