 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Depth Denoising Using Lower- and Higher-quality RGB-D sensors
Sep 13, 2020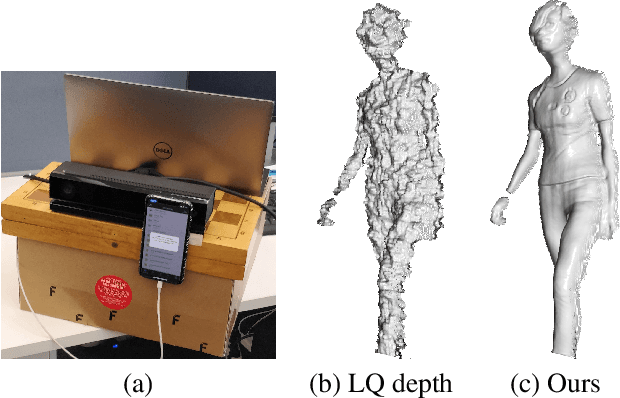

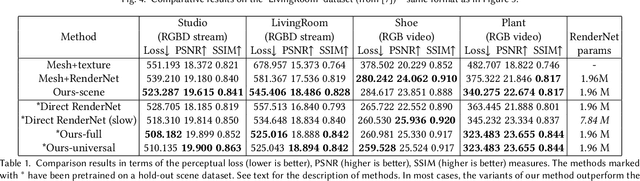
Consumer-level depth cameras and depth sensors embedded in mobile devices enable numerous applications, such as AR games and face identification. However, the quality of the captured depth is sometimes insufficient for 3D reconstruction, tracking and other computer vision tasks. In this paper, we propose a self-supervised depth denoising approach to denoise and refine depth coming from a low quality sensor. We record simultaneous RGB-D sequences with unzynchronized lower- and higher-quality cameras and solve a challenging problem of aligning sequences both temporally and spatially. We then learn a deep neural network to denoise the lower-quality depth using the matched higher-quality data as a source of supervision signal. We experimentally validate our method against state-of-the-art filtering-based and deep denoising techniques and show its application for 3D object reconstruction tasks where our approach leads to more detailed fused surfaces and better tracking.
Neural Point-Based Graphics
Jul 16, 2019


We present a new point-based approach for modeling complex scenes. The approach uses a raw point cloud as the geometric representation of a scene, and augments each point with a learnable neural descriptor that encodes local geometry and appearance. A deep rendering network is learned in parallel with the descriptors, so that new views of the scene can be obtained by passing the rasterizations of a point cloud from new viewpoints through this network. The input rasterizations use the learned descriptors as point pseudo-colors. We show that the proposed approach can be used for modeling complex scenes and obtaining their photorealistic views, while avoiding explicit surface estimation and meshing. In particular, compelling results are obtained for scene scanned using hand-held commodity RGB-D sensors as well as standard RGB cameras even in the presence of objects that are challenging for standard mesh-based modeling.
Textured Neural Avatars
May 21, 2019
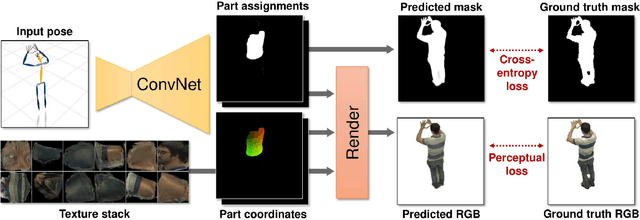


We present a system for learning full-body neural avatars, i.e. deep networks that produce full-body renderings of a person for varying body pose and camera position. Our system takes the middle path between the classical graphics pipeline and the recent deep learning approaches that generate images of humans using image-to-image translation. In particular, our system estimates an explicit two-dimensional texture map of the model surface. At the same time, it abstains from explicit shape modeling in 3D. Instead, at test time, the system uses a fully-convolutional network to directly map the configuration of body feature points w.r.t. the camera to the 2D texture coordinates of individual pixels in the image frame. We show that such a system is capable of learning to generate realistic renderings while being trained on videos annotated with 3D poses and foreground masks. We also demonstrate that maintaining an explicit texture representation helps our system to achieve better generalization compared to systems that use direct image-to-image translation.
Generative Models for Fast Calorimeter Simulation.LHCb case
Dec 04, 2018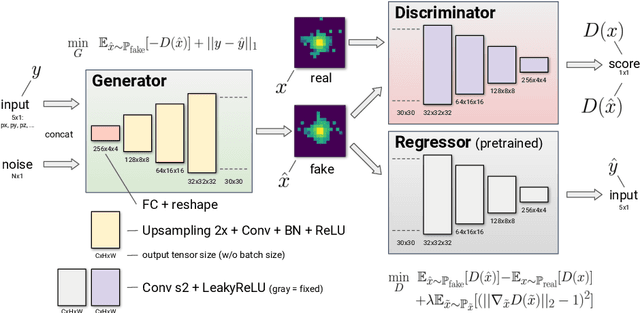
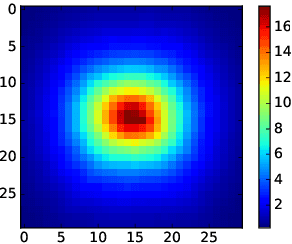
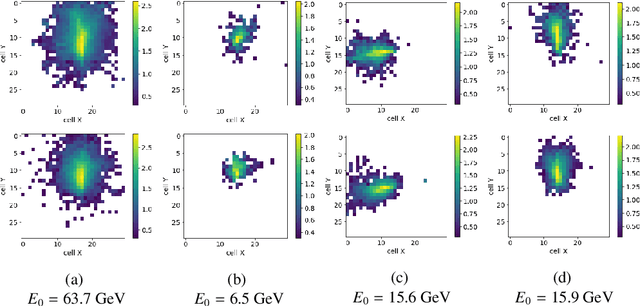
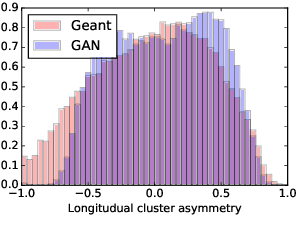
Simulation is one of the key components in high energy physics. Historically it relies on the Monte Carlo methods which require a tremendous amount of computation resources. These methods may have difficulties with the expected High Luminosity Large Hadron Collider (HL LHC) need, so the experiment is in urgent need of new fast simulation techniques. We introduce a new Deep Learning framework based on Generative Adversarial Networks which can be faster than traditional simulation methods by 5 order of magnitude with reasonable simulation accuracy. This approach will allow physicists to produce a big enough amount of simulated data needed by the next HL LHC experiments using limited computing resources.
Image Manipulation with Perceptual Discriminators
Sep 05, 2018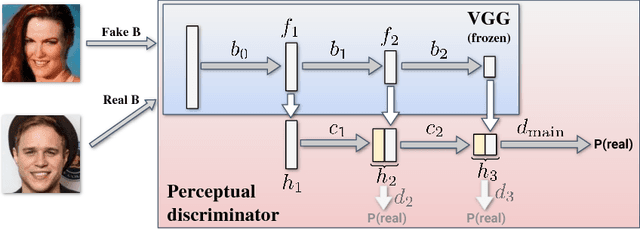
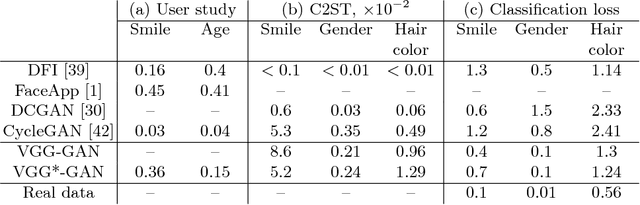


Systems that perform image manipulation using deep convolutional networks have achieved remarkable realism. Perceptual losses and losses based on adversarial discriminators are the two main classes of learning objectives behind these advances. In this work, we show how these two ideas can be combined in a principled and non-additive manner for unaligned image translation tasks. This is accomplished through a special architecture of the discriminator network inside generative adversarial learning framework. The new architecture, that we call a perceptual discriminator, embeds the convolutional parts of a pre-trained deep classification network inside the discriminator network. The resulting architecture can be trained on unaligned image datasets while benefiting from the robustness and efficiency of perceptual losses. We demonstrate the merits of the new architecture in a series of qualitative and quantitative comparisons with baseline approaches and state-of-the-art frameworks for unaligned image translation.
Deep Image Prior
Apr 05, 2018

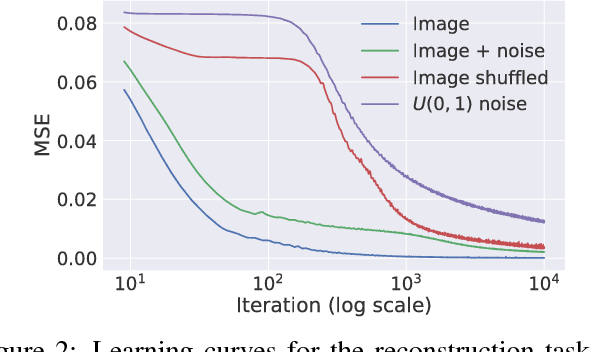
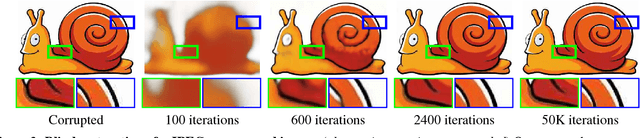
Deep convolutional networks have become a popular tool for image generation and restoration. Generally, their excellent performance is imputed to their ability to learn realistic image priors from a large number of example images. In this paper, we show that, on the contrary, the structure of a generator network is sufficient to capture a great deal of low-level image statistics prior to any learning. In order to do so, we show that a randomly-initialized neural network can be used as a handcrafted prior with excellent results in standard inverse problems such as denoising, super-resolution, and inpainting. Furthermore, the same prior can be used to invert deep neural representations to diagnose them, and to restore images based on flash-no flash input pairs. Apart from its diverse applications, our approach highlights the inductive bias captured by standard generator network architectures. It also bridges the gap between two very popular families of image restoration methods: learning-based methods using deep convolutional networks and learning-free methods based on handcrafted image priors such as self-similarity. Code and supplementary material are available at https://dmitryulyanov.github.io/deep_image_prior .
It Takes (Only) Two: Adversarial Generator-Encoder Networks
Nov 06, 2017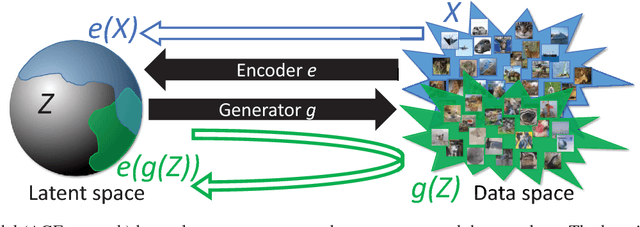



We present a new autoencoder-type architecture that is trainable in an unsupervised mode, sustains both generation and inference, and has the quality of conditional and unconditional samples boosted by adversarial learning. Unlike previous hybrids of autoencoders and adversarial networks, the adversarial game in our approach is set up directly between the encoder and the generator, and no external mappings are trained in the process of learning. The game objective compares the divergences of each of the real and the generated data distributions with the prior distribution in the latent space. We show that direct generator-vs-encoder game leads to a tight coupling of the two components, resulting in samples and reconstructions of a comparable quality to some recently-proposed more complex architectures.
Improved Texture Networks: Maximizing Quality and Diversity in Feed-forward Stylization and Texture Synthesis
Nov 06, 2017

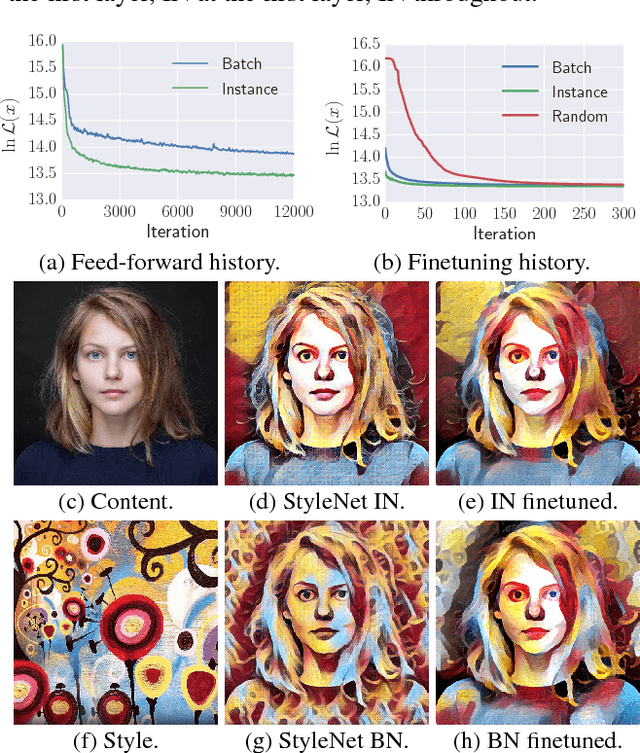

The recent work of Gatys et al., who characterized the style of an image by the statistics of convolutional neural network filters, ignited a renewed interest in the texture generation and image stylization problems. While their image generation technique uses a slow optimization process, recently several authors have proposed to learn generator neural networks that can produce similar outputs in one quick forward pass. While generator networks are promising, they are still inferior in visual quality and diversity compared to generation-by-optimization. In this work, we advance them in two significant ways. First, we introduce an instance normalization module to replace batch normalization with significant improvements to the quality of image stylization. Second, we improve diversity by introducing a new learning formulation that encourages generators to sample unbiasedly from the Julesz texture ensemble, which is the equivalence class of all images characterized by certain filter responses. Together, these two improvements take feed forward texture synthesis and image stylization much closer to the quality of generation-via-optimization, while retaining the speed advantage.
Instance Normalization: The Missing Ingredient for Fast Stylization
Nov 06, 2017



It this paper we revisit the fast stylization method introduced in Ulyanov et. al. (2016). We show how a small change in the stylization architecture results in a significant qualitative improvement in the generated images. The change is limited to swapping batch normalization with instance normalization, and to apply the latter both at training and testing times. The resulting method can be used to train high-performance architectures for real-time image generation. The code will is made available on github at https://github.com/DmitryUlyanov/texture_nets. Full paper can be found at arXiv:1701.02096.
Texture Networks: Feed-forward Synthesis of Textures and Stylized Images
Mar 10, 2016
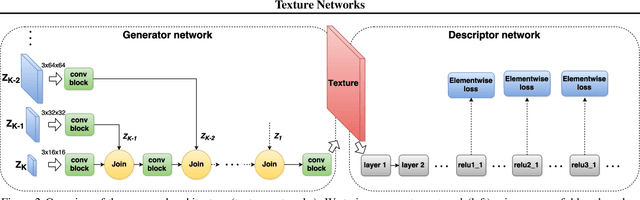


Gatys et al. recently demonstrated that deep networks can generate beautiful textures and stylized images from a single texture example. However, their methods requires a slow and memory-consuming optimization process. We propose here an alternative approach that moves the computational burden to a learning stage. Given a single example of a texture, our approach trains compact feed-forward convolutional networks to generate multiple samples of the same texture of arbitrary size and to transfer artistic style from a given image to any other image. The resulting networks are remarkably light-weight and can generate textures of quality comparable to Gatys~et~al., but hundreds of times faster. More generally, our approach highlights the power and flexibility of generative feed-forward models trained with complex and expressive loss functions.