 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting graph measure performance for node clustering in LFR parameter space
Feb 20, 2022
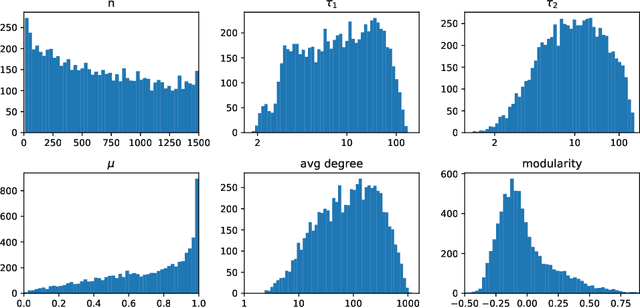


Graph measures that express closeness or distance between nodes can be employed for graph nodes clustering using metric clustering algorithms. There are numerous measures applicable to this task, and which one performs better is an open question. We study the performance of 25 graph measures on generated graphs with different parameters. While usually measure comparisons are limited to general measure ranking on a particular dataset, we aim to explore the performance of various measures depending on graph features. Using an LFR graph generator, we create a dataset of 11780 graphs covering the whole LFR parameter space. For each graph, we assess the quality of clustering with k-means algorithm for each considered measure. Based on this, we determine the best measure for each area of the parameter space. We find that the parameter space consists of distinct zones where one particular measure is the best. We analyze the geometry of the resulting zones and describe it with simple criteria. Given particular graph parameters, this allows us to recommend a particular measure to use for clustering.
* Preprint Complex Networks and their Applications 2021 | CNA 2021
Image-to-image Neural Network for Addition and Subtraction of a Pair of Not Very Large Numbers
Mar 14, 2020

Looking back at the history of calculators, one can see that they become less functional and more computationally expensive over time. A modern calculator runs on a personal computer and is drawn at 60 fps only to help us click a few digits with a mouse pointer. A search engine is often used as a calculator, which means that nowadays we need the Internet just to add two numbers. In this paper, we propose to go further and train a convolutional neural network that takes an image of a simple mathematical expression and generates an image of an answer. This neural calculator works only with pairs of double-digit numbers and supports only addition and subtraction. Also, sometimes it makes mistakes. We promise that the proposed calculator is a small step for man, but one giant leap for mankind.
StyleGAN2 Distillation for Feed-forward Image Manipulation
Mar 07, 2020



StyleGAN2 is a state-of-the-art network in generating realistic images. Besides, it was explicitly trained to have disentangled directions in latent space, which allows efficient image manipulation by varying latent factors. Editing existing images requires embedding a given image into the latent space of StyleGAN2. Latent code optimization via backpropagation is commonly used for qualitative embedding of real world images, although it is prohibitively slow for many applications. We propose a way to distill a particular image manipulation of StyleGAN2 into image-to-image network trained in paired way. The resulting pipeline is an alternative to existing GANs, trained on unpaired data. We provide results of human faces' transformation: gender swap, aging/rejuvenation, style transfer and image morphing. We show that the quality of generation using our method is comparable to StyleGAN2 backpropagation and current state-of-the-art methods in these particular tasks.
Precipitation Nowcasting with Satellite Imagery
May 23, 2019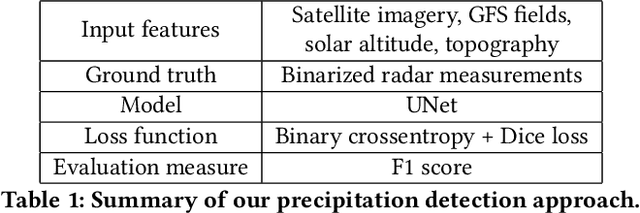
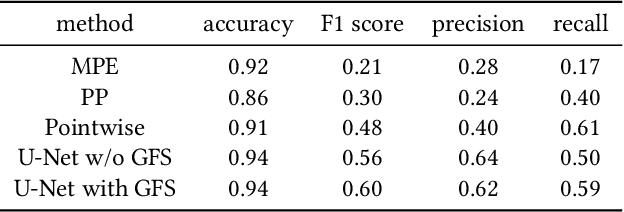
Precipitation nowcasting is a short-range forecast of rain/snow (up to 2 hours), often displayed on top of the geographical map by the weather service. Modern precipitation nowcasting algorithms rely on the extrapolation of observations by ground-based radars via optical flow techniques or neural network models. Dependent on these radars, typical nowcasting is limited to the regions around their locations. We have developed a method for precipitation nowcasting based on geostationary satellite imagery and incorporated the resulting data into the Yandex.Weather precipitation map (including an alerting service with push notifications for products in the Yandex ecosystem), thus expanding its coverage and paving the way to a truly global nowcasting service.
Spatiotemporal Data Fusion for Precipitation Nowcasting
Dec 28, 2018

Precipitation nowcasting using neural networks and ground-based radars has become one of the key components of modern weather prediction services, but it is limited to the regions covered by ground-based radars. Truly global precipitation nowcasting requires fusion of radar and satellite observations. We propose the data fusion pipeline based on computer vision techniques, including novel inpainting algorithm with soft masking.
Do logarithmic proximity measures outperform plain ones in graph clustering?
Feb 18, 2017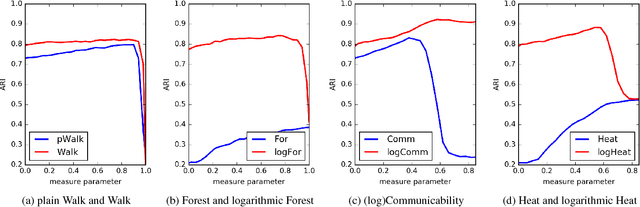

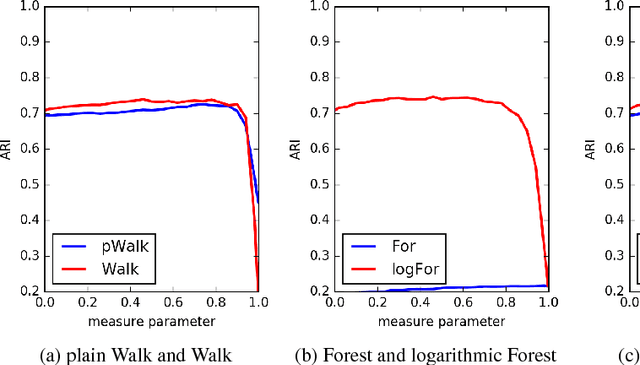
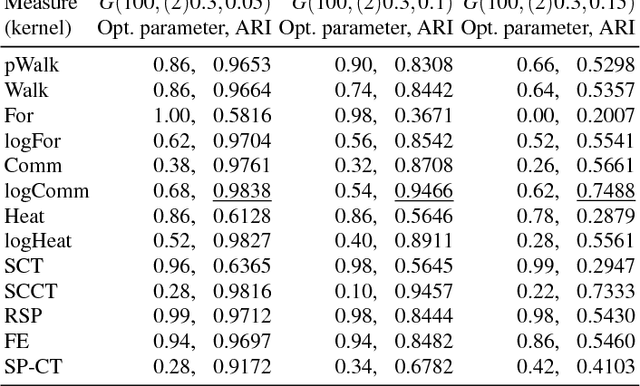
We consider a number of graph kernels and proximity measures including commute time kernel, regularized Laplacian kernel, heat kernel, exponential diffusion kernel (also called "communicability"), etc., and the corresponding distances as applied to clustering nodes in random graphs and several well-known datasets. The model of generating random graphs involves edge probabilities for the pairs of nodes that belong to the same class or different predefined classes of nodes. It turns out that in most cases, logarithmic measures (i.e., measures resulting after taking logarithm of the proximities) perform better while distinguishing underlying classes than the "plain" measures. A comparison in terms of reject curves of inter-class and intra-class distances confirms this conclusion. A similar conclusion can be made for several well-known datasets. A possible origin of this effect is that most kernels have a multiplicative nature, while the nature of distances used in cluster algorithms is an additive one (cf. the triangle inequality). The logarithmic transformation is a tool to transform the first nature to the second one. Moreover, some distances corresponding to the logarithmic measures possess a meaningful cutpoint additivity property. In our experiments, the leader is usually the logarithmic Communicability measure. However, we indicate some more complicated cases in which other measures, typically, Communicability and plain Walk, can be the winners.