 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Sense of Metadata Mess: Alignment & Risk Assessment for Diatom Data Use Case
Nov 01, 2024Biologists study Diatoms, a fundamental algae, to assess the health of aquatic systems. Diatom specimens have traditionally been preserved on analog slides, where a single slide can contain thousands of these microscopic organisms. Digitization of these collections presents both metadata challenges and opportunities. This paper reports on metadata research aimed at providing access to a digital portion of the Academy of Natural Sciences' Diatom Herbarium, Drexel University. We report results of a 3-part study covering 1) a review of relevant metadata standards and a microscopy metadata framework shared by Hammer et al., 2) a baseline metadata alignment mapping current diatom metadata properties to standard metadata types, and 3) a metadata risk analysis associated with the course of standard data curation practices. This research is part of an effort involving the transfer of these digital slides to an new system, DataFed, to support global accessible. The final section of this paper includes a conclusion and discusses next steps.
Reliable edge machine learning hardware for scientific applications
Jun 27, 2024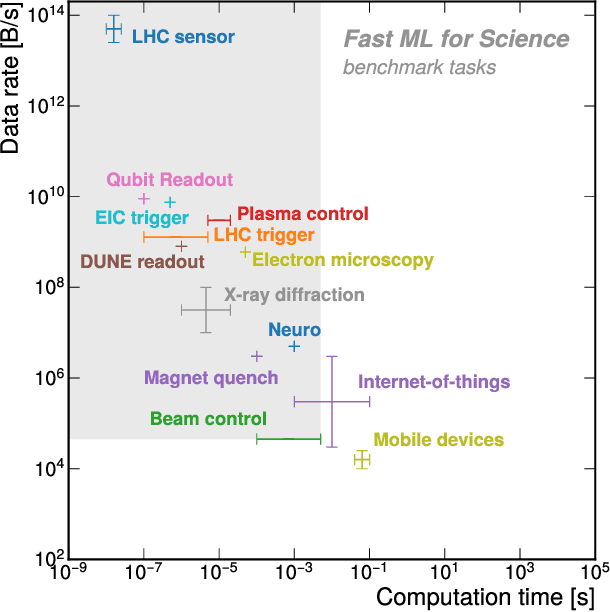
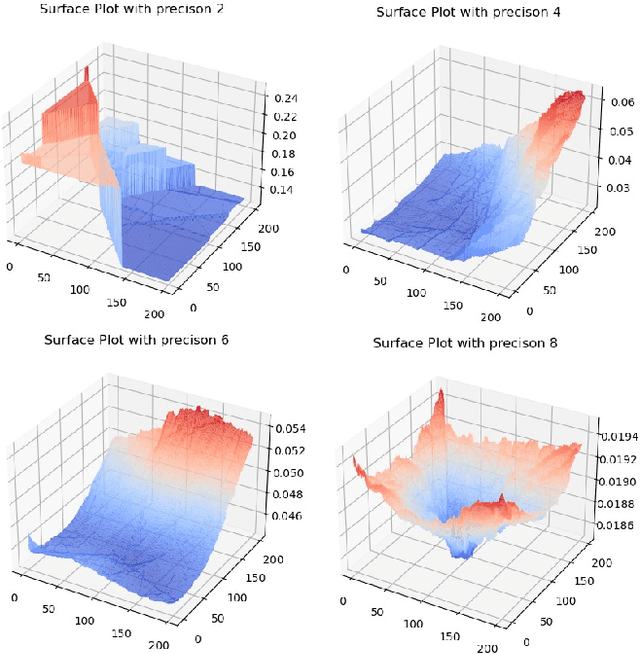
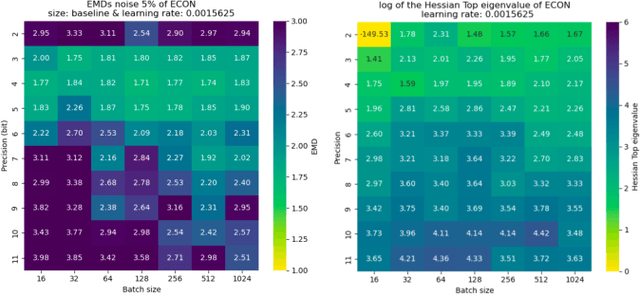
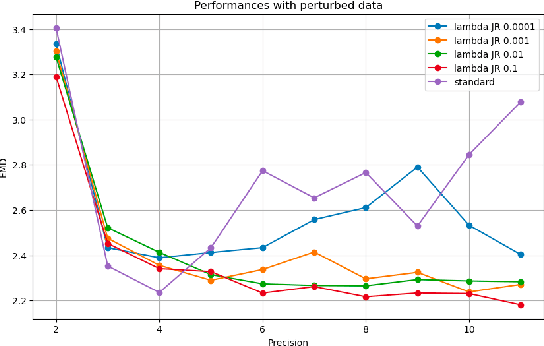
Extreme data rate scientific experiments create massive amounts of data that require efficient ML edge processing. This leads to unique validation challenges for VLSI implementations of ML algorithms: enabling bit-accurate functional simulations for performance validation in experimental software frameworks, verifying those ML models are robust under extreme quantization and pruning, and enabling ultra-fine-grained model inspection for efficient fault tolerance. We discuss approaches to developing and validating reliable algorithms at the scientific edge under such strict latency, resource, power, and area requirements in extreme experimental environments. We study metrics for developing robust algorithms, present preliminary results and mitigation strategies, and conclude with an outlook of these and future directions of research towards the longer-term goal of developing autonomous scientific experimentation methods for accelerated scientific discovery.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021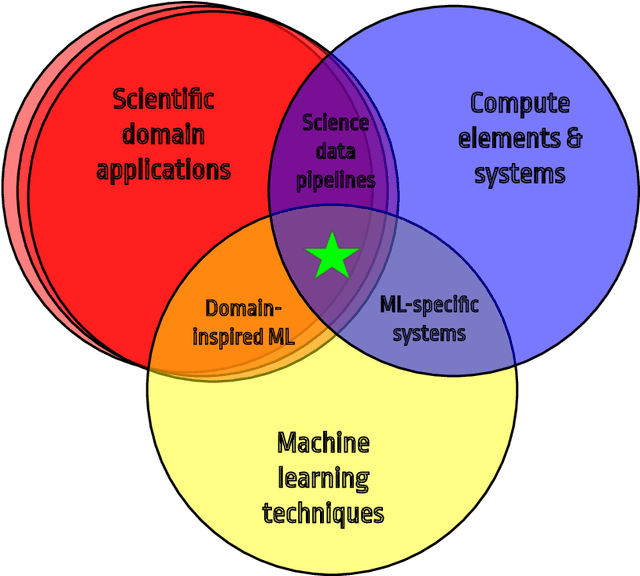
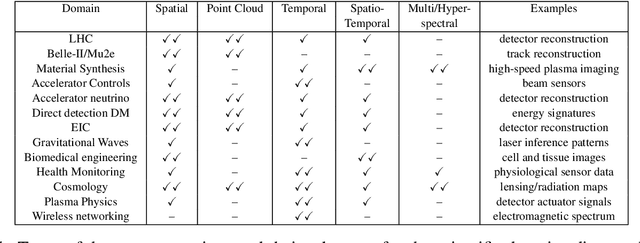
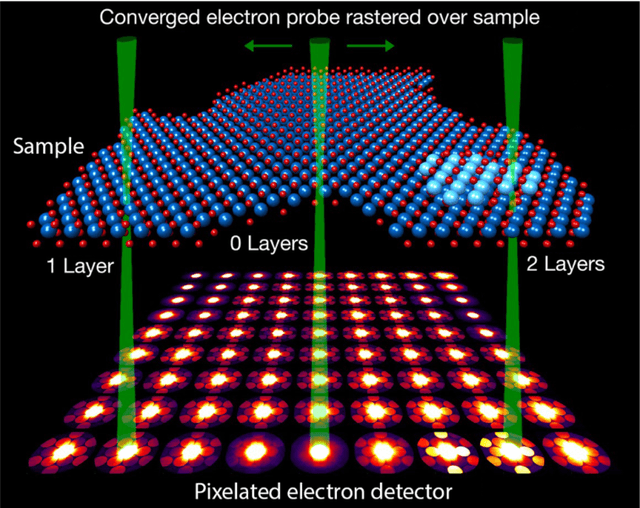
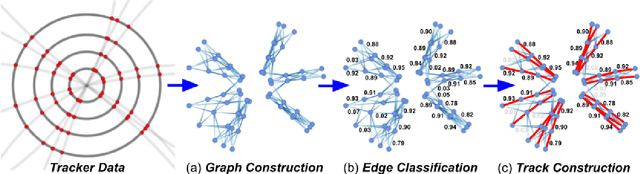
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.