 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePQuantML: A Tool for End-to-End Hardware-aware Model Compression
Mar 27, 2026PQuantML is a new open-source, hardware-aware neural network model compression library tailored to end-to-end workflows. Motivated by the need to deploy performant models to environments with strict latency constraints, PQuantML simplifies training of compressed models by providing a unified interface to apply pruning and quantization, either jointly or individually. The library implements multiple pruning methods with different granularities, as well as fixed-point quantization with support for High-Granularity Quantization. We evaluate PQuantML on representative tasks such as the jet substructure classification, so-called jet tagging, an on-edge problem related to real-time LHC data processing. Using various pruning methods with fixed-point quantization, PQuantML achieves substantial parameter and bit-width reductions while maintaining accuracy. The resulting compression is further compared against existing tools, such as QKeras and HGQ.
Neural Scaling Laws for Boosted Jet Tagging
Feb 17, 2026The success of Large Language Models (LLMs) has established that scaling compute, through joint increases in model capacity and dataset size, is the primary driver of performance in modern machine learning. While machine learning has long been an integral component of High Energy Physics (HEP) data analysis workflows, the compute used to train state-of-the-art HEP models remains orders of magnitude below that of industry foundation models. With scaling laws only beginning to be studied in the field, we investigate neural scaling laws for boosted jet classification using the public JetClass dataset. We derive compute optimal scaling laws and identify an effective performance limit that can be consistently approached through increased compute. We study how data repetition, common in HEP where simulation is expensive, modifies the scaling yielding a quantifiable effective dataset size gain. We then study how the scaling coefficients and asymptotic performance limits vary with the choice of input features and particle multiplicity, demonstrating that increased compute reliably drives performance toward an asymptotic limit, and that more expressive, lower-level features can raise the performance limit and improve results at fixed dataset size.
Supercharging Simulation-Based Inference for Bayesian Optimal Experimental Design
Feb 06, 2026Bayesian optimal experimental design (BOED) seeks to maximize the expected information gain (EIG) of experiments. This requires a likelihood estimate, which in many settings is intractable. Simulation-based inference (SBI) provides powerful tools for this regime. However, existing work explicitly connecting SBI and BOED is restricted to a single contrastive EIG bound. We show that the EIG admits multiple formulations which can directly leverage modern SBI density estimators, encompassing neural posterior, likelihood, and ratio estimation. Building on this perspective, we define a novel EIG estimator using neural likelihood estimation. Further, we identify optimization as a key bottleneck of gradient based EIG maximization and show that a simple multi-start parallel gradient ascent procedure can substantially improve reliability and performance. With these innovations, our SBI-based BOED methods are able to match or outperform by up to $22\%$ existing state-of-the-art approaches across standard BOED benchmarks.
AIE4ML: An End-to-End Framework for Compiling Neural Networks for the Next Generation of AMD AI Engines
Dec 17, 2025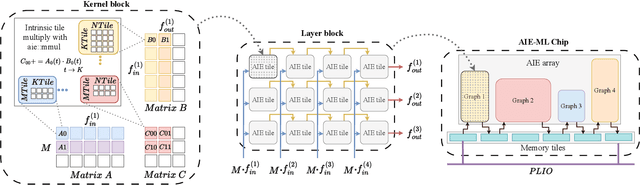
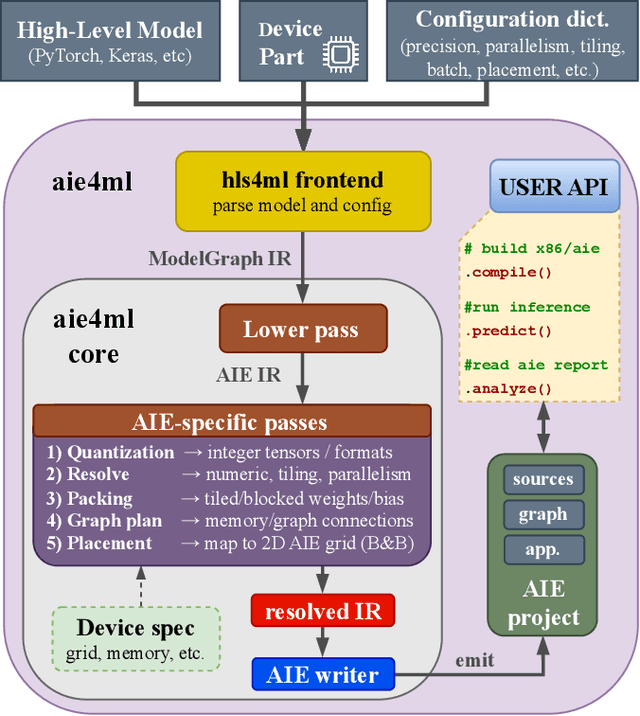
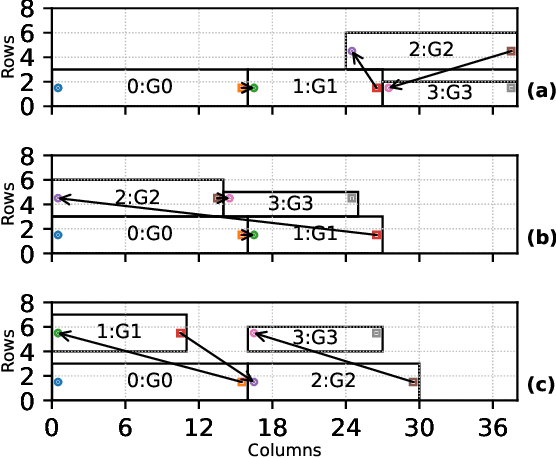
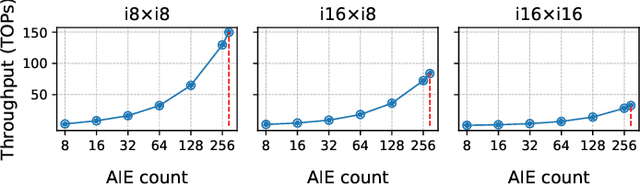
Efficient AI inference on AMD's Versal AI Engine (AIE) is challenging due to tightly coupled VLIW execution, explicit datapaths, and local memory management. Prior work focused on first-generation AIE kernel optimizations, without tackling full neural network execution across the 2D array. In this work, we present AIE4ML, the first comprehensive framework for converting AI models automatically into optimized firmware targeting the AIE-ML generation devices, also with forward compatibility for the newer AIE-MLv2 architecture. At the single-kernel level, we attain performance close to the architectural peak. At the graph and system levels, we provide a structured parallelization method that can scale across the 2D AIE-ML fabric and exploit its dedicated memory tiles to stay entirely on-chip throughout the model execution. As a demonstration, we designed a generalized and highly efficient linear-layer implementation with intrinsic support for fused bias addition and ReLU activation. Also, as our framework necessitates the generation of multi-layer implementations, our approach systematically derives deterministic, compact, and topology-optimized placements tailored to the physical 2D grid of the device through a novel graph placement and search algorithm. Finally, the framework seamlessly accepts quantized models imported from high-level tools such as hls4ml or PyTorch while preserving bit-exactness. In layer scaling benchmarks, we achieve up to 98.6% efficiency relative to the single-kernel baseline, utilizing 296 of 304 AIE tiles (97.4%) of the device with entirely on-chip data movement. With evaluations across real-world model topologies, we demonstrate that AIE4ML delivers GPU-class throughput under microsecond latency constraints, making it a practical companion for ultra-low-latency environments such as trigger systems in particle physics experiments.
Re-Simulation-based Self-Supervised Learning for Pre-Training Foundation Models
Mar 11, 2024



Self-Supervised Learning (SSL) is at the core of training modern large machine learning models, providing a scheme for learning powerful representations that can be used in a variety of downstream tasks. However, SSL strategies must be adapted to the type of training data and downstream tasks required. We propose RS3L, a novel simulation-based SSL strategy that employs a method of re-simulation to drive data augmentation for contrastive learning. By intervening in the middle of the simulation process and re-running simulation components downstream of the intervention, we generate multiple realizations of an event, thus producing a set of augmentations covering all physics-driven variations available in the simulator. Using experiments from high-energy physics, we explore how this strategy may enable the development of a foundation model; we show how R3SL pre-training enables powerful performance in downstream tasks such as discrimination of a variety of objects and uncertainty mitigation. In addition to our results, we make the RS3L dataset publicly available for further studies on how to improve SSL strategies.
Masked Particle Modeling on Sets: Towards Self-Supervised High Energy Physics Foundation Models
Jan 25, 2024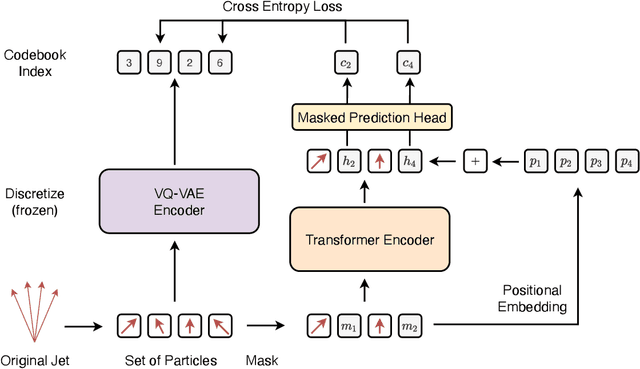
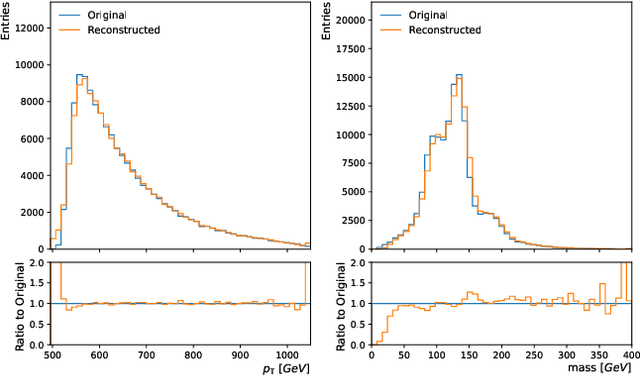
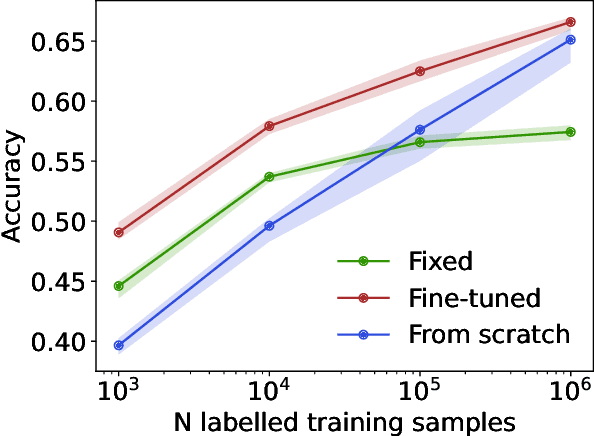
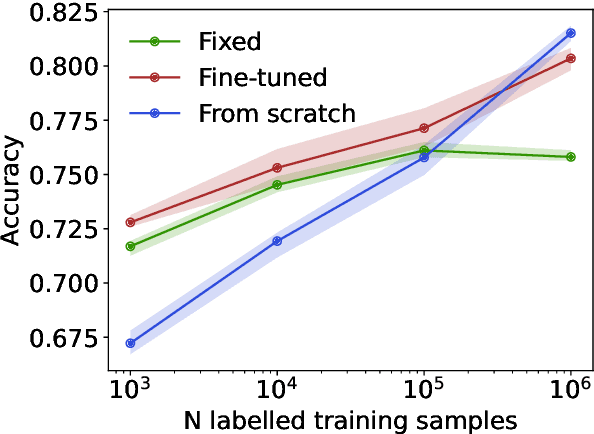
We propose masked particle modeling (MPM) as a self-supervised method for learning generic, transferable, and reusable representations on unordered sets of inputs for use in high energy physics (HEP) scientific data. This work provides a novel scheme to perform masked modeling based pre-training to learn permutation invariant functions on sets. More generally, this work provides a step towards building large foundation models for HEP that can be generically pre-trained with self-supervised learning and later fine-tuned for a variety of down-stream tasks. In MPM, particles in a set are masked and the training objective is to recover their identity, as defined by a discretized token representation of a pre-trained vector quantized variational autoencoder. We study the efficacy of the method in samples of high energy jets at collider physics experiments, including studies on the impact of discretization, permutation invariance, and ordering. We also study the fine-tuning capability of the model, showing that it can be adapted to tasks such as supervised and weakly supervised jet classification, and that the model can transfer efficiently with small fine-tuning data sets to new classes and new data domains.
Differentiable Vertex Fitting for Jet Flavour Tagging
Oct 19, 2023We propose a differentiable vertex fitting algorithm that can be used for secondary vertex fitting, and that can be seamlessly integrated into neural networks for jet flavour tagging. Vertex fitting is formulated as an optimization problem where gradients of the optimized solution vertex are defined through implicit differentiation and can be passed to upstream or downstream neural network components for network training. More broadly, this is an application of differentiable programming to integrate physics knowledge into neural network models in high energy physics. We demonstrate how differentiable secondary vertex fitting can be integrated into larger transformer-based models for flavour tagging and improve heavy flavour jet classification.
Branches of a Tree: Taking Derivatives of Programs with Discrete and Branching Randomness in High Energy Physics
Aug 31, 2023



We propose to apply several gradient estimation techniques to enable the differentiation of programs with discrete randomness in High Energy Physics. Such programs are common in High Energy Physics due to the presence of branching processes and clustering-based analysis. Thus differentiating such programs can open the way for gradient based optimization in the context of detector design optimization, simulator tuning, or data analysis and reconstruction optimization. We discuss several possible gradient estimation strategies, including the recent Stochastic AD method, and compare them in simplified detector design experiments. In doing so we develop, to the best of our knowledge, the first fully differentiable branching program.
Interpretable Uncertainty Quantification in AI for HEP
Aug 08, 2022Estimating uncertainty is at the core of performing scientific measurements in HEP: a measurement is not useful without an estimate of its uncertainty. The goal of uncertainty quantification (UQ) is inextricably linked to the question, "how do we physically and statistically interpret these uncertainties?" The answer to this question depends not only on the computational task we aim to undertake, but also on the methods we use for that task. For artificial intelligence (AI) applications in HEP, there are several areas where interpretable methods for UQ are essential, including inference, simulation, and control/decision-making. There exist some methods for each of these areas, but they have not yet been demonstrated to be as trustworthy as more traditional approaches currently employed in physics (e.g., non-AI frequentist and Bayesian methods). Shedding light on the questions above requires additional understanding of the interplay of AI systems and uncertainty quantification. We briefly discuss the existing methods in each area and relate them to tasks across HEP. We then discuss recommendations for avenues to pursue to develop the necessary techniques for reliable widespread usage of AI with UQ over the next decade.
Ultra-low latency recurrent neural network inference on FPGAs for physics applications with hls4ml
Jul 01, 2022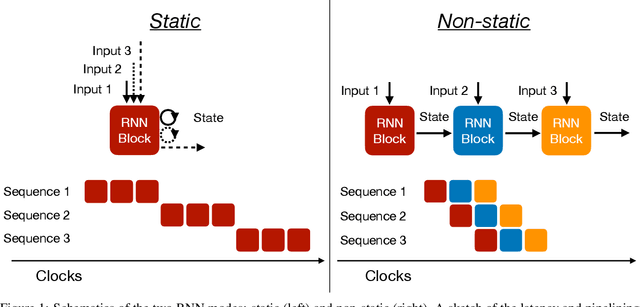
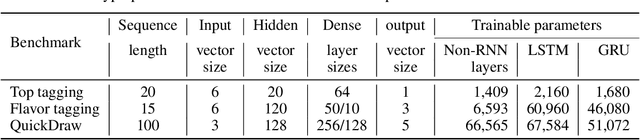
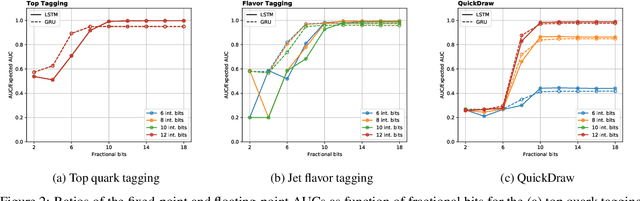

Recurrent neural networks have been shown to be effective architectures for many tasks in high energy physics, and thus have been widely adopted. Their use in low-latency environments has, however, been limited as a result of the difficulties of implementing recurrent architectures on field-programmable gate arrays (FPGAs). In this paper we present an implementation of two types of recurrent neural network layers -- long short-term memory and gated recurrent unit -- within the hls4ml framework. We demonstrate that our implementation is capable of producing effective designs for both small and large models, and can be customized to meet specific design requirements for inference latencies and FPGA resources. We show the performance and synthesized designs for multiple neural networks, many of which are trained specifically for jet identification tasks at the CERN Large Hadron Collider.