 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral bias in physics-informed and operator learning: Analysis and mitigation guidelines
Feb 22, 2026Solving partial differential equations (PDEs) by neural networks as well as Kolmogorov-Arnold Networks (KANs), including physics-informed neural networks (PINNs), physics-informed KANs (PIKANs), and neural operators, are known to exhibit spectral bias, whereby low-frequency components of the solution are learned significantly faster than high-frequency modes. While spectral bias is often treated as an intrinsic representational limitation of neural architectures, its interaction with optimization dynamics and physics-based loss formulations remains poorly understood. In this work, we provide a systematic investigation of spectral bias in physics-informed and operator learning frameworks, with emphasis on the coupled roles of network architecture, activation functions, loss design, and optimization strategy. We quantify spectral bias through frequency-resolved error metrics, Barron-norm diagnostics, and higher-order statistical moments, enabling a unified analysis across elliptic, hyperbolic, and dispersive PDEs. Through diverse benchmark problems, including the Korteweg-de Vries, wave and steady-state diffusion-reaction equations, turbulent flow reconstruction, and earthquake dynamics, we demonstrate that spectral bias is not simply representational but fundamentally dynamical. In particular, second-order optimization methods substantially alter the spectral learning order, enabling earlier and more accurate recovery of high-frequency modes for all PDE types. For neural operators, we further show that spectral bias is dependent on the neural operator architecture and can also be effectively mitigated through spectral-aware loss formulations without increasing the inference cost.
Importance of localized dilatation and distensibility in identifying determinants of thoracic aortic aneurysm with neural operators
Sep 30, 2025Thoracic aortic aneurysms (TAAs) arise from diverse mechanical and mechanobiological disruptions to the aortic wall that increase the risk of dissection or rupture. Evidence links TAA development to dysfunctions in the aortic mechanotransduction axis, including loss of elastic fiber integrity and cell-matrix connections. Because distinct insults create different mechanical vulnerabilities, there is a critical need to identify interacting factors that drive progression. Here, we use a finite element framework to generate synthetic TAAs from hundreds of heterogeneous insults spanning varying degrees of elastic fiber damage and impaired mechanosensing. From these simulations, we construct spatial maps of localized dilatation and distensibility to train neural networks that predict the initiating combined insult. We compare several architectures (Deep Operator Networks, UNets, and Laplace Neural Operators) and multiple input data formats to define a standard for future subject-specific modeling. We also quantify predictive performance when networks are trained using only geometric data (dilatation) versus both geometric and mechanical data (dilatation plus distensibility). Across all networks, prediction errors are significantly higher when trained on dilatation alone, underscoring the added value of distensibility information. Among the tested models, UNet consistently provides the highest accuracy across all data formats. These findings highlight the importance of acquiring full-field measurements of both dilatation and distensibility in TAA assessment to reveal the mechanobiological drivers of disease and support the development of personalized treatment strategies.
A Variational Framework for Residual-Based Adaptivity in Neural PDE Solvers and Operator Learning
Sep 17, 2025Residual-based adaptive strategies are widely used in scientific machine learning but remain largely heuristic. We introduce a unifying variational framework that formalizes these methods by integrating convex transformations of the residual. Different transformations correspond to distinct objective functionals: exponential weights target the minimization of uniform error, while linear weights recover the minimization of quadratic error. Within this perspective, adaptive weighting is equivalent to selecting sampling distributions that optimize the primal objective, thereby linking discretization choices directly to error metrics. This principled approach yields three benefits: (1) it enables systematic design of adaptive schemes across norms, (2) reduces discretization error through variance reduction of the loss estimator, and (3) enhances learning dynamics by improving the gradient signal-to-noise ratio. Extending the framework to operator learning, we demonstrate substantial performance gains across optimizers and architectures. Our results provide a theoretical justification of residual-based adaptivity and establish a foundation for principled discretization and training strategies.
Learning Turbulent Flows with Generative Models: Super-resolution, Forecasting, and Sparse Flow Reconstruction
Sep 10, 2025



Neural operators are promising surrogates for dynamical systems but when trained with standard L2 losses they tend to oversmooth fine-scale turbulent structures. Here, we show that combining operator learning with generative modeling overcomes this limitation. We consider three practical turbulent-flow challenges where conventional neural operators fail: spatio-temporal super-resolution, forecasting, and sparse flow reconstruction. For Schlieren jet super-resolution, an adversarially trained neural operator (adv-NO) reduces the energy-spectrum error by 15x while preserving sharp gradients at neural operator-like inference cost. For 3D homogeneous isotropic turbulence, adv-NO trained on only 160 timesteps from a single trajectory forecasts accurately for five eddy-turnover times and offers 114x wall-clock speed-up at inference than the baseline diffusion-based forecasters, enabling near-real-time rollouts. For reconstructing cylinder wake flows from highly sparse Particle Tracking Velocimetry-like inputs, a conditional generative model infers full 3D velocity and pressure fields with correct phase alignment and statistics. These advances enable accurate reconstruction and forecasting at low compute cost, bringing near-real-time analysis and control within reach in experimental and computational fluid mechanics. See our project page: https://vivekoommen.github.io/Gen4Turb/
Equilibrium Conserving Neural Operators for Super-Resolution Learning
Apr 18, 2025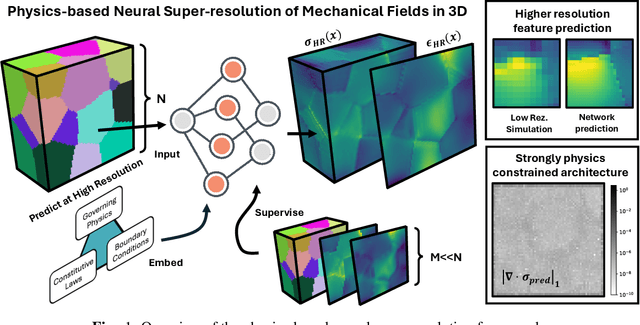
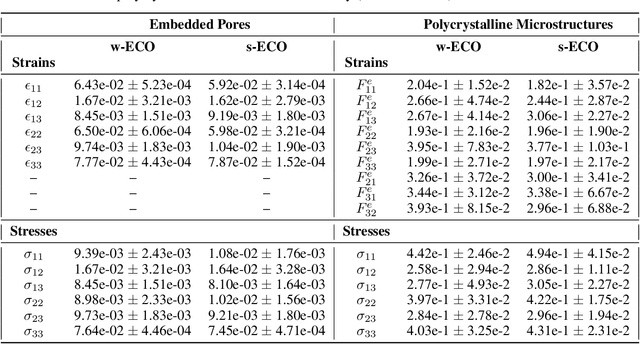
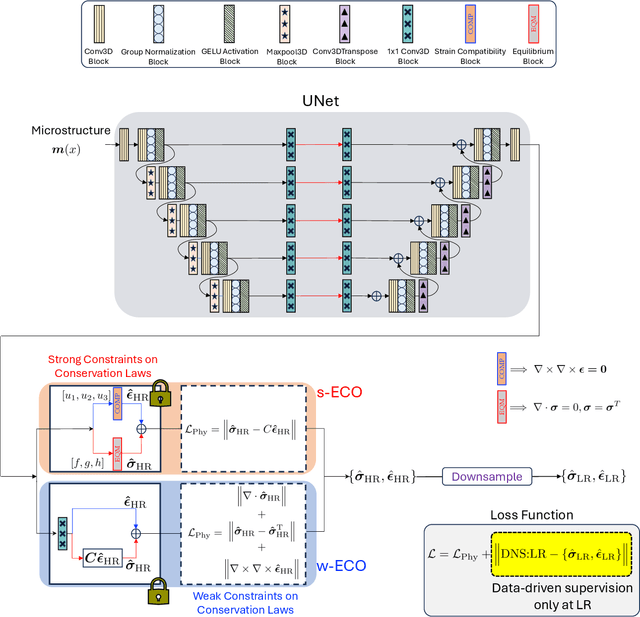
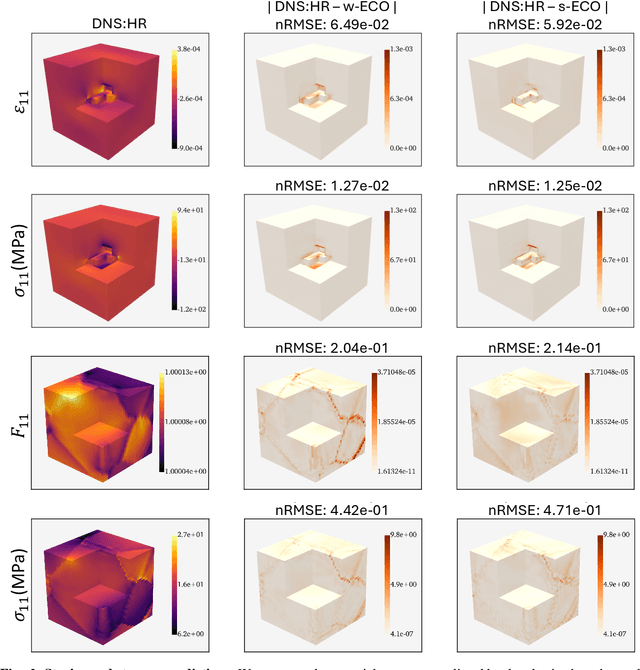
Neural surrogate solvers can estimate solutions to partial differential equations in physical problems more efficiently than standard numerical methods, but require extensive high-resolution training data. In this paper, we break this limitation; we introduce a framework for super-resolution learning in solid mechanics problems. Our approach allows one to train a high-resolution neural network using only low-resolution data. Our Equilibrium Conserving Operator (ECO) architecture embeds known physics directly into the network to make up for missing high-resolution information during training. We evaluate this ECO-based super-resolution framework that strongly enforces conservation-laws in the predicted solutions on two working examples: embedded pores in a homogenized matrix and randomly textured polycrystalline materials. ECO eliminates the reliance on high-fidelity data and reduces the upfront cost of data collection by two orders of magnitude, offering a robust pathway for resource-efficient surrogate modeling in materials modeling. ECO is readily generalizable to other physics-based problems.
Mitigating Spectral Bias in Neural Operators via High-Frequency Scaling for Physical Systems
Mar 17, 2025Neural operators have emerged as powerful surrogates for modeling complex physical problems. However, they suffer from spectral bias making them oblivious to high-frequency modes, which are present in multiscale physical systems. Therefore, they tend to produce over-smoothed solutions, which is particularly problematic in modeling turbulence and for systems with intricate patterns and sharp gradients such as multi-phase flow systems. In this work, we introduce a new approach named high-frequency scaling (HFS) to mitigate spectral bias in convolutional-based neural operators. By integrating HFS with proper variants of UNet neural operators, we demonstrate a higher prediction accuracy by mitigating spectral bias in single and two-phase flow problems. Unlike Fourier-based techniques, HFS is directly applied to the latent space, thus eliminating the computational cost associated with the Fourier transform. Additionally, we investigate alternative spectral bias mitigation through diffusion models conditioned on neural operators. While the diffusion model integrated with the standard neural operator may still suffer from significant errors, these errors are substantially reduced when the diffusion model is integrated with a HFS-enhanced neural operator.
XAI4Extremes: An interpretable machine learning framework for understanding extreme-weather precursors under climate change
Mar 11, 2025Extreme weather events are increasing in frequency and intensity due to climate change. This, in turn, is exacting a significant toll in communities worldwide. While prediction skills are increasing with advances in numerical weather prediction and artificial intelligence tools, extreme weather still present challenges. More specifically, identifying the precursors of such extreme weather events and how these precursors may evolve under climate change remain unclear. In this paper, we propose to use post-hoc interpretability methods to construct relevance weather maps that show the key extreme-weather precursors identified by deep learning models. We then compare this machine view with existing domain knowledge to understand whether deep learning models identified patterns in data that may enrich our understanding of extreme-weather precursors. We finally bin these relevant maps into different multi-year time periods to understand the role that climate change is having on these precursors. The experiments are carried out on Indochina heatwaves, but the methodology can be readily extended to other extreme weather events worldwide.
From PINNs to PIKANs: Recent Advances in Physics-Informed Machine Learning
Oct 17, 2024



Physics-Informed Neural Networks (PINNs) have emerged as a key tool in Scientific Machine Learning since their introduction in 2017, enabling the efficient solution of ordinary and partial differential equations using sparse measurements. Over the past few years, significant advancements have been made in the training and optimization of PINNs, covering aspects such as network architectures, adaptive refinement, domain decomposition, and the use of adaptive weights and activation functions. A notable recent development is the Physics-Informed Kolmogorov-Arnold Networks (PIKANS), which leverage a representation model originally proposed by Kolmogorov in 1957, offering a promising alternative to traditional PINNs. In this review, we provide a comprehensive overview of the latest advancements in PINNs, focusing on improvements in network design, feature expansion, optimization techniques, uncertainty quantification, and theoretical insights. We also survey key applications across a range of fields, including biomedicine, fluid and solid mechanics, geophysics, dynamical systems, heat transfer, chemical engineering, and beyond. Finally, we review computational frameworks and software tools developed by both academia and industry to support PINN research and applications.
Integrating Neural Operators with Diffusion Models Improves Spectral Representation in Turbulence Modeling
Sep 13, 2024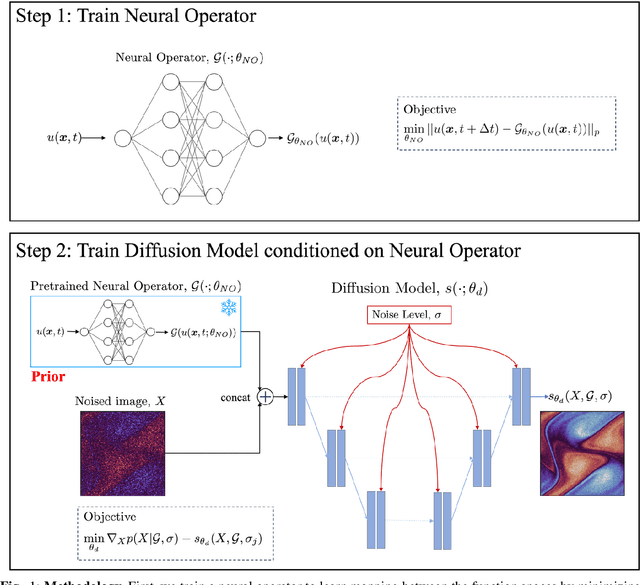
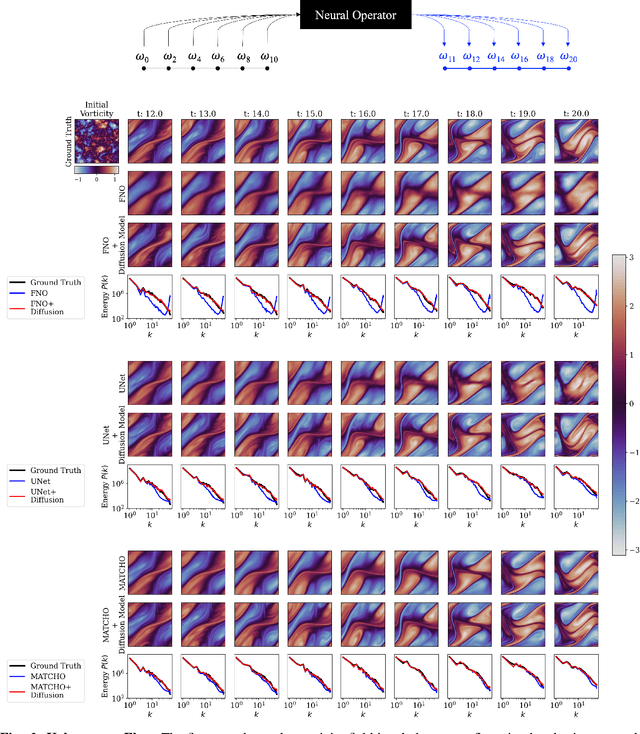
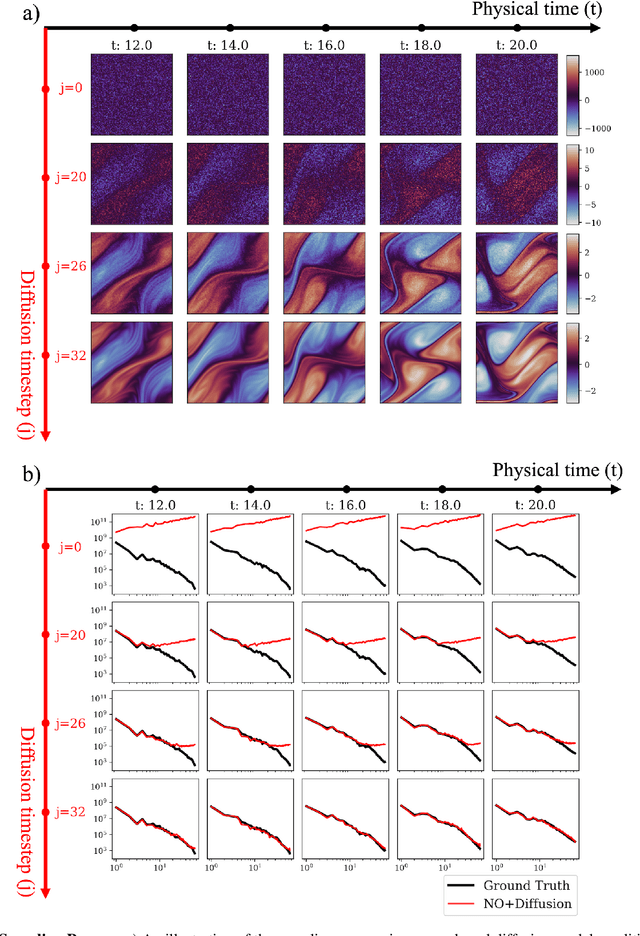

We integrate neural operators with diffusion models to address the spectral limitations of neural operators in surrogate modeling of turbulent flows. While neural operators offer computational efficiency, they exhibit deficiencies in capturing high-frequency flow dynamics, resulting in overly smooth approximations. To overcome this, we condition diffusion models on neural operators to enhance the resolution of turbulent structures. Our approach is validated for different neural operators on diverse datasets, including a high Reynolds number jet flow simulation and experimental Schlieren velocimetry. The proposed method significantly improves the alignment of predicted energy spectra with true distributions compared to neural operators alone. Additionally, proper orthogonal decomposition analysis demonstrates enhanced spectral fidelity in space-time. This work establishes a new paradigm for combining generative models with neural operators to advance surrogate modeling of turbulent systems, and it can be used in other scientific applications that involve microstructure and high-frequency content. See our project page: vivekoommen.github.io/NO_DM
RiemannONets: Interpretable Neural Operators for Riemann Problems
Jan 16, 2024



Developing the proper representations for simulating high-speed flows with strong shock waves, rarefactions, and contact discontinuities has been a long-standing question in numerical analysis. Herein, we employ neural operators to solve Riemann problems encountered in compressible flows for extreme pressure jumps (up to $10^{10}$ pressure ratio). In particular, we first consider the DeepONet that we train in a two-stage process, following the recent work of Lee and Shin, wherein the first stage, a basis is extracted from the trunk net, which is orthonormalized and subsequently is used in the second stage in training the branch net. This simple modification of DeepONet has a profound effect on its accuracy, efficiency, and robustness and leads to very accurate solutions to Riemann problems compared to the vanilla version. It also enables us to interpret the results physically as the hierarchical data-driven produced basis reflects all the flow features that would otherwise be introduced using ad hoc feature expansion layers. We also compare the results with another neural operator based on the U-Net for low, intermediate, and very high-pressure ratios that are very accurate for Riemann problems, especially for large pressure ratios, due to their multiscale nature but computationally more expensive. Overall, our study demonstrates that simple neural network architectures, if properly pre-trained, can achieve very accurate solutions of Riemann problems for real-time forecasting.