 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrafast On-chip Online Learning via Spline Locality in Kolmogorov-Arnold Networks
Feb 02, 2026Ultrafast online learning is essential for high-frequency systems, such as controls for quantum computing and nuclear fusion, where adaptation must occur on sub-microsecond timescales. Meeting these requirements demands low-latency, fixed-precision computation under strict memory constraints, a regime in which conventional Multi-Layer Perceptrons (MLPs) are both inefficient and numerically unstable. We identify key properties of Kolmogorov-Arnold Networks (KANs) that align with these constraints. Specifically, we show that: (i) KAN updates exploiting B-spline locality are sparse, enabling superior on-chip resource scaling, and (ii) KANs are inherently robust to fixed-point quantization. By implementing fixed-point online training on Field-Programmable Gate Arrays (FPGAs), a representative platform for on-chip computation, we demonstrate that KAN-based online learners are significantly more efficient and expressive than MLPs across a range of low-latency and resource-constrained tasks. To our knowledge, this work is the first to demonstrate model-free online learning at sub-microsecond latencies.
KANELÉ: Kolmogorov-Arnold Networks for Efficient LUT-based Evaluation
Dec 14, 2025Low-latency, resource-efficient neural network inference on FPGAs is essential for applications demanding real-time capability and low power. Lookup table (LUT)-based neural networks are a common solution, combining strong representational power with efficient FPGA implementation. In this work, we introduce KANELÉ, a framework that exploits the unique properties of Kolmogorov-Arnold Networks (KANs) for FPGA deployment. Unlike traditional multilayer perceptrons (MLPs), KANs employ learnable one-dimensional splines with fixed domains as edge activations, a structure naturally suited to discretization and efficient LUT mapping. We present the first systematic design flow for implementing KANs on FPGAs, co-optimizing training with quantization and pruning to enable compact, high-throughput, and low-latency KAN architectures. Our results demonstrate up to a 2700x speedup and orders of magnitude resource savings compared to prior KAN-on-FPGA approaches. Moreover, KANELÉ matches or surpasses other LUT-based architectures on widely used benchmarks, particularly for tasks involving symbolic or physical formulas, while balancing resource usage across FPGA hardware. Finally, we showcase the versatility of the framework by extending it to real-time, power-efficient control systems.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
A Neural Network-Based Search for Unmodeled Transients in LIGO-Virgo-KAGRA's Third Observing Run
Dec 27, 2024



This paper presents the results of a Neural Network (NN)-based search for short-duration gravitational-wave transients in data from the third observing run of LIGO, Virgo, and KAGRA. The search targets unmodeled transients with durations of milliseconds to a few seconds in the 30-1500 Hz frequency band, without assumptions about the incoming signal direction, polarization, or morphology. Using the Gravitational Wave Anomalous Knowledge (GWAK) method, three compact binary coalescences (CBCs) identified by existing pipelines are successfully detected, along with a range of detector glitches. The algorithm constructs a low-dimensional embedded space to capture the physical features of signals, enabling the detection of CBCs, detector glitches, and unmodeled transients. This study demonstrates GWAK's ability to enhance gravitational-wave searches beyond the limits of existing pipelines, laying the groundwork for future detection strategies.
SymbolFit: Automatic Parametric Modeling with Symbolic Regression
Nov 15, 2024



We introduce SymbolFit, a framework that automates parametric modeling by using symbolic regression to perform a machine-search for functions that fit the data, while simultaneously providing uncertainty estimates in a single run. Traditionally, constructing a parametric model to accurately describe binned data has been a manual and iterative process, requiring an adequate functional form to be determined before the fit can be performed. The main challenge arises when the appropriate functional forms cannot be derived from first principles, especially when there is no underlying true closed-form function for the distribution. In this work, we address this problem by utilizing symbolic regression, a machine learning technique that explores a vast space of candidate functions without needing a predefined functional form, treating the functional form itself as a trainable parameter. Our approach is demonstrated in data analysis applications in high-energy physics experiments at the CERN Large Hadron Collider (LHC). We demonstrate its effectiveness and efficiency using five real proton-proton collision datasets from new physics searches at the LHC, namely the background modeling in resonance searches for high-mass dijet, trijet, paired-dijet, diphoton, and dimuon events. We also validate the framework using several toy datasets with one and more variables.
MACK: Mismodeling Addressed with Contrastive Knowledge
Oct 17, 2024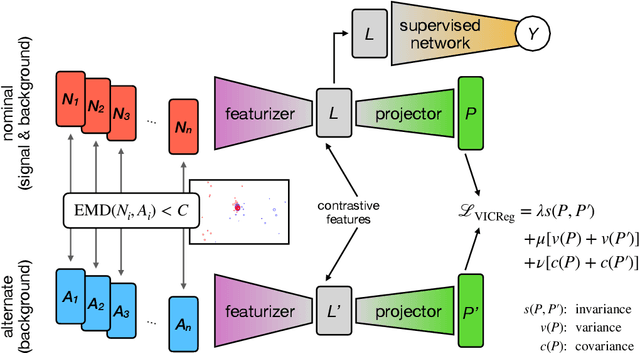
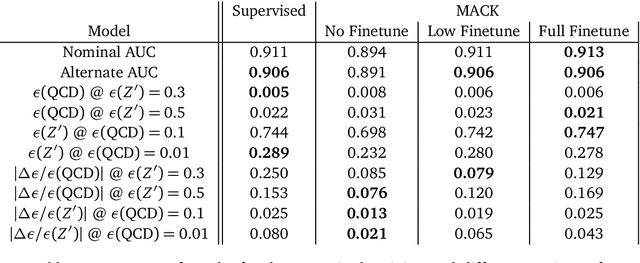
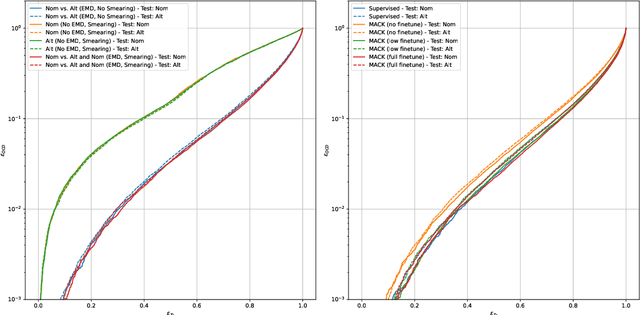

The use of machine learning methods in high energy physics typically relies on large volumes of precise simulation for training. As machine learning models become more complex they can become increasingly sensitive to differences between this simulation and the real data collected by experiments. We present a generic methodology based on contrastive learning which is able to greatly mitigate this negative effect. Crucially, the method does not require prior knowledge of the specifics of the mismodeling. While we demonstrate the efficacy of this technique using the task of jet-tagging at the Large Hadron Collider, it is applicable to a wide array of different tasks both in and out of the field of high energy physics.
Low Latency Transformer Inference on FPGAs for Physics Applications with hls4ml
Sep 08, 2024



This study presents an efficient implementation of transformer architectures in Field-Programmable Gate Arrays(FPGAs) using hls4ml. We demonstrate the strategy for implementing the multi-head attention, softmax, and normalization layer and evaluate three distinct models. Their deployment on VU13P FPGA chip achieved latency less than 2us, demonstrating the potential for real-time applications. HLS4ML compatibility with any TensorFlow-built transformer model further enhances the scalability and applicability of this work. Index Terms: FPGAs, machine learning, transformers, high energy physics, LIGO
Rapid Likelihood Free Inference of Compact Binary Coalescences using Accelerated Hardware
Jul 26, 2024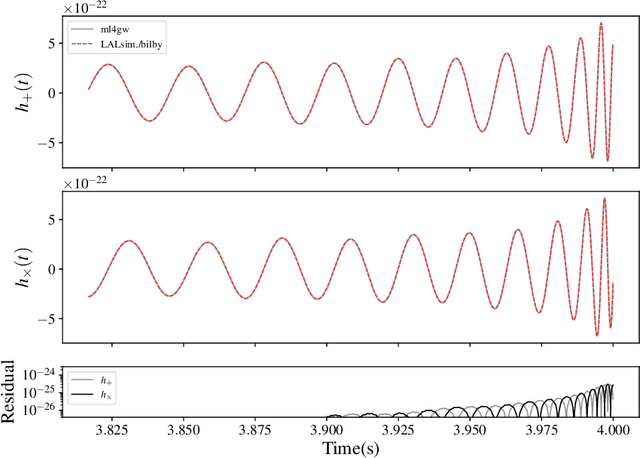
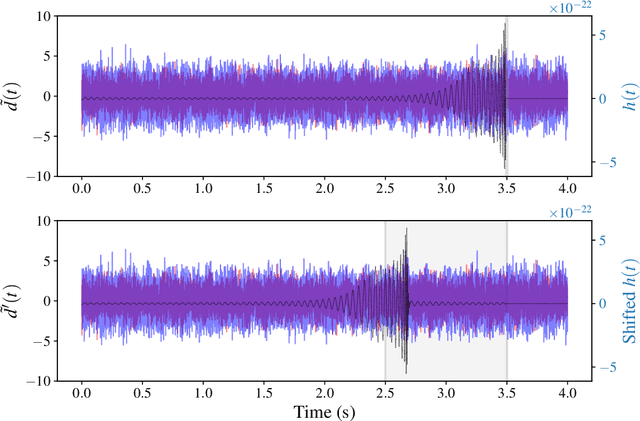
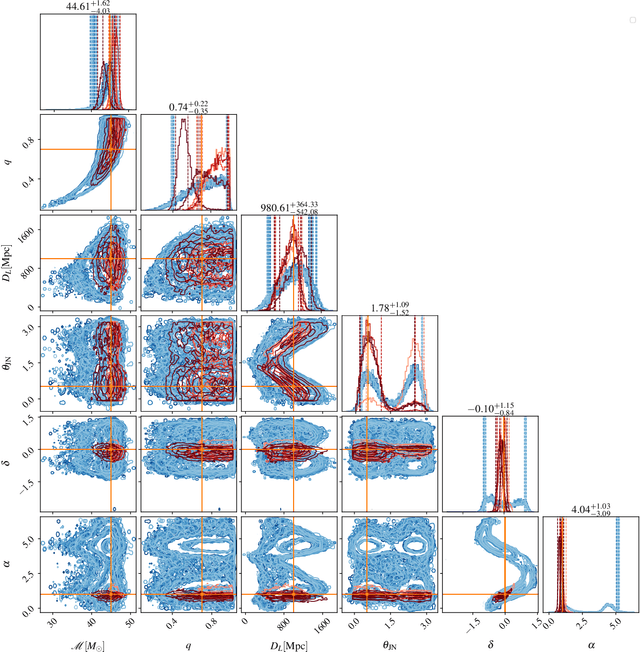
We report a gravitational-wave parameter estimation algorithm, AMPLFI, based on likelihood-free inference using normalizing flows. The focus of AMPLFI is to perform real-time parameter estimation for candidates detected by machine-learning based compact binary coalescence search, Aframe. We present details of our algorithm and optimizations done related to data-loading and pre-processing on accelerated hardware. We train our model using binary black-hole (BBH) simulations on real LIGO-Virgo detector noise. Our model has $\sim 6$ million trainable parameters with training times $\lesssim 24$ hours. Based on online deployment on a mock data stream of LIGO-Virgo data, Aframe + AMPLFI is able to pick up BBH candidates and infer parameters for real-time alerts from data acquisition with a net latency of $\sim 6$s.
Reliable edge machine learning hardware for scientific applications
Jun 27, 2024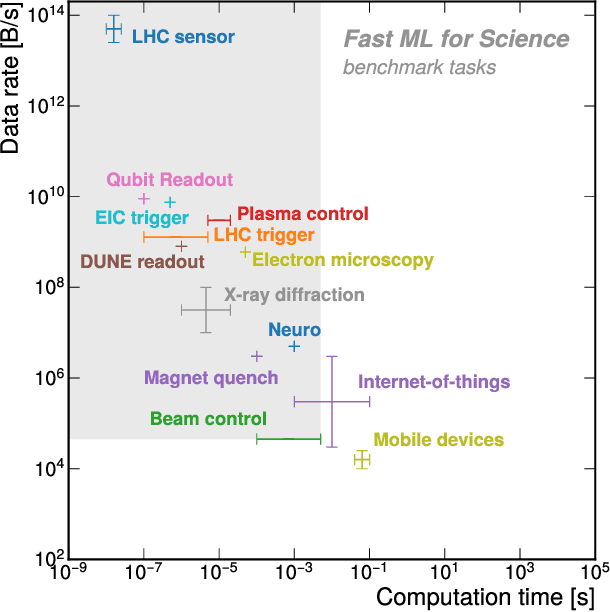
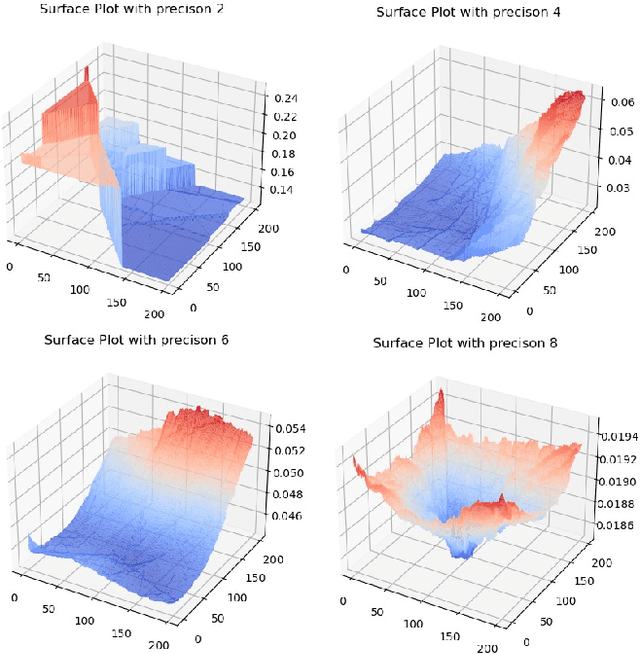
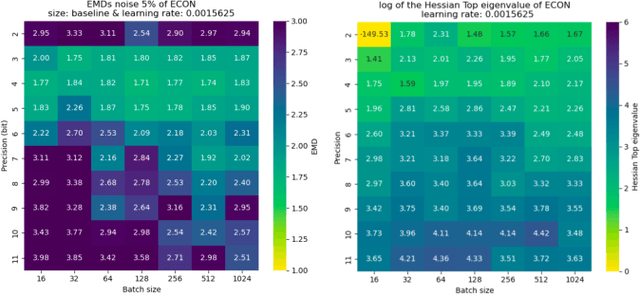
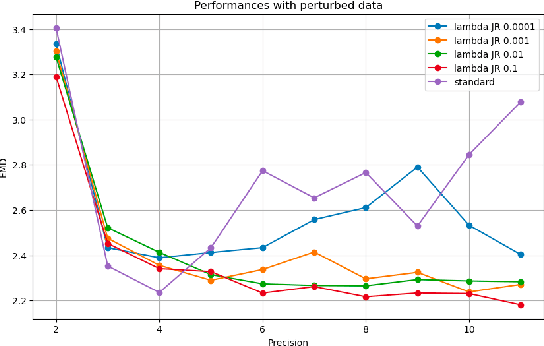
Extreme data rate scientific experiments create massive amounts of data that require efficient ML edge processing. This leads to unique validation challenges for VLSI implementations of ML algorithms: enabling bit-accurate functional simulations for performance validation in experimental software frameworks, verifying those ML models are robust under extreme quantization and pruning, and enabling ultra-fine-grained model inspection for efficient fault tolerance. We discuss approaches to developing and validating reliable algorithms at the scientific edge under such strict latency, resource, power, and area requirements in extreme experimental environments. We study metrics for developing robust algorithms, present preliminary results and mitigation strategies, and conclude with an outlook of these and future directions of research towards the longer-term goal of developing autonomous scientific experimentation methods for accelerated scientific discovery.
Re-Simulation-based Self-Supervised Learning for Pre-Training Foundation Models
Mar 11, 2024



Self-Supervised Learning (SSL) is at the core of training modern large machine learning models, providing a scheme for learning powerful representations that can be used in a variety of downstream tasks. However, SSL strategies must be adapted to the type of training data and downstream tasks required. We propose RS3L, a novel simulation-based SSL strategy that employs a method of re-simulation to drive data augmentation for contrastive learning. By intervening in the middle of the simulation process and re-running simulation components downstream of the intervention, we generate multiple realizations of an event, thus producing a set of augmentations covering all physics-driven variations available in the simulator. Using experiments from high-energy physics, we explore how this strategy may enable the development of a foundation model; we show how R3SL pre-training enables powerful performance in downstream tasks such as discrimination of a variety of objects and uncertainty mitigation. In addition to our results, we make the RS3L dataset publicly available for further studies on how to improve SSL strategies.