 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquilibrium Conserving Neural Operators for Super-Resolution Learning
Apr 18, 2025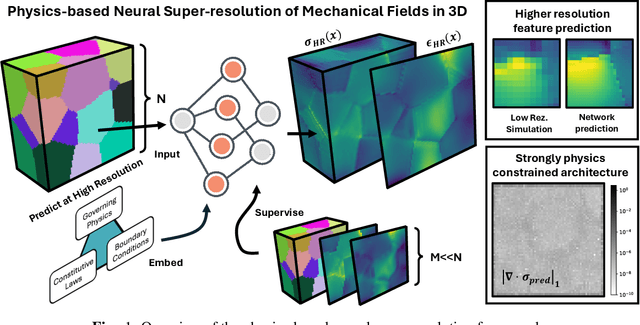
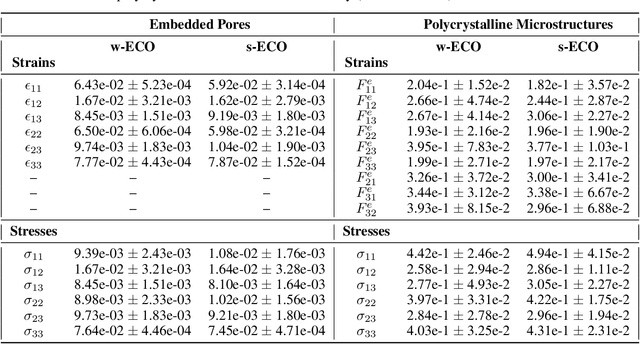
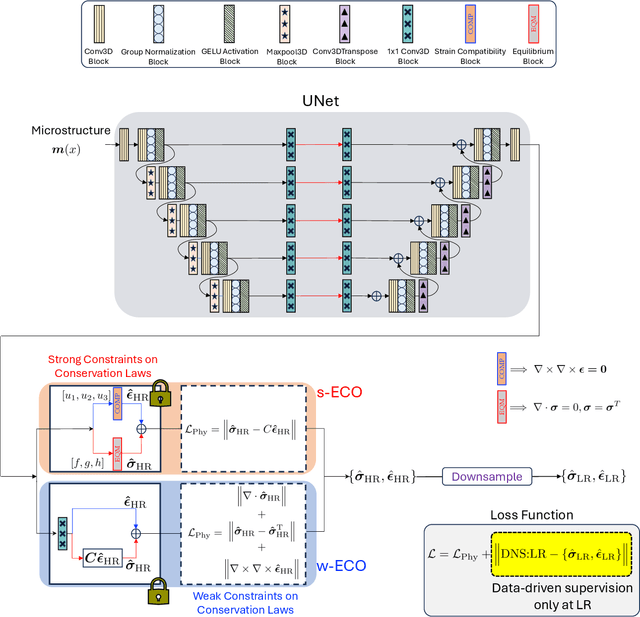
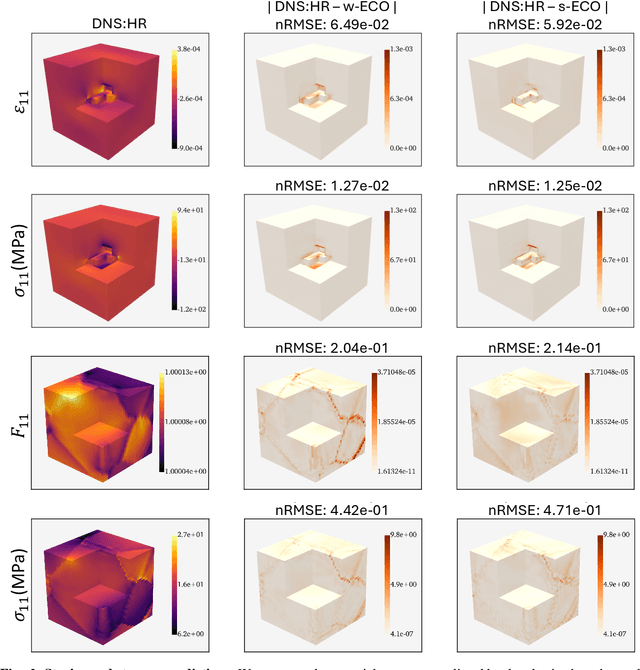
Neural surrogate solvers can estimate solutions to partial differential equations in physical problems more efficiently than standard numerical methods, but require extensive high-resolution training data. In this paper, we break this limitation; we introduce a framework for super-resolution learning in solid mechanics problems. Our approach allows one to train a high-resolution neural network using only low-resolution data. Our Equilibrium Conserving Operator (ECO) architecture embeds known physics directly into the network to make up for missing high-resolution information during training. We evaluate this ECO-based super-resolution framework that strongly enforces conservation-laws in the predicted solutions on two working examples: embedded pores in a homogenized matrix and randomly textured polycrystalline materials. ECO eliminates the reliance on high-fidelity data and reduces the upfront cost of data collection by two orders of magnitude, offering a robust pathway for resource-efficient surrogate modeling in materials modeling. ECO is readily generalizable to other physics-based problems.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
Reliable edge machine learning hardware for scientific applications
Jun 27, 2024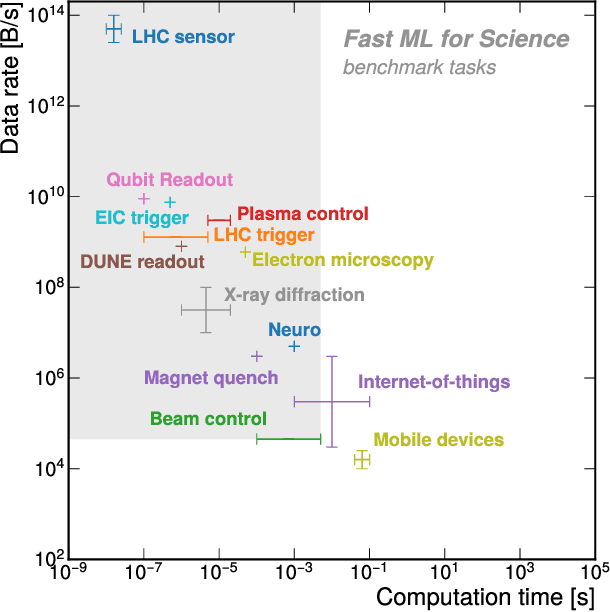
Extreme data rate scientific experiments create massive amounts of data that require efficient ML edge processing. This leads to unique validation challenges for VLSI implementations of ML algorithms: enabling bit-accurate functional simulations for performance validation in experimental software frameworks, verifying those ML models are robust under extreme quantization and pruning, and enabling ultra-fine-grained model inspection for efficient fault tolerance. We discuss approaches to developing and validating reliable algorithms at the scientific edge under such strict latency, resource, power, and area requirements in extreme experimental environments. We study metrics for developing robust algorithms, present preliminary results and mitigation strategies, and conclude with an outlook of these and future directions of research towards the longer-term goal of developing autonomous scientific experimentation methods for accelerated scientific discovery.
FAIR AI Models in High Energy Physics
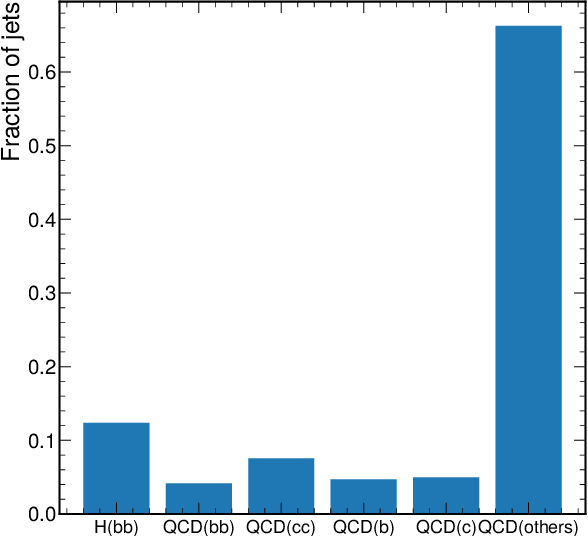
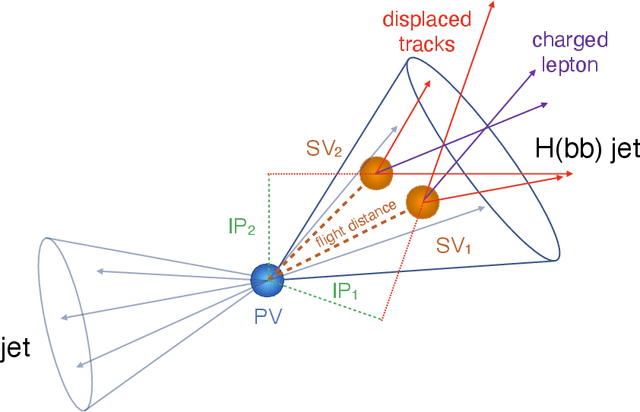
Dec 21, 2022The findable, accessible, interoperable, and reusable (FAIR) data principles have provided a framework for examining, evaluating, and improving how we share data with the aim of facilitating scientific discovery. Efforts have been made to generalize these principles to research software and other digital products. Artificial intelligence (AI) models -- algorithms that have been trained on data rather than explicitly programmed -- are an important target for this because of the ever-increasing pace with which AI is transforming scientific and engineering domains. In this paper, we propose a practical definition of FAIR principles for AI models and create a FAIR AI project template that promotes adherence to these principles. We demonstrate how to implement these principles using a concrete example from experimental high energy physics: a graph neural network for identifying Higgs bosons decaying to bottom quarks. We study the robustness of these FAIR AI models and their portability across hardware architectures and software frameworks, and report new insights on the interpretability of AI predictions by studying the interplay between FAIR datasets and AI models. Enabled by publishing FAIR AI models, these studies pave the way toward reliable and automated AI-driven scientific discovery.
Particle Graph Autoencoders and Differentiable, Learned Energy Mover's Distance
Nov 24, 2021
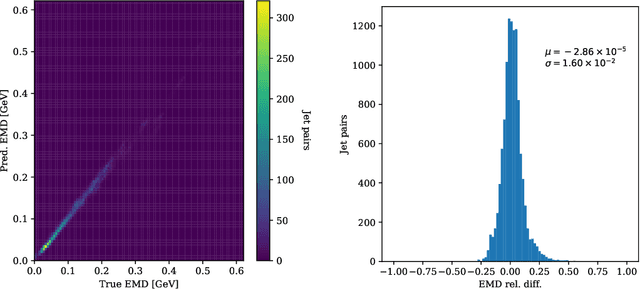
Autoencoders have useful applications in high energy physics in anomaly detection, particularly for jets - collimated showers of particles produced in collisions such as those at the CERN Large Hadron Collider. We explore the use of graph-based autoencoders, which operate on jets in their "particle cloud" representations and can leverage the interdependencies among the particles within a jet, for such tasks. Additionally, we develop a differentiable approximation to the energy mover's distance via a graph neural network, which may subsequently be used as a reconstruction loss function for autoencoders.
Explaining machine-learned particle-flow reconstruction
Nov 24, 2021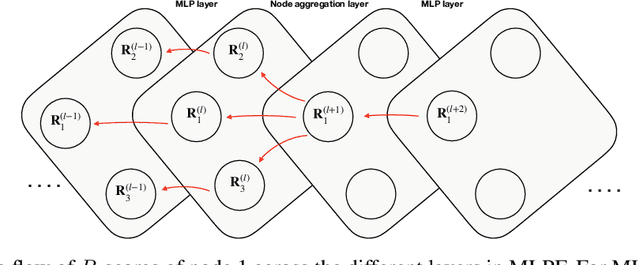
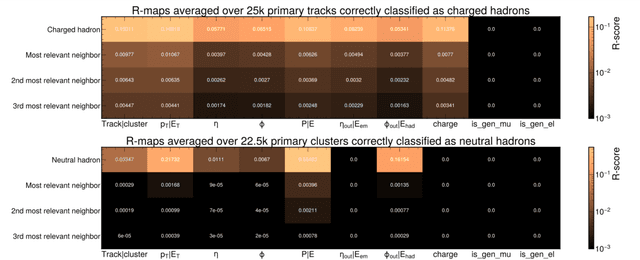
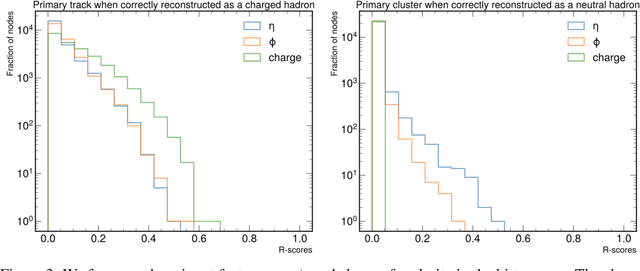
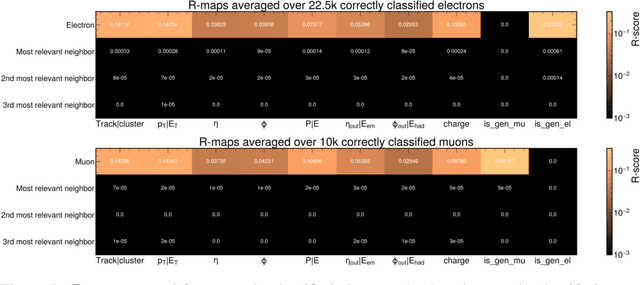
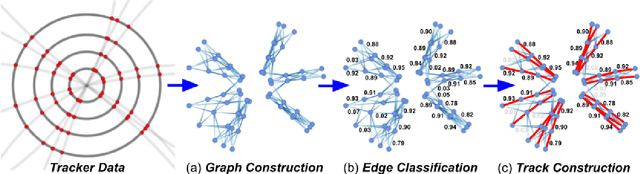
The particle-flow (PF) algorithm is used in general-purpose particle detectors to reconstruct a comprehensive particle-level view of the collision by combining information from different subdetectors. A graph neural network (GNN) model, known as the machine-learned particle-flow (MLPF) algorithm, has been developed to substitute the rule-based PF algorithm. However, understanding the model's decision making is not straightforward, especially given the complexity of the set-to-set prediction task, dynamic graph building, and message-passing steps. In this paper, we adapt the layerwise-relevance propagation technique for GNNs and apply it to the MLPF algorithm to gauge the relevant nodes and features for its predictions. Through this process, we gain insight into the model's decision-making.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021
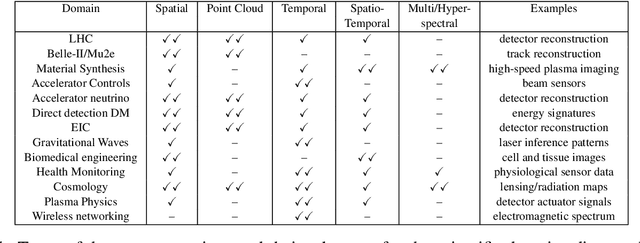
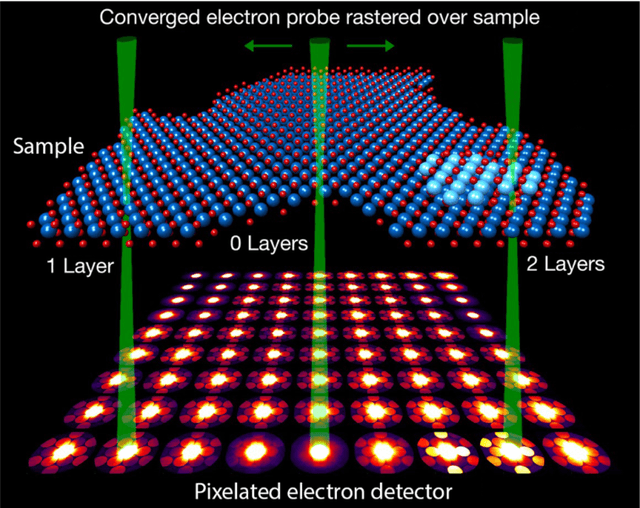
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.
A FAIR and AI-ready Higgs Boson Decay Dataset
Aug 04, 2021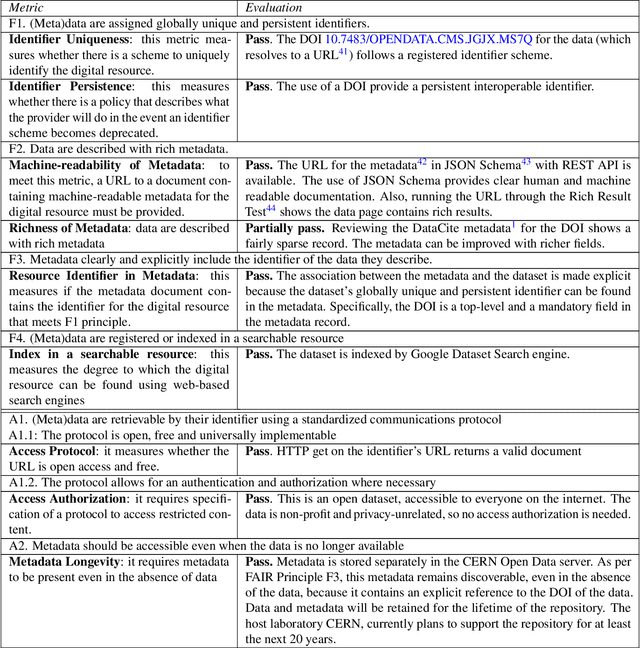
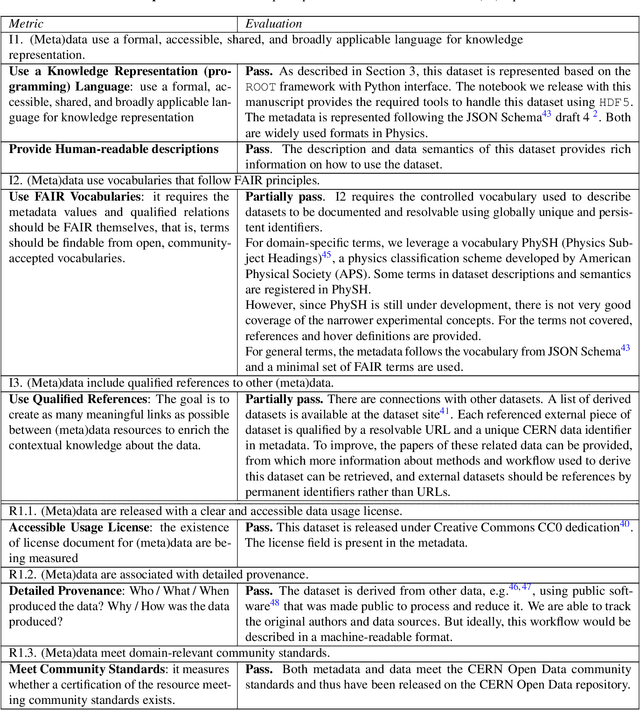
To enable the reusability of massive scientific datasets by humans and machines, researchers aim to create scientific datasets that adhere to the principles of findability, accessibility, interoperability, and reusability (FAIR) for data and artificial intelligence (AI) models. This article provides a domain-agnostic, step-by-step assessment guide to evaluate whether or not a given dataset meets each FAIR principle. We then demonstrate how to use this guide to evaluate the FAIRness of an open simulated dataset produced by the CMS Collaboration at the CERN Large Hadron Collider. This dataset consists of Higgs boson decays and quark and gluon background, and is available through the CERN Open Data Portal. We also use other available tools to assess the FAIRness of this dataset, and incorporate feedback from members of the FAIR community to validate our results. This article is accompanied by a Jupyter notebook to facilitate an understanding and exploration of the dataset, including visualization of its elements. This study marks the first in a planned series of articles that will guide scientists in the creation and quantification of FAIRness in high energy particle physics datasets and AI models.
Estimation of 2D Velocity Model using Acoustic Signals and Convolutional Neural Networks
Jun 10, 2019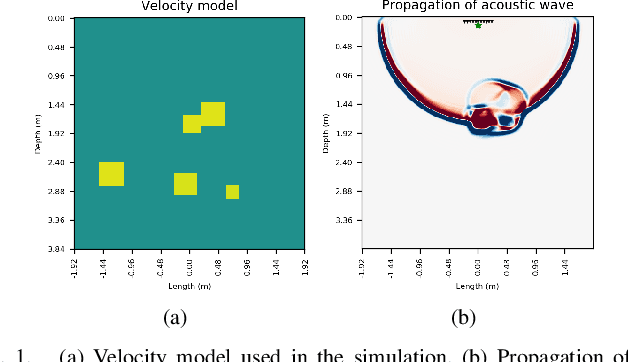
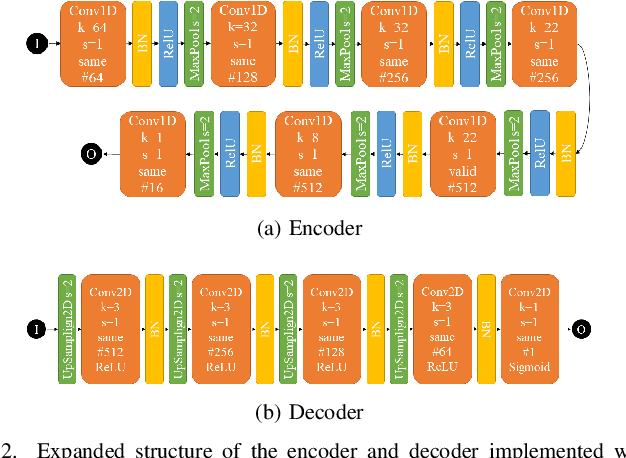
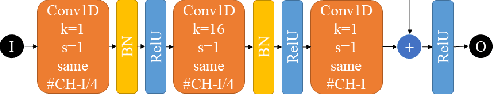

The parameters estimation of a system using indirect measurements over the same system is a problem that occurs in many fields of engineering, known as the inverse problem. It also happens in the field of underwater acoustic, especially in mediums that are not transparent enough. In those cases, shape identification of objects using only acoustic signals is a challenge because it is carried out with information of echoes that are produced by objects with different densities from that of the medium. In general, these echoes are difficult to understand since their information is usually noisy and redundant. In this paper, we propose a model of convolutional neural network with an Encoder-Decoder configuration to estimate both localization and shape of objects, which produce reflected signals. This model allows us to obtain a 2D velocity model. The model was trained with data generated by the finite-difference method, and it achieved a value of 98.58% in the intersection over union metric 75.88% in precision and 64.69% in sensibility.
On the Implementation of GNU Prolog
Dec 15, 2010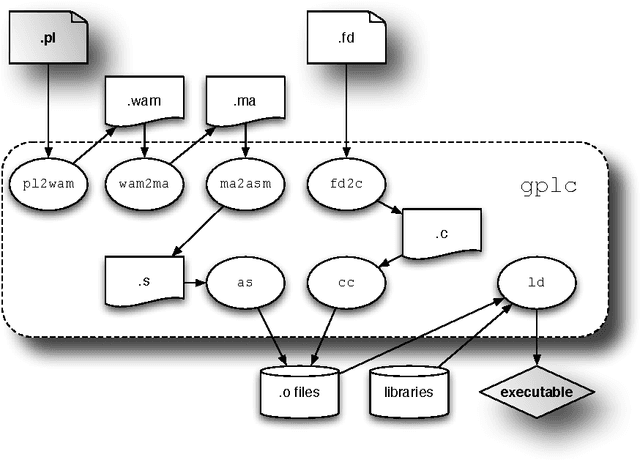

GNU Prolog is a general-purpose implementation of the Prolog language, which distinguishes itself from most other systems by being, above all else, a native-code compiler which produces standalone executables which don't rely on any byte-code emulator or meta-interpreter. Other aspects which stand out include the explicit organization of the Prolog system as a multipass compiler, where intermediate representations are materialized, in Unix compiler tradition. GNU Prolog also includes an extensible and high-performance finite domain constraint solver, integrated with the Prolog language but implemented using independent lower-level mechanisms. This article discusses the main issues involved in designing and implementing GNU Prolog: requirements, system organization, performance and portability issues as well as its position with respect to other Prolog system implementations and the ISO standardization initiative.