 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic regression for defect interactions in 2D materials
Dec 23, 2025Machine learning models have become firmly established across all scientific fields. Extracting features from data and making inferences based on them with neural network models often yields high accuracy; however, this approach has several drawbacks. Symbolic regression is a powerful technique for discovering analytical equations that describe data, providing interpretable and generalizable models capable of predicting unseen data. Symbolic regression methods have gained new momentum with the advancement of neural network technologies and offer several advantages, the main one being the interpretability of results. In this work, we examined the application of the deep symbolic regression algorithm SEGVAE to determine the properties of two-dimensional materials with defects. Comparing the results with state-of-the-art graph neural network-based methods shows comparable or, in some cases, even identical outcomes. We also discuss the applicability of this class of methods in natural sciences.
Wyckoff Transformer: Generation of Symmetric Crystals
Mar 04, 2025



Symmetry rules that atoms obey when they bond together to form an ordered crystal play a fundamental role in determining their physical, chemical, and electronic properties such as electrical and thermal conductivity, optical and polarization behavior, and mechanical strength. Almost all known crystalline materials have internal symmetry. Consistently generating stable crystal structures is still an open challenge, specifically because such symmetry rules are not accounted for. To address this issue, we propose WyFormer, a generative model for materials conditioned on space group symmetry. We use Wyckoff positions as the basis for an elegant, compressed, and discrete structure representation. To model the distribution, we develop a permutation-invariant autoregressive model based on the Transformer and an absence of positional encoding. WyFormer has a unique and powerful synergy of attributes, proven by extensive experimentation: best-in-class symmetry-conditioned generation, physics-motivated inductive bias, competitive stability of the generated structures, competitive material property prediction quality, and unparalleled inference speed.
Predicting ionic conductivity in solids from the machine-learned potential energy landscape
Nov 11, 2024



Discovering new superionic materials is essential for advancing solid-state batteries, which offer improved energy density and safety compared to the traditional lithium-ion batteries with liquid electrolytes. Conventional computational methods for identifying such materials are resource-intensive and not easily scalable. Recently, universal interatomic potential models have been developed using equivariant graph neural networks. These models are trained on extensive datasets of first-principles force and energy calculations. One can achieve significant computational advantages by leveraging them as the foundation for traditional methods of assessing the ionic conductivity, such as molecular dynamics or nudged elastic band techniques. However, the generalization error from model inference on diverse atomic structures arising in such calculations can compromise the reliability of the results. In this work, we propose an approach for the quick and reliable evaluation of ionic conductivity through the analysis of a universal interatomic potential. Our method incorporates a set of heuristic structure descriptors that effectively employ the rich knowledge of the underlying model while requiring minimal generalization capabilities. Using our descriptors, we rank lithium-containing materials in the Materials Project database according to their expected ionic conductivity. Eight out of the ten highest-ranked materials are confirmed to be superionic at room temperature in first-principles calculations. Notably, our method achieves a speed-up factor of approximately 50 compared to molecular dynamics driven by a machine-learning potential, and is at least 3,000 times faster compared to first-principles molecular dynamics.
AI Competitions and Benchmarks: Competition platforms
Dec 08, 2023
The ecosystem of artificial intelligence competitions is a diverse and multifaceted landscape, encompassing a variety of platforms that each host numerous competitions annually, alongside a plethora of specialized websites dedicated to singular contests. These platforms adeptly manage the overarching administrative responsibilities inherent in orchestrating competitions, thus affording organizers the liberty to allocate greater attention to other facets of their contests. Notably, these platforms exhibit considerable diversity in their operational functionalities, economic models, and community dynamics. This chapter conducts an extensive review of the foremost services in this realm and elucidates several alternative methodologies that facilitate the independent hosting of such challenges. Keywords: competition platform, challenge hosting services, comparison.
Symbolic expression generation via Variational Auto-Encoder
Jan 15, 2023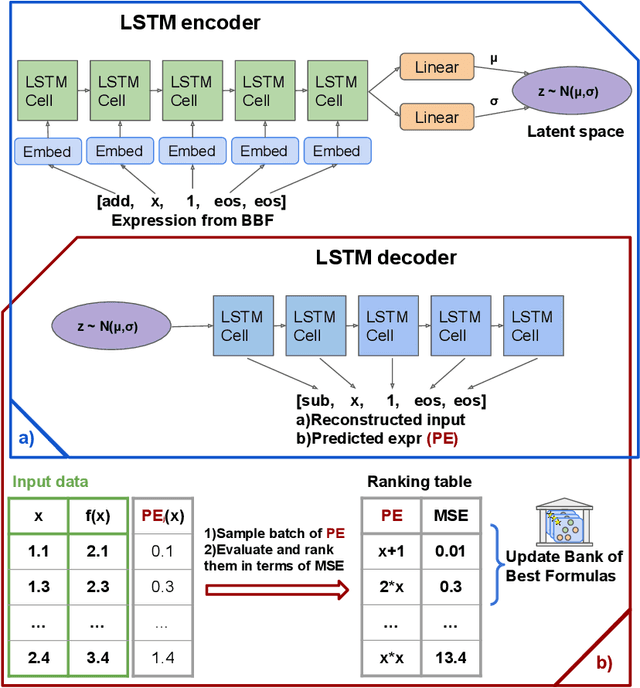

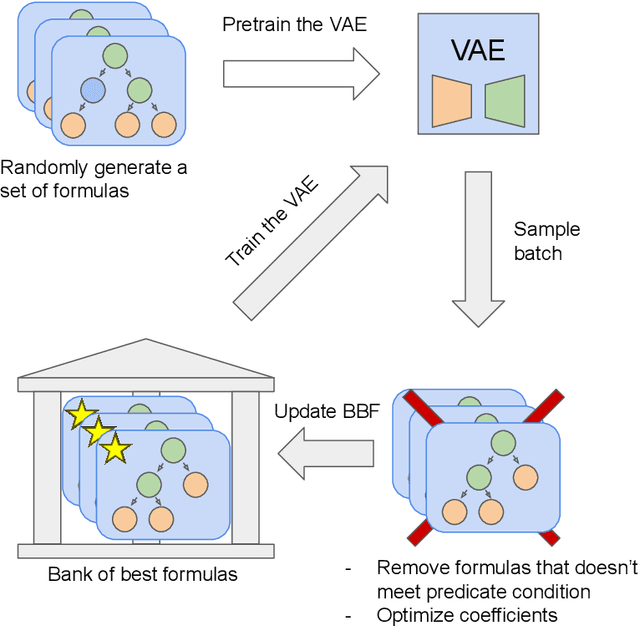

There are many problems in physics, biology, and other natural sciences in which symbolic regression can provide valuable insights and discover new laws of nature. A widespread Deep Neural Networks do not provide interpretable solutions. Meanwhile, symbolic expressions give us a clear relation between observations and the target variable. However, at the moment, there is no dominant solution for the symbolic regression task, and we aim to reduce this gap with our algorithm. In this work, we propose a novel deep learning framework for symbolic expression generation via variational autoencoder (VAE). In a nutshell, we suggest using a VAE to generate mathematical expressions, and our training strategy forces generated formulas to fit a given dataset. Our framework allows encoding apriori knowledge of the formulas into fast-check predicates that speed up the optimization process. We compare our method to modern symbolic regression benchmarks and show that our method outperforms the competitors under noisy conditions. The recovery rate of SEGVAE is 65% on the Ngyuen dataset with a noise level of 10%, which is better than the previously reported SOTA by 20%. We demonstrate that this value depends on the dataset and can be even higher.
The Tracking Machine Learning challenge : Throughput phase
May 14, 2021
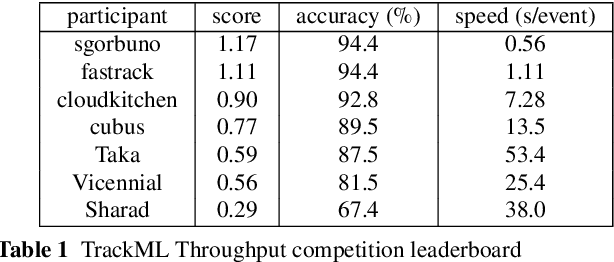
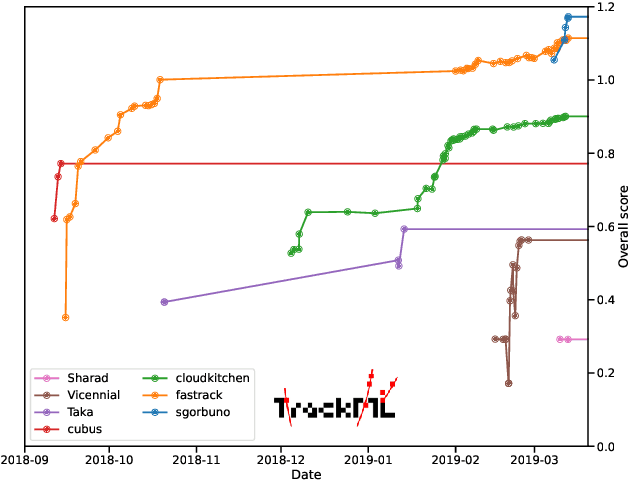
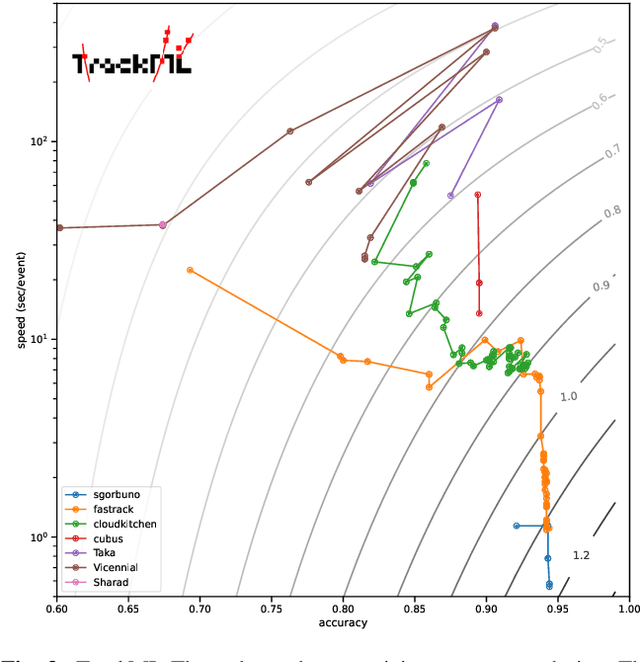
This paper reports on the second "Throughput" phase of the Tracking Machine Learning (TrackML) challenge on the Codalab platform. As in the first "Accuracy" phase, the participants had to solve a difficult experimental problem linked to tracking accurately the trajectory of particles as e.g. created at the Large Hadron Collider (LHC): given O($10^5$) points, the participants had to connect them into O($10^4$) individual groups that represent the particle trajectories which are approximated helical. While in the first phase only the accuracy mattered, the goal of this second phase was a compromise between the accuracy and the speed of inference. Both were measured on the Codalab platform where the participants had to upload their software. The best three participants had solutions with good accuracy and speed an order of magnitude faster than the state of the art when the challenge was designed. Although the core algorithms were less diverse than in the first phase, a diversity of techniques have been used and are described in this paper. The performance of the algorithms are analysed in depth and lessons derived.
Segmentation of EM showers for neutrino experiments with deep graph neural networks
Apr 16, 2021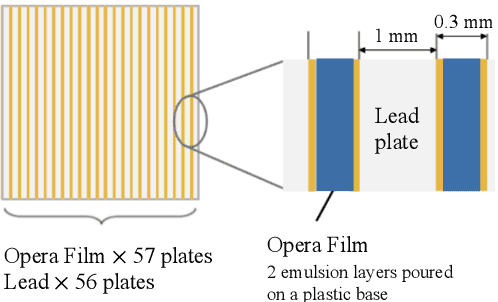
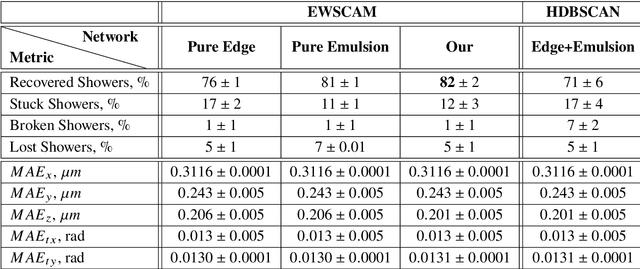
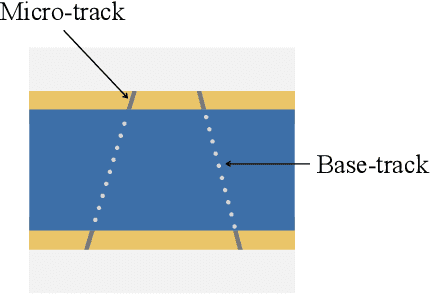
We introduce a novel method for showers reconstruction from the data collected with electromagnetic (EM) sampling calorimeters. Such detectors are widely used in High Energy Physics to measure the energy and kinematics of in-going particles. In this work, we consider the case when a large number of particles pass through an Emulsion Cloud Chamber (ECC) brick, generating electromagnetic showers. This situation can be observed with long exposure times or large input particle flux. For example, SHiP experiment is planning to use emulsion detectors for dark matter search and neutrino physics investigation. The expected full flux of SHiP experiment is about $10^{20}$ particles over five years. Because of the high amount of in-going particles, we will observe a lot of overlapping showers. It makes EM showers reconstruction a challenging segmentation problem. Our reconstruction pipeline consists of a Graph Neural Network that predicts an adjacency matrix for the clustering algorithm. To improve Graph Neural Network's performance, we propose a new layer type (EmulsionConv) that takes into account geometrical properties of shower development in ECC brick. For the clustering of overlapping showers, we use a modified hierarchical density-based clustering algorithm. Our method does not use any prior information about the incoming particles and identifies up to 82% of electromagnetic showers in emulsion detectors. The mean energy resolution over $17,715$ showers is 27%. The main test bench for the algorithm for reconstructing electromagnetic showers is going to be SND@LHC.
Online detection of failures generated by storage simulator
Jan 18, 2021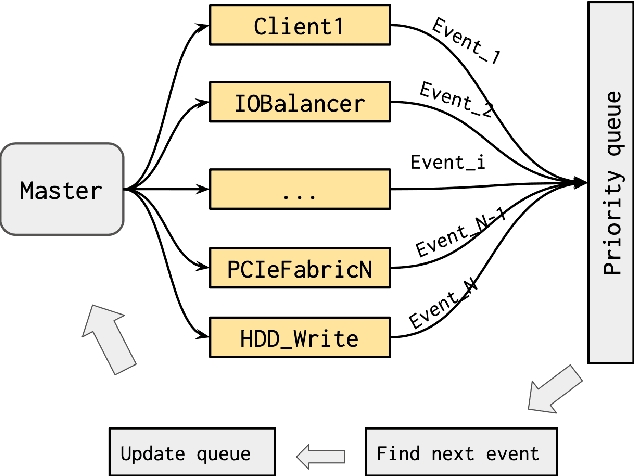

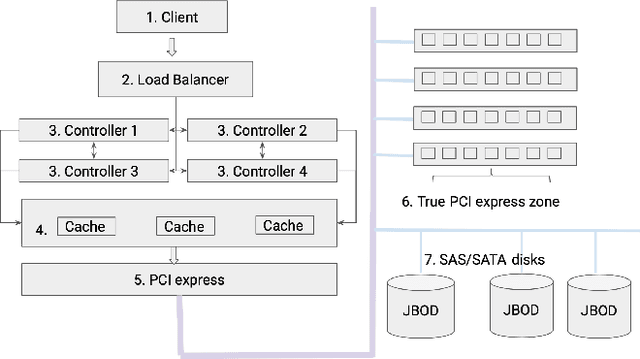
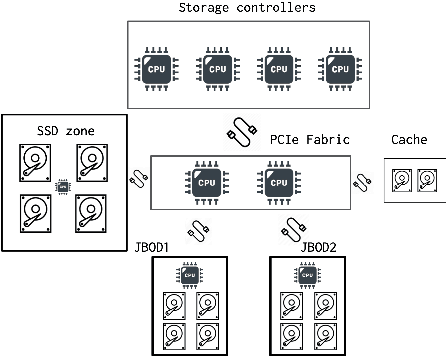
Modern large-scale data-farms consist of hundreds of thousands of storage devices that span distributed infrastructure. Devices used in modern data centers (such as controllers, links, SSD- and HDD-disks) can fail due to hardware as well as software problems. Such failures or anomalies can be detected by monitoring the activity of components using machine learning techniques. In order to use these techniques, researchers need plenty of historical data of devices in normal and failure mode for training algorithms. In this work, we challenge two problems: 1) lack of storage data in the methods above by creating a simulator and 2) applying existing online algorithms that can faster detect a failure occurred in one of the components. We created a Go-based (golang) package for simulating the behavior of modern storage infrastructure. The software is based on the discrete-event modeling paradigm and captures the structure and dynamics of high-level storage system building blocks. The package's flexible structure allows us to create a model of a real-world storage system with a configurable number of components. The primary area of interest is exploring the storage machine's behavior under stress testing or exploitation in the medium- or long-term for observing failures of its components. To discover failures in the time series distribution generated by the simulator, we modified a change point detection algorithm that works in online mode. The goal of the change-point detection is to discover differences in time series distribution. This work describes an approach for failure detection in time series data based on direct density ratio estimation via binary classifiers.
A study of Neural networks point source extraction on simulated Fermi/LAT Telescope images
Jul 08, 2020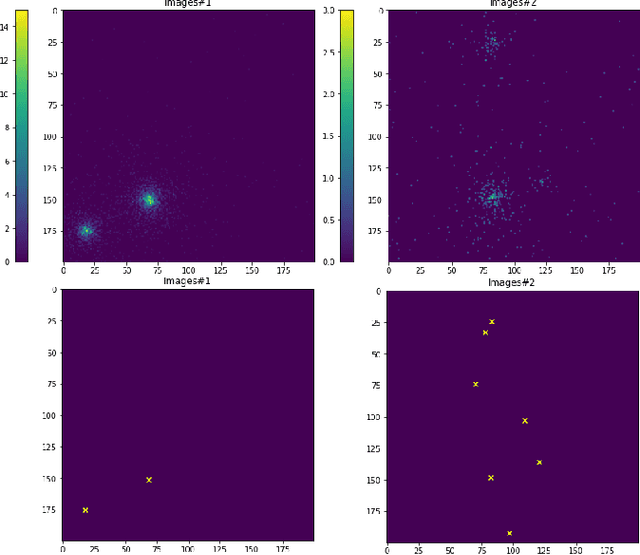
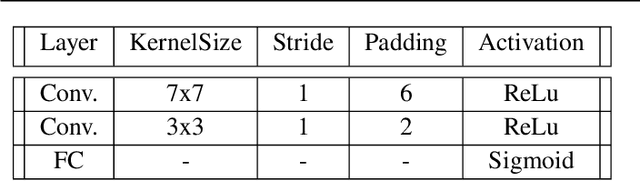
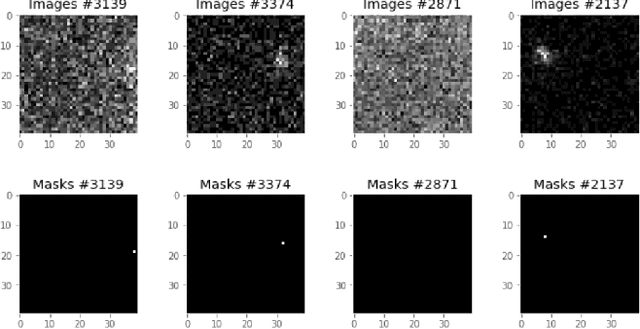
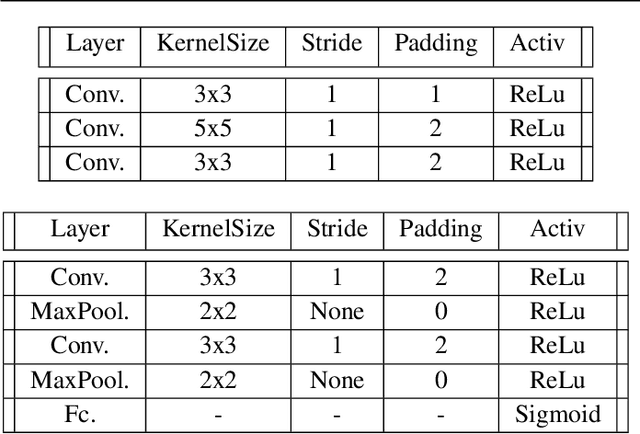
Astrophysical images in the GeV band are challenging to analyze due to the strong contribution of the background and foreground astrophysical diffuse emission and relatively broad point spread function of modern space-based instruments. In certain cases, even finding of point sources on the image becomes a non-trivial task. We present a method for point sources extraction using a convolution neural network (CNN) trained on our own artificial data set which imitates images from the Fermi Large Area Telescope. These images are raw count photon maps of 10x10 degrees covering energies from 1 to 10 GeV. We compare different CNN architectures that demonstrate accuracy increase by ~15% and reduces the inference time by at least the factor of 4 accuracy improvement with respect to a similar state of the art models.
Differentiating the Black-Box: Optimization with Local Generative Surrogates
Feb 11, 2020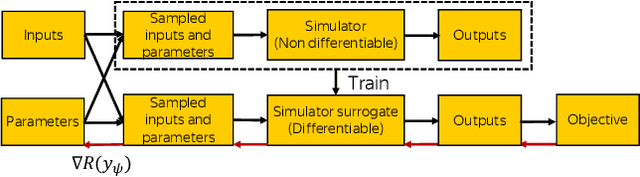
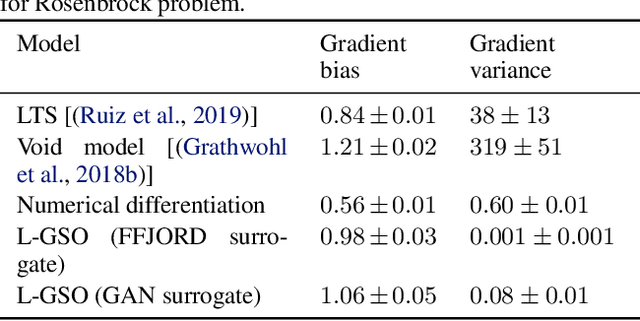
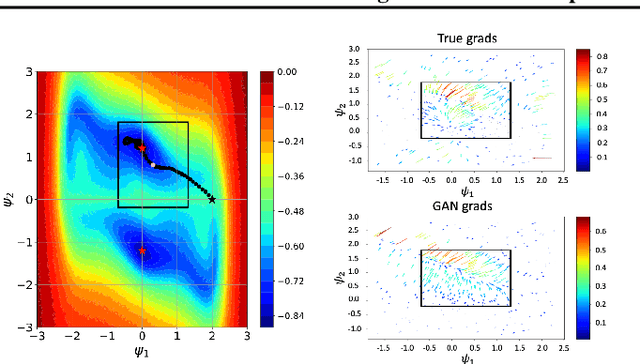

We propose a novel method for gradient-based optimization of black-box simulators using differentiable local surrogate models. In fields such as physics and engineering, many processes are modeled with non-differentiable simulators with intractable likelihoods. Optimization of these forward models is particularly challenging, especially when the simulator is stochastic. To address such cases, we introduce the use of deep generative models to iteratively approximate the simulator in local neighborhoods of the parameter space. We demonstrate that these local surrogates can be used to approximate the gradient of the simulator, and thus enable gradient-based optimization of simulator parameters. In cases where the dependence of the simulator on the parameter space is constrained to a low dimensional submanifold, we observe that our method attains minima faster than all baseline methods, including Bayesian optimization, numerical optimization, and REINFORCE driven approaches.