 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Depth Denoising Using Lower- and Higher-quality RGB-D sensors
Sep 13, 2020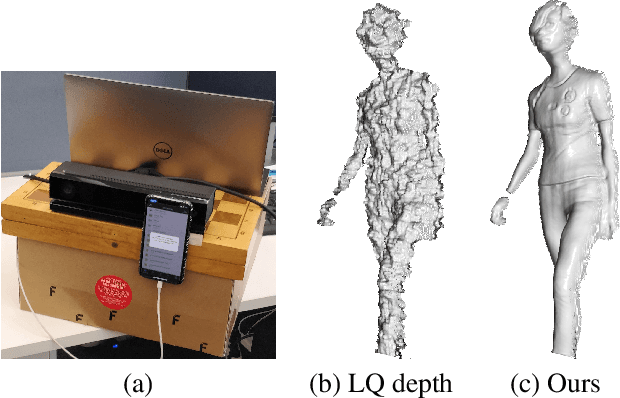

Consumer-level depth cameras and depth sensors embedded in mobile devices enable numerous applications, such as AR games and face identification. However, the quality of the captured depth is sometimes insufficient for 3D reconstruction, tracking and other computer vision tasks. In this paper, we propose a self-supervised depth denoising approach to denoise and refine depth coming from a low quality sensor. We record simultaneous RGB-D sequences with unzynchronized lower- and higher-quality cameras and solve a challenging problem of aligning sequences both temporally and spatially. We then learn a deep neural network to denoise the lower-quality depth using the matched higher-quality data as a source of supervision signal. We experimentally validate our method against state-of-the-art filtering-based and deep denoising techniques and show its application for 3D object reconstruction tasks where our approach leads to more detailed fused surfaces and better tracking.
Precipitation Nowcasting with Satellite Imagery
May 23, 2019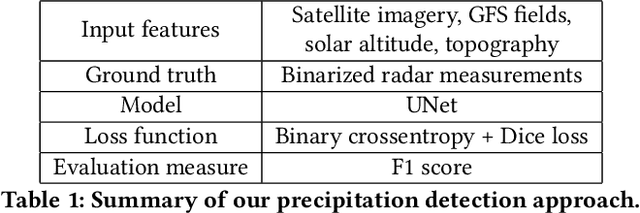
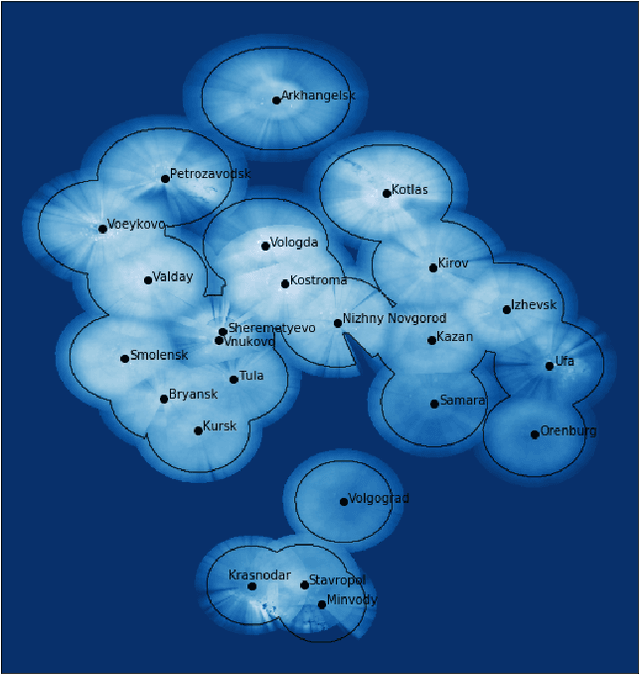
Precipitation nowcasting is a short-range forecast of rain/snow (up to 2 hours), often displayed on top of the geographical map by the weather service. Modern precipitation nowcasting algorithms rely on the extrapolation of observations by ground-based radars via optical flow techniques or neural network models. Dependent on these radars, typical nowcasting is limited to the regions around their locations. We have developed a method for precipitation nowcasting based on geostationary satellite imagery and incorporated the resulting data into the Yandex.Weather precipitation map (including an alerting service with push notifications for products in the Yandex ecosystem), thus expanding its coverage and paving the way to a truly global nowcasting service.
Spatiotemporal Data Fusion for Precipitation Nowcasting
Dec 28, 2018

Precipitation nowcasting using neural networks and ground-based radars has become one of the key components of modern weather prediction services, but it is limited to the regions covered by ground-based radars. Truly global precipitation nowcasting requires fusion of radar and satellite observations. We propose the data fusion pipeline based on computer vision techniques, including novel inpainting algorithm with soft masking.
Impostor Networks for Fast Fine-Grained Recognition
Jun 13, 2018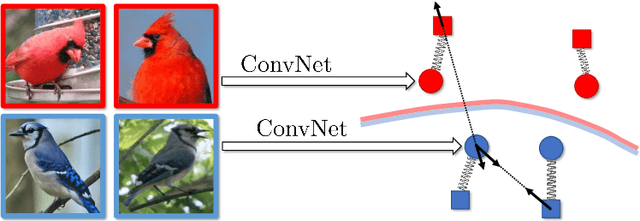
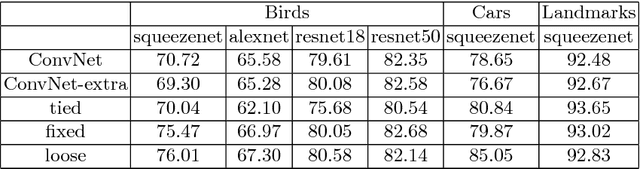
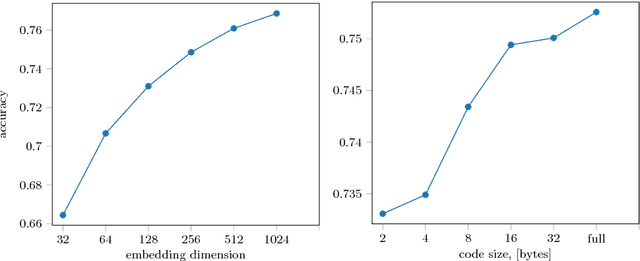

In this work we introduce impostor networks, an architecture that allows to perform fine-grained recognition with high accuracy and using a light-weight convolutional network, making it particularly suitable for fine-grained applications on low-power and non-GPU enabled platforms. Impostor networks compensate for the lightness of its `backend' network by combining it with a lightweight non-parametric classifier. The combination of a convolutional network and such non-parametric classifier is trained in an end-to-end fashion. Similarly to convolutional neural networks, impostor networks can fit large-scale training datasets very well, while also being able to generalize to new data points. At the same time, the bulk of computations within impostor networks happen through nearest neighbor search in high-dimensions. Such search can be performed efficiently on a variety of architectures including standard CPUs, where deep convolutional networks are inefficient. In a series of experiments with three fine-grained datasets, we show that impostor networks are able to boost the classification accuracy of a moderate-sized convolutional network considerably at a very small computational cost.
Learnable Visual Markers
Oct 28, 2016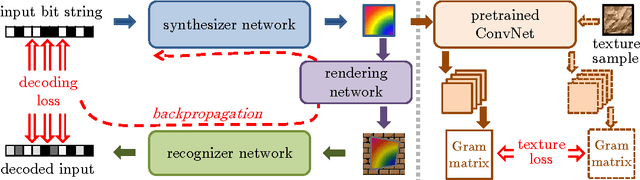

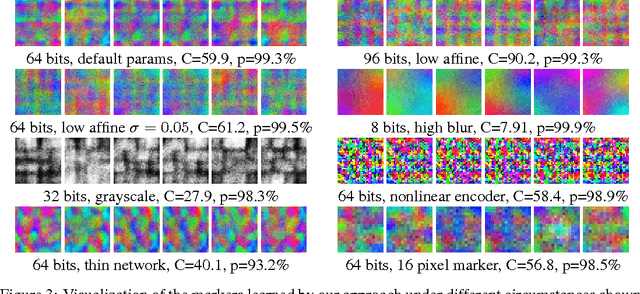
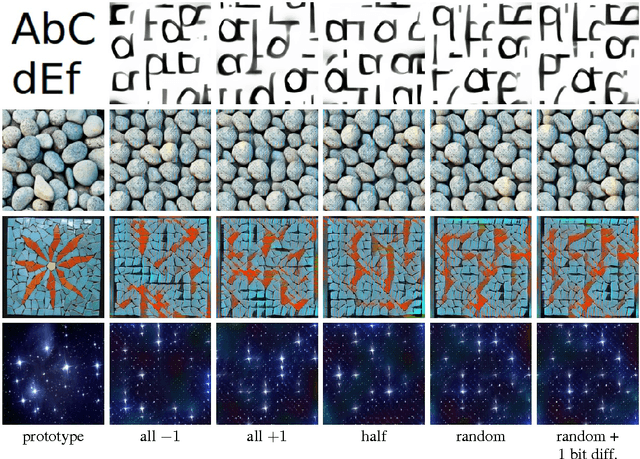
We propose a new approach to designing visual markers (analogous to QR-codes, markers for augmented reality, and robotic fiducial tags) based on the advances in deep generative networks. In our approach, the markers are obtained as color images synthesized by a deep network from input bit strings, whereas another deep network is trained to recover the bit strings back from the photos of these markers. The two networks are trained simultaneously in a joint backpropagation process that takes characteristic photometric and geometric distortions associated with marker fabrication and marker scanning into account. Additionally, a stylization loss based on statistics of activations in a pretrained classification network can be inserted into the learning in order to shift the marker appearance towards some texture prototype. In the experiments, we demonstrate that the markers obtained using our approach are capable of retaining bit strings that are long enough to be practical. The ability to automatically adapt markers according to the usage scenario and the desired capacity as well as the ability to combine information encoding with artistic stylization are the unique properties of our approach. As a byproduct, our approach provides an insight on the structure of patterns that are most suitable for recognition by ConvNets and on their ability to distinguish composite patterns.
Texture Networks: Feed-forward Synthesis of Textures and Stylized Images
Mar 10, 2016
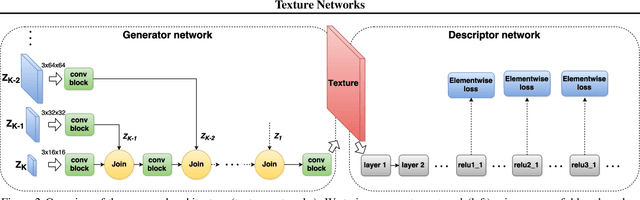


Gatys et al. recently demonstrated that deep networks can generate beautiful textures and stylized images from a single texture example. However, their methods requires a slow and memory-consuming optimization process. We propose here an alternative approach that moves the computational burden to a learning stage. Given a single example of a texture, our approach trains compact feed-forward convolutional networks to generate multiple samples of the same texture of arbitrary size and to transfer artistic style from a given image to any other image. The resulting networks are remarkably light-weight and can generate textures of quality comparable to Gatys~et~al., but hundreds of times faster. More generally, our approach highlights the power and flexibility of generative feed-forward models trained with complex and expressive loss functions.
Fast ConvNets Using Group-wise Brain Damage
Dec 07, 2015

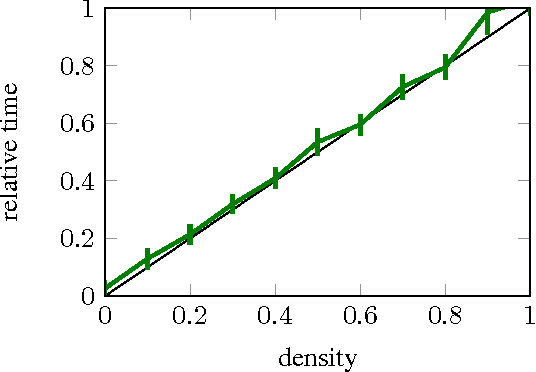
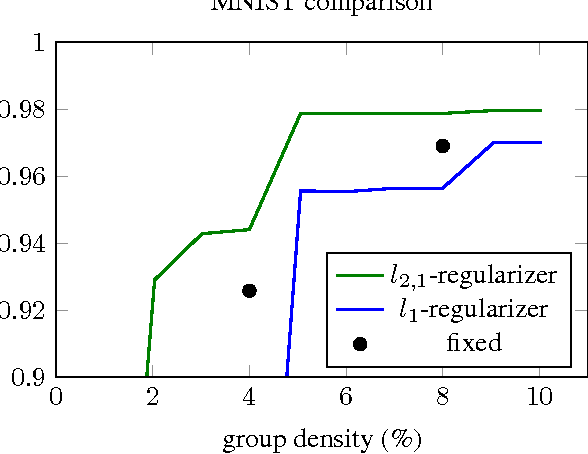
We revisit the idea of brain damage, i.e. the pruning of the coefficients of a neural network, and suggest how brain damage can be modified and used to speedup convolutional layers. The approach uses the fact that many efficient implementations reduce generalized convolutions to matrix multiplications. The suggested brain damage process prunes the convolutional kernel tensor in a group-wise fashion by adding group-sparsity regularization to the standard training process. After such group-wise pruning, convolutions can be reduced to multiplications of thinned dense matrices, which leads to speedup. In the comparison on AlexNet, the method achieves very competitive performance.
Speeding-up Convolutional Neural Networks Using Fine-tuned CP-Decomposition
Apr 24, 2015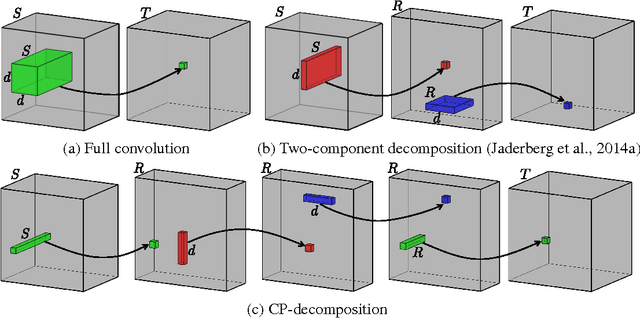

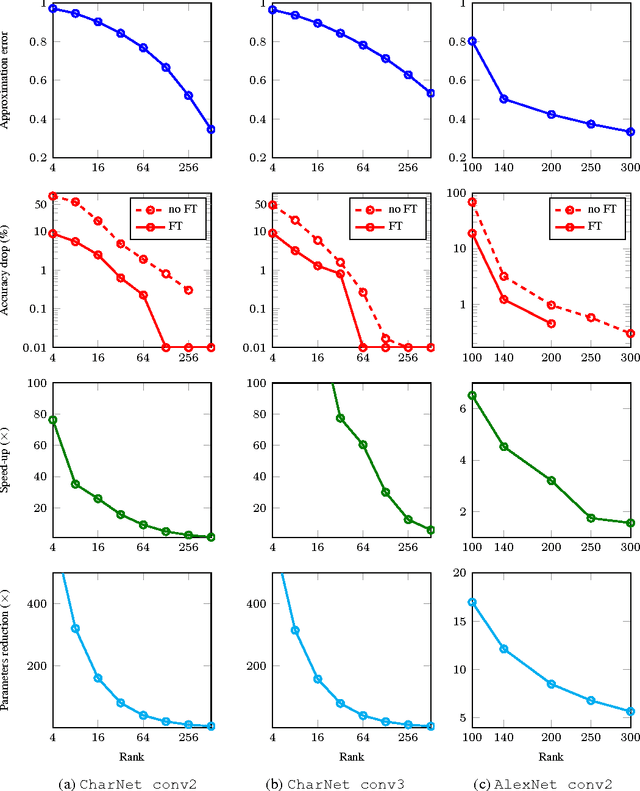
We propose a simple two-step approach for speeding up convolution layers within large convolutional neural networks based on tensor decomposition and discriminative fine-tuning. Given a layer, we use non-linear least squares to compute a low-rank CP-decomposition of the 4D convolution kernel tensor into a sum of a small number of rank-one tensors. At the second step, this decomposition is used to replace the original convolutional layer with a sequence of four convolutional layers with small kernels. After such replacement, the entire network is fine-tuned on the training data using standard backpropagation process. We evaluate this approach on two CNNs and show that it is competitive with previous approaches, leading to higher obtained CPU speedups at the cost of lower accuracy drops for the smaller of the two networks. Thus, for the 36-class character classification CNN, our approach obtains a 8.5x CPU speedup of the whole network with only minor accuracy drop (1% from 91% to 90%). For the standard ImageNet architecture (AlexNet), the approach speeds up the second convolution layer by a factor of 4x at the cost of $1\%$ increase of the overall top-5 classification error.