 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Parametric Nitrogen Fertilizer Response Curves Using Neuro Symbolic Regression
May 29, 2026Accurately modeling crop response to Nitrogen (N) fertilization is a fundamental challenge in precision agriculture, as it impacts both economic returns and environmental sustainability. Existing approaches either rely on predefined parametric forms or opaque machine learning models, limiting their ability to interpret or discover site-specific functional relationships from data. In this work, we propose a neuro symbolic regression (SR) approach to learn parametric N-response curves without assuming a predefined functional form. Our approach integrates a transformer-based Multi-Set Symbolic Skeleton Prediction strategy, enabling the discovery of shared functional structures across multiple subdomains or management zones (MZs). By constructing diverse input subsets and enforcing consistency across them, the method recovers robust symbolic skeletons that are subsequently fitted to observed data using a genetic algorithm. This framework was first evaluated on synthetic one-dimensional problems to assess its robustness under varying levels of epistemic uncertainty. The results demonstrate the ability of the proposed SR approach to recover correct expressions even in data-scarce regimes. In this work, we present the results of applying our method to real-world winter wheat data, learning distinct parametric N-response curves for different MZs within a field. The results show that the discovered expressions not only achieve lower fitting errors than traditional models such as quadratic-plateau and exponential functions, but also capture diverse functional behaviors across spatial regions. This demonstrates the potential that neuro SR has to enable the discovery of site-specific agronomic relationships and support informed decision-making in precision agriculture.
Neutrino Oscillation Parameter Estimation Using Structured Hierarchical Transformers
Mar 21, 2026Neutrino oscillations encode fundamental information about neutrino masses and mixing parameters, offering a unique window into physics beyond the Standard Model. Estimating these parameters from oscillation probability maps is, however, computationally challenging due to the maps' high dimensionality and nonlinear dependence on the underlying physics. Traditional inference methods, such as likelihood-based or Monte Carlo sampling approaches, require extensive simulations to explore the parameter space, creating major bottlenecks for large-scale analyses. In this work, we introduce a data-driven framework that reformulates atmospheric neutrino oscillation parameter inference as a supervised regression task over structured oscillation maps. We propose a hierarchical transformer architecture that explicitly models the two-dimensional structure of these maps, capturing angular dependencies at fixed energies and global correlations across the energy spectrum. To improve physical consistency, the model is trained using a surrogate simulation constraint that enforces agreement between the predicted parameters and the reconstructed oscillation patterns. Furthermore, we introduce a neural network-based uncertainty quantification mechanism that produces distribution-free prediction intervals with formal coverage guarantees. Experiments on simulated oscillation maps under Earth-matter conditions demonstrate that the proposed method is comparable to a Markov Chain Monte Carlo baseline in estimation accuracy, with substantial improvements in computational cost (around 240$\times$ fewer FLOPs and 33$\times$ faster in average processing time). Moreover, the conformally calibrated prediction intervals remain narrow while achieving the target nominal coverage of 90%, confirming both the reliability and efficiency of our approach.
Towards Uncertainty Quantification in Generative Model Learning
Nov 13, 2025While generative models have become increasingly prevalent across various domains, fundamental concerns regarding their reliability persist. A crucial yet understudied aspect of these models is the uncertainty quantification surrounding their distribution approximation capabilities. Current evaluation methodologies focus predominantly on measuring the closeness between the learned and the target distributions, neglecting the inherent uncertainty in these measurements. In this position paper, we formalize the problem of uncertainty quantification in generative model learning. We discuss potential research directions, including the use of ensemble-based precision-recall curves. Our preliminary experiments on synthetic datasets demonstrate the effectiveness of aggregated precision-recall curves in capturing model approximation uncertainty, enabling systematic comparison among different model architectures based on their uncertainty characteristics.
Decomposable Neuro Symbolic Regression
Nov 06, 2025
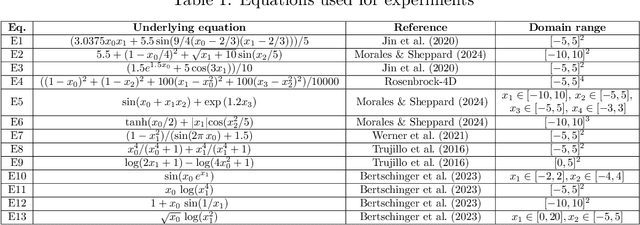
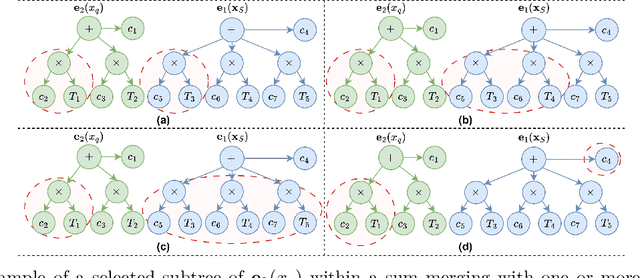
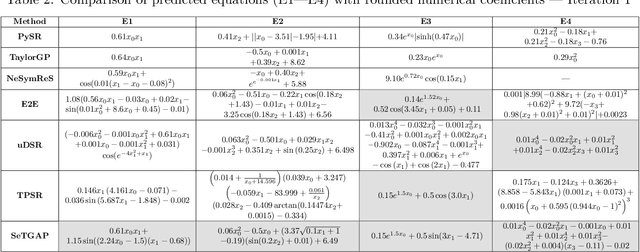
Symbolic regression (SR) models complex systems by discovering mathematical expressions that capture underlying relationships in observed data. However, most SR methods prioritize minimizing prediction error over identifying the governing equations, often producing overly complex or inaccurate expressions. To address this, we present a decomposable SR method that generates interpretable multivariate expressions leveraging transformer models, genetic algorithms (GAs), and genetic programming (GP). In particular, our explainable SR method distills a trained ``opaque'' regression model into mathematical expressions that serve as explanations of its computed function. Our method employs a Multi-Set Transformer to generate multiple univariate symbolic skeletons that characterize how each variable influences the opaque model's response. We then evaluate the generated skeletons' performance using a GA-based approach to select a subset of high-quality candidates before incrementally merging them via a GP-based cascade procedure that preserves their original skeleton structure. The final multivariate skeletons undergo coefficient optimization via a GA. We evaluated our method on problems with controlled and varying degrees of noise, demonstrating lower or comparable interpolation and extrapolation errors compared to two GP-based methods, three neural SR methods, and a hybrid approach. Unlike them, our approach consistently learned expressions that matched the original mathematical structure.
Adaptive Sampling to Reduce Epistemic Uncertainty Using Prediction Interval-Generation Neural Networks
Dec 13, 2024



Obtaining high certainty in predictive models is crucial for making informed and trustworthy decisions in many scientific and engineering domains. However, extensive experimentation required for model accuracy can be both costly and time-consuming. This paper presents an adaptive sampling approach designed to reduce epistemic uncertainty in predictive models. Our primary contribution is the development of a metric that estimates potential epistemic uncertainty leveraging prediction interval-generation neural networks. This estimation relies on the distance between the predicted upper and lower bounds and the observed data at the tested positions and their neighboring points. Our second contribution is the proposal of a batch sampling strategy based on Gaussian processes (GPs). A GP is used as a surrogate model of the networks trained at each iteration of the adaptive sampling process. Using this GP, we design an acquisition function that selects a combination of sampling locations to maximize the reduction of epistemic uncertainty across the domain. We test our approach on three unidimensional synthetic problems and a multi-dimensional dataset based on an agricultural field for selecting experimental fertilizer rates. The results demonstrate that our method consistently converges faster to minimum epistemic uncertainty levels compared to Normalizing Flows Ensembles, MC-Dropout, and simple GPs.
Univariate Skeleton Prediction in Multivariate Systems Using Transformers
Jun 25, 2024Symbolic regression (SR) methods attempt to learn mathematical expressions that approximate the behavior of an observed system. However, when dealing with multivariate systems, they often fail to identify the functional form that explains the relationship between each variable and the system's response. To begin to address this, we propose an explainable neural SR method that generates univariate symbolic skeletons that aim to explain how each variable influences the system's response. By analyzing multiple sets of data generated artificially, where one input variable varies while others are fixed, relationships are modeled separately for each input variable. The response of such artificial data sets is estimated using a regression neural network (NN). Finally, the multiple sets of input-response pairs are processed by a pre-trained Multi-Set Transformer that solves a problem we termed Multi-Set Skeleton Prediction and outputs a univariate symbolic skeleton. Thus, such skeletons represent explanations of the function approximated by the regression NN. Experimental results demonstrate that this method learns skeleton expressions matching the underlying functions and outperforms two GP-based and two neural SR methods.
Counterfactual Analysis of Neural Networks Used to Create Fertilizer Management Zones
Mar 15, 2024



In Precision Agriculture, the utilization of management zones (MZs) that take into account within-field variability facilitates effective fertilizer management. This approach enables the optimization of nitrogen (N) rates to maximize crop yield production and enhance agronomic use efficiency. However, existing works often neglect the consideration of responsivity to fertilizer as a factor influencing MZ determination. In response to this gap, we present a MZ clustering method based on fertilizer responsivity. We build upon the statement that the responsivity of a given site to the fertilizer rate is described by the shape of its corresponding N fertilizer-yield response (N-response) curve. Thus, we generate N-response curves for all sites within the field using a convolutional neural network (CNN). The shape of the approximated N-response curves is then characterized using functional principal component analysis. Subsequently, a counterfactual explanation (CFE) method is applied to discern the impact of various variables on MZ membership. The genetic algorithm-based CFE solves a multi-objective optimization problem and aims to identify the minimum combination of features needed to alter a site's cluster assignment. Results from two yield prediction datasets indicate that the features with the greatest influence on MZ membership are associated with terrain characteristics that either facilitate or impede fertilizer runoff, such as terrain slope or topographic aspect.
Counterfactual Explanations of Neural Network-Generated Response Curves
Apr 13, 2023



Response curves exhibit the magnitude of the response of a sensitive system to a varying stimulus. However, response of such systems may be sensitive to multiple stimuli (i.e., input features) that are not necessarily independent. As a consequence, the shape of response curves generated for a selected input feature (referred to as "active feature") might depend on the values of the other input features (referred to as "passive features"). In this work, we consider the case of systems whose response is approximated using regression neural networks. We propose to use counterfactual explanations (CFEs) for the identification of the features with the highest relevance on the shape of response curves generated by neural network black boxes. CFEs are generated by a genetic algorithm-based approach that solves a multi-objective optimization problem. In particular, given a response curve generated for an active feature, a CFE finds the minimum combination of passive features that need to be modified to alter the shape of the response curve. We tested our method on a synthetic dataset with 1-D inputs and two crop yield prediction datasets with 2-D inputs. The relevance ranking of features and feature combinations obtained on the synthetic dataset coincided with the analysis of the equation that was used to generate the problem. Results obtained on the yield prediction datasets revealed that the impact on fertilizer responsivity of passive features depends on the terrain characteristics of each field.
Dual Accuracy-Quality-Driven Neural Network for Prediction Interval Generation
Dec 13, 2022



Accurate uncertainty quantification is necessary to enhance the reliability of deep learning models in real-world applications. In the case of regression tasks, prediction intervals (PIs) should be provided along with the deterministic predictions of deep learning models. Such PIs are useful or "high-quality'' as long as they are sufficiently narrow and capture most of the probability density. In this paper, we present a method to learn prediction intervals for regression-based neural networks automatically in addition to the conventional target predictions. In particular, we train two companion neural networks: one that uses one output, the target estimate, and another that uses two outputs, the upper and lower bounds of the corresponding PI. Our main contribution is the design of a loss function for the PI-generation network that takes into account the output of the target-estimation network and has two optimization objectives: minimizing the mean prediction interval width and ensuring the PI integrity using constraints that maximize the prediction interval probability coverage implicitly. Both objectives are balanced within the loss function using a self-adaptive coefficient. Furthermore, we apply a Monte Carlo-based approach that evaluates the model uncertainty in the learned PIs. Experiments using a synthetic dataset, six benchmark datasets, and a real-world crop yield prediction dataset showed that our method was able to maintain a nominal probability coverage and produce narrower PIs without detriment to its target estimation accuracy when compared to those PIs generated by three state-of-the-art neural-network-based methods.
Two-dimensional Deep Regression for Early Yield Prediction of Winter Wheat
Nov 15, 2021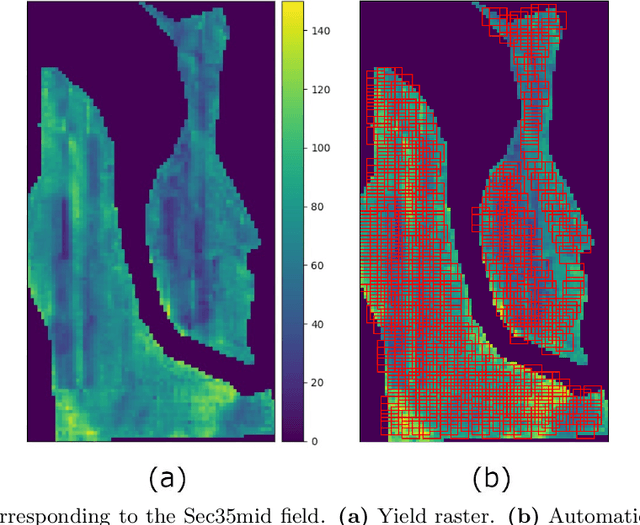
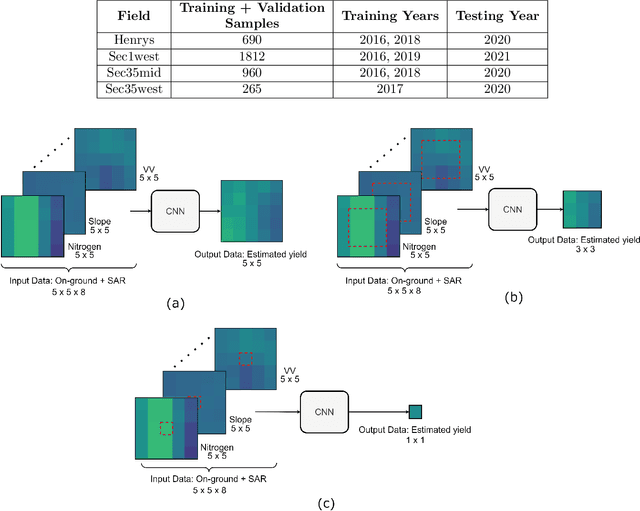
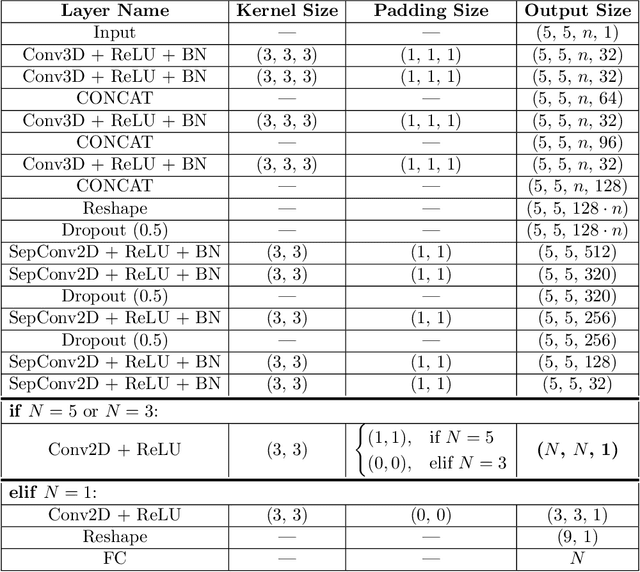
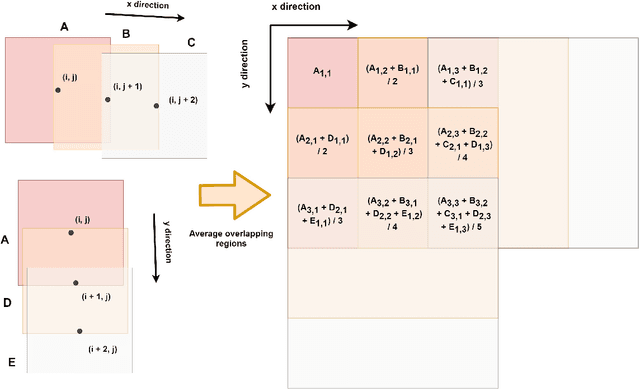
Crop yield prediction is one of the tasks of Precision Agriculture that can be automated based on multi-source periodic observations of the fields. We tackle the yield prediction problem using a Convolutional Neural Network (CNN) trained on data that combines radar satellite imagery and on-ground information. We present a CNN architecture called Hyper3DNetReg that takes in a multi-channel input image and outputs a two-dimensional raster, where each pixel represents the predicted yield value of the corresponding input pixel. We utilize radar data acquired from the Sentinel-1 satellites, while the on-ground data correspond to a set of six raster features: nitrogen rate applied, precipitation, slope, elevation, topographic position index (TPI), and aspect. We use data collected during the early stage of the winter wheat growing season (March) to predict yield values during the harvest season (August). We present experiments over four fields of winter wheat and show that our proposed methodology yields better results than five compared methods, including multiple linear regression, an ensemble of feedforward networks using AdaBoost, a stacked autoencoder, and two other CNN architectures.