Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast ConvNets Using Group-wise Brain Damage
Paper and Code
Dec 07, 2015

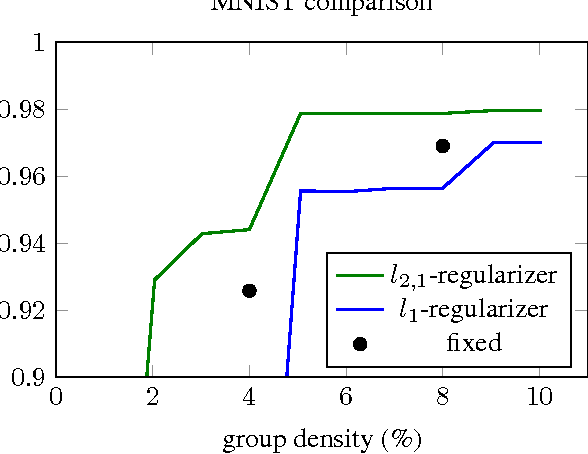
We revisit the idea of brain damage, i.e. the pruning of the coefficients of a neural network, and suggest how brain damage can be modified and used to speedup convolutional layers. The approach uses the fact that many efficient implementations reduce generalized convolutions to matrix multiplications. The suggested brain damage process prunes the convolutional kernel tensor in a group-wise fashion by adding group-sparsity regularization to the standard training process. After such group-wise pruning, convolutions can be reduced to multiplications of thinned dense matrices, which leads to speedup. In the comparison on AlexNet, the method achieves very competitive performance.
View paper on