 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning on Heterogeneous, Edge, and Quantum Hardware for Particle Physics (ML-HEQUPP)
Feb 24, 2026The next generation of particle physics experiments will face a new era of challenges in data acquisition, due to unprecedented data rates and volumes along with extreme environments and operational constraints. Harnessing this data for scientific discovery demands real-time inference and decision-making, intelligent data reduction, and efficient processing architectures beyond current capabilities. Crucial to the success of this experimental paradigm are several emerging technologies, such as artificial intelligence and machine learning (AI/ML) and silicon microelectronics, and the advent of quantum algorithms and processing. Their intersection includes areas of research such as low-power and low-latency devices for edge computing, heterogeneous accelerator systems, reconfigurable hardware, novel codesign and synthesis strategies, readout for cryogenic or high-radiation environments, and analog computing. This white paper presents a community-driven vision to identify and prioritize research and development opportunities in hardware-based ML systems and corresponding physics applications, contributing towards a successful transition to the new data frontier of fundamental science.
jBOT: Semantic Jet Representation Clustering Emerges from Self-Distillation
Jan 21, 2026Self-supervised learning is a powerful pre-training method for learning feature representations without labels, which often capture generic underlying semantics from the data and can later be fine-tuned for downstream tasks. In this work, we introduce jBOT, a pre-training method based on self-distillation for jet data from the CERN Large Hadron Collider, which combines local particle-level distillation with global jet-level distillation to learn jet representations that support downstream tasks such as anomaly detection and classification. We observe that pre-training on unlabeled jets leads to emergent semantic class clustering in the representation space. The clustering in the frozen embedding, when pre-trained on background jets only, enables anomaly detection via simple distance-based metrics, and the learned embedding can be fine-tuned for classification with improved performance compared to supervised models trained from scratch.
Edge Machine Learning for Cluster Counting in Next-Generation Drift Chambers
Nov 16, 2025Drift chambers have long been central to collider tracking, but future machines like a Higgs factory motivate higher granularity and cluster counting for particle ID, posing new data processing challenges. Machine learning (ML) at the "edge", or in cell-level readout, can dramatically reduce the off-detector data rate for high-granularity drift chambers by performing cluster counting at-source. We present machine learning algorithms for cluster counting in real-time readout of future drift chambers. These algorithms outperform traditional derivative-based techniques based on achievable pion-kaon separation. When synthesized to FPGA resources, they can achieve latencies consistent with real-time operation in a future Higgs factory scenario, thus advancing both R&D for future collider detectors as well as hardware-based ML for edge applications in high energy physics.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
A Neural Network-Based Search for Unmodeled Transients in LIGO-Virgo-KAGRA's Third Observing Run
Dec 27, 2024



This paper presents the results of a Neural Network (NN)-based search for short-duration gravitational-wave transients in data from the third observing run of LIGO, Virgo, and KAGRA. The search targets unmodeled transients with durations of milliseconds to a few seconds in the 30-1500 Hz frequency band, without assumptions about the incoming signal direction, polarization, or morphology. Using the Gravitational Wave Anomalous Knowledge (GWAK) method, three compact binary coalescences (CBCs) identified by existing pipelines are successfully detected, along with a range of detector glitches. The algorithm constructs a low-dimensional embedded space to capture the physical features of signals, enabling the detection of CBCs, detector glitches, and unmodeled transients. This study demonstrates GWAK's ability to enhance gravitational-wave searches beyond the limits of existing pipelines, laying the groundwork for future detection strategies.
SymbolFit: Automatic Parametric Modeling with Symbolic Regression
Nov 15, 2024



We introduce SymbolFit, a framework that automates parametric modeling by using symbolic regression to perform a machine-search for functions that fit the data, while simultaneously providing uncertainty estimates in a single run. Traditionally, constructing a parametric model to accurately describe binned data has been a manual and iterative process, requiring an adequate functional form to be determined before the fit can be performed. The main challenge arises when the appropriate functional forms cannot be derived from first principles, especially when there is no underlying true closed-form function for the distribution. In this work, we address this problem by utilizing symbolic regression, a machine learning technique that explores a vast space of candidate functions without needing a predefined functional form, treating the functional form itself as a trainable parameter. Our approach is demonstrated in data analysis applications in high-energy physics experiments at the CERN Large Hadron Collider (LHC). We demonstrate its effectiveness and efficiency using five real proton-proton collision datasets from new physics searches at the LHC, namely the background modeling in resonance searches for high-mass dijet, trijet, paired-dijet, diphoton, and dimuon events. We also validate the framework using several toy datasets with one and more variables.
Ultra-low latency recurrent neural network inference on FPGAs for physics applications with hls4ml
Jul 01, 2022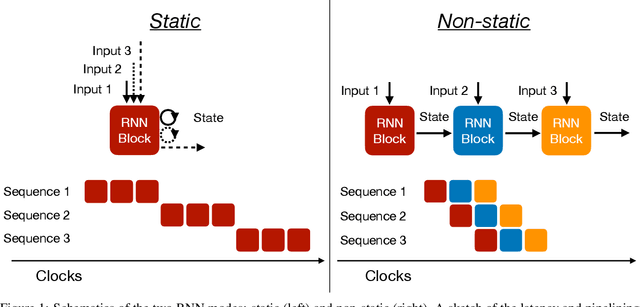
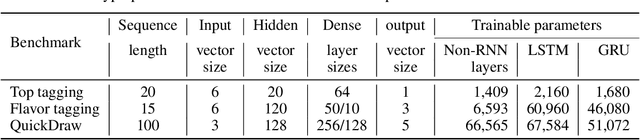
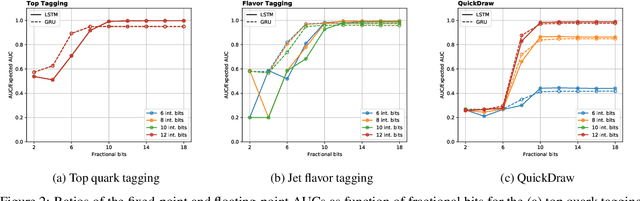

Recurrent neural networks have been shown to be effective architectures for many tasks in high energy physics, and thus have been widely adopted. Their use in low-latency environments has, however, been limited as a result of the difficulties of implementing recurrent architectures on field-programmable gate arrays (FPGAs). In this paper we present an implementation of two types of recurrent neural network layers -- long short-term memory and gated recurrent unit -- within the hls4ml framework. We demonstrate that our implementation is capable of producing effective designs for both small and large models, and can be customized to meet specific design requirements for inference latencies and FPGA resources. We show the performance and synthesized designs for multiple neural networks, many of which are trained specifically for jet identification tasks at the CERN Large Hadron Collider.
Physics Community Needs, Tools, and Resources for Machine Learning
Mar 30, 2022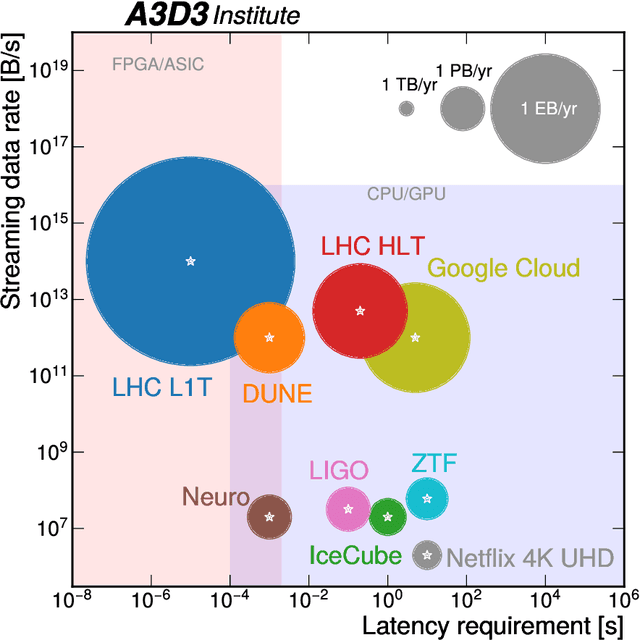

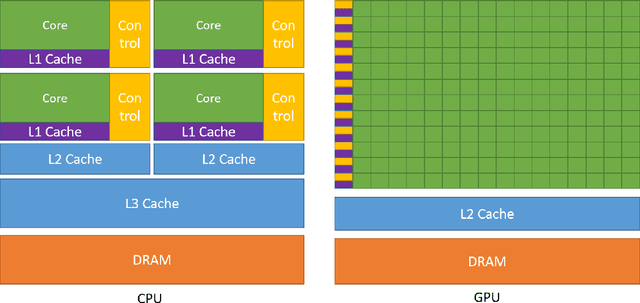
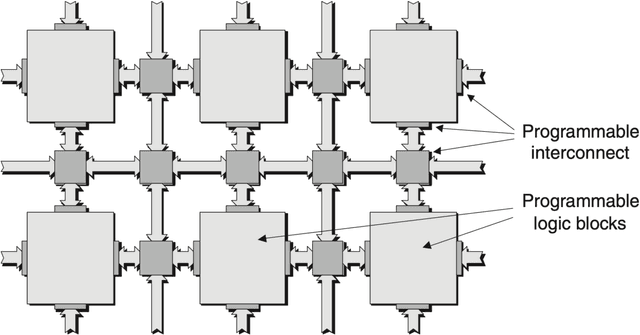
Machine learning (ML) is becoming an increasingly important component of cutting-edge physics research, but its computational requirements present significant challenges. In this white paper, we discuss the needs of the physics community regarding ML across latency and throughput regimes, the tools and resources that offer the possibility of addressing these needs, and how these can be best utilized and accessed in the coming years.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021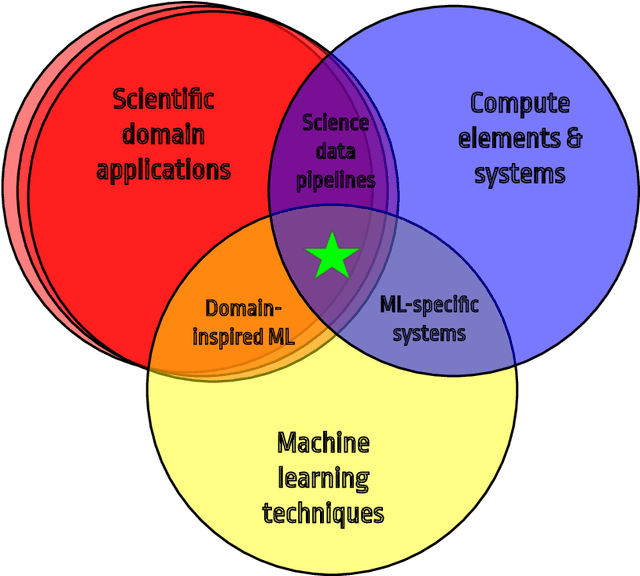
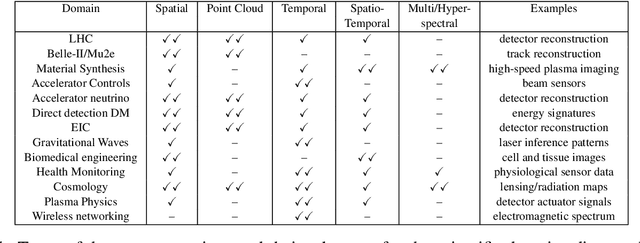
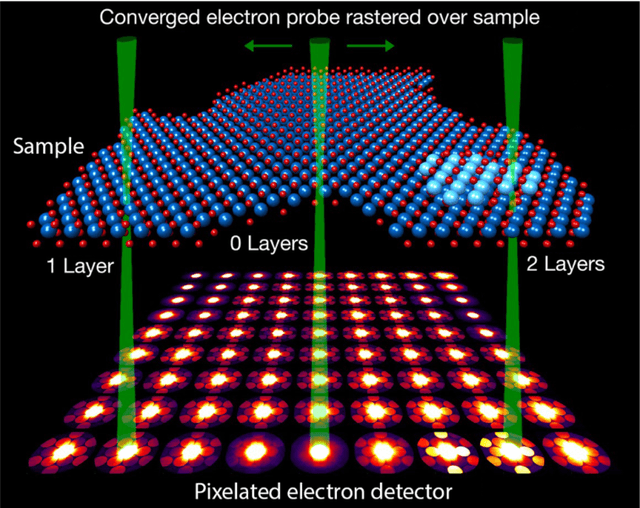
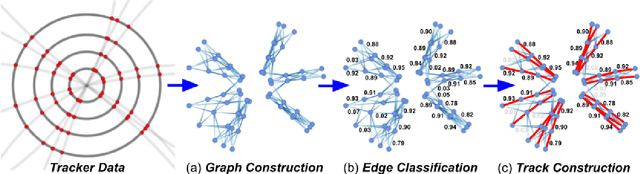
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.
hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices
Mar 23, 2021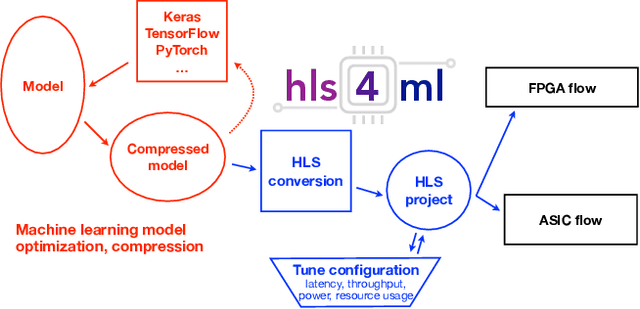
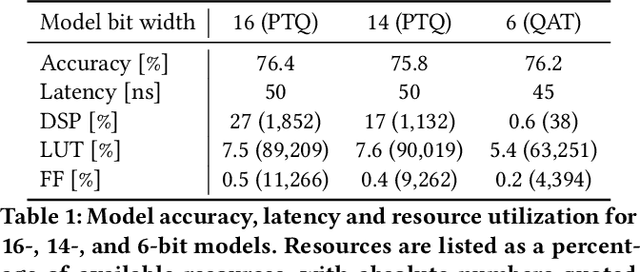
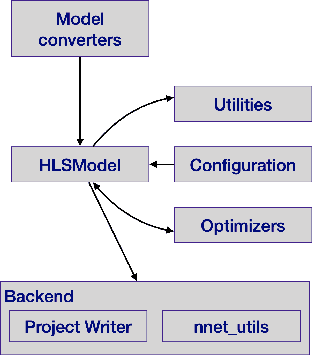
Accessible machine learning algorithms, software, and diagnostic tools for energy-efficient devices and systems are extremely valuable across a broad range of application domains. In scientific domains, real-time near-sensor processing can drastically improve experimental design and accelerate scientific discoveries. To support domain scientists, we have developed hls4ml, an open-source software-hardware codesign workflow to interpret and translate machine learning algorithms for implementation with both FPGA and ASIC technologies. We expand on previous hls4ml work by extending capabilities and techniques towards low-power implementations and increased usability: new Python APIs, quantization-aware pruning, end-to-end FPGA workflows, long pipeline kernels for low power, and new device backends include an ASIC workflow. Taken together, these and continued efforts in hls4ml will arm a new generation of domain scientists with accessible, efficient, and powerful tools for machine-learning-accelerated discovery.