 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Depth Denoising Using Lower- and Higher-quality RGB-D sensors
Sep 13, 2020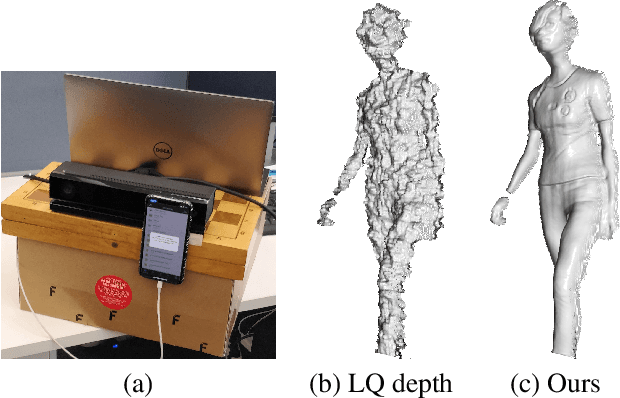

Consumer-level depth cameras and depth sensors embedded in mobile devices enable numerous applications, such as AR games and face identification. However, the quality of the captured depth is sometimes insufficient for 3D reconstruction, tracking and other computer vision tasks. In this paper, we propose a self-supervised depth denoising approach to denoise and refine depth coming from a low quality sensor. We record simultaneous RGB-D sequences with unzynchronized lower- and higher-quality cameras and solve a challenging problem of aligning sequences both temporally and spatially. We then learn a deep neural network to denoise the lower-quality depth using the matched higher-quality data as a source of supervision signal. We experimentally validate our method against state-of-the-art filtering-based and deep denoising techniques and show its application for 3D object reconstruction tasks where our approach leads to more detailed fused surfaces and better tracking.
Neural Head Reenactment with Latent Pose Descriptors
Apr 24, 2020
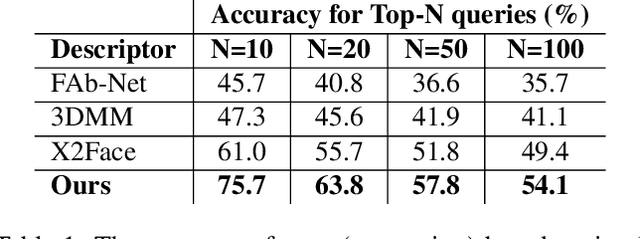
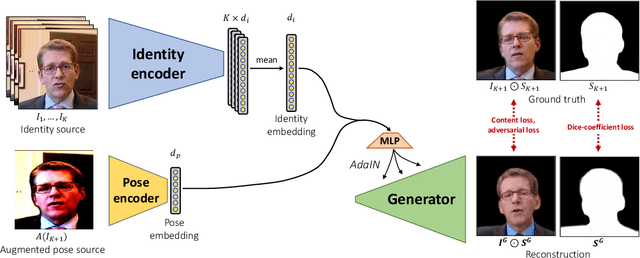

We propose a neural head reenactment system, which is driven by a latent pose representation and is capable of predicting the foreground segmentation alongside the RGB image. The latent pose representation is learned as a part of the entire reenactment system, and the learning process is based solely on image reconstruction losses. We show that despite its simplicity, with a large and diverse enough training dataset, such learning successfully decomposes pose from identity. The resulting system can then reproduce mimics of the driving person and, furthermore, can perform cross-person reenactment. Additionally, we show that the learned descriptors are useful for other pose-related tasks, such as keypoint prediction and pose-based retrieval.
Textured Neural Avatars
May 21, 2019
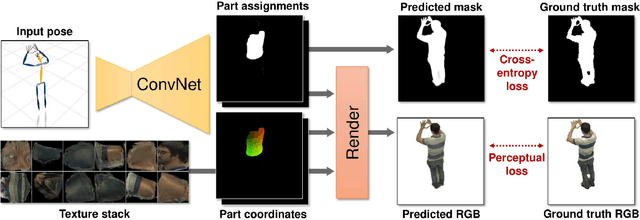


We present a system for learning full-body neural avatars, i.e. deep networks that produce full-body renderings of a person for varying body pose and camera position. Our system takes the middle path between the classical graphics pipeline and the recent deep learning approaches that generate images of humans using image-to-image translation. In particular, our system estimates an explicit two-dimensional texture map of the model surface. At the same time, it abstains from explicit shape modeling in 3D. Instead, at test time, the system uses a fully-convolutional network to directly map the configuration of body feature points w.r.t. the camera to the 2D texture coordinates of individual pixels in the image frame. We show that such a system is capable of learning to generate realistic renderings while being trained on videos annotated with 3D poses and foreground masks. We also demonstrate that maintaining an explicit texture representation helps our system to achieve better generalization compared to systems that use direct image-to-image translation.