 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Variational Framework for Residual-Based Adaptivity in Neural PDE Solvers and Operator Learning
Sep 17, 2025Residual-based adaptive strategies are widely used in scientific machine learning but remain largely heuristic. We introduce a unifying variational framework that formalizes these methods by integrating convex transformations of the residual. Different transformations correspond to distinct objective functionals: exponential weights target the minimization of uniform error, while linear weights recover the minimization of quadratic error. Within this perspective, adaptive weighting is equivalent to selecting sampling distributions that optimize the primal objective, thereby linking discretization choices directly to error metrics. This principled approach yields three benefits: (1) it enables systematic design of adaptive schemes across norms, (2) reduces discretization error through variance reduction of the loss estimator, and (3) enhances learning dynamics by improving the gradient signal-to-noise ratio. Extending the framework to operator learning, we demonstrate substantial performance gains across optimizers and architectures. Our results provide a theoretical justification of residual-based adaptivity and establish a foundation for principled discretization and training strategies.
KKANs: Kurkova-Kolmogorov-Arnold Networks and Their Learning Dynamics
Dec 21, 2024Inspired by the Kolmogorov-Arnold representation theorem and Kurkova's principle of using approximate representations, we propose the Kurkova-Kolmogorov-Arnold Network (KKAN), a new two-block architecture that combines robust multi-layer perceptron (MLP) based inner functions with flexible linear combinations of basis functions as outer functions. We first prove that KKAN is a universal approximator, and then we demonstrate its versatility across scientific machine-learning applications, including function regression, physics-informed machine learning (PIML), and operator-learning frameworks. The benchmark results show that KKANs outperform MLPs and the original Kolmogorov-Arnold Networks (KANs) in function approximation and operator learning tasks and achieve performance comparable to fully optimized MLPs for PIML. To better understand the behavior of the new representation models, we analyze their geometric complexity and learning dynamics using information bottleneck theory, identifying three universal learning stages, fitting, transition, and diffusion, across all types of architectures. We find a strong correlation between geometric complexity and signal-to-noise ratio (SNR), with optimal generalization achieved during the diffusion stage. Additionally, we propose self-scaled residual-based attention weights to maintain high SNR dynamically, ensuring uniform convergence and prolonged learning.
From PINNs to PIKANs: Recent Advances in Physics-Informed Machine Learning
Oct 17, 2024



Physics-Informed Neural Networks (PINNs) have emerged as a key tool in Scientific Machine Learning since their introduction in 2017, enabling the efficient solution of ordinary and partial differential equations using sparse measurements. Over the past few years, significant advancements have been made in the training and optimization of PINNs, covering aspects such as network architectures, adaptive refinement, domain decomposition, and the use of adaptive weights and activation functions. A notable recent development is the Physics-Informed Kolmogorov-Arnold Networks (PIKANS), which leverage a representation model originally proposed by Kolmogorov in 1957, offering a promising alternative to traditional PINNs. In this review, we provide a comprehensive overview of the latest advancements in PINNs, focusing on improvements in network design, feature expansion, optimization techniques, uncertainty quantification, and theoretical insights. We also survey key applications across a range of fields, including biomedicine, fluid and solid mechanics, geophysics, dynamical systems, heat transfer, chemical engineering, and beyond. Finally, we review computational frameworks and software tools developed by both academia and industry to support PINN research and applications.
Inferring turbulent velocity and temperature fields and their statistics from Lagrangian velocity measurements using physics-informed Kolmogorov-Arnold Networks
Jul 23, 2024



We propose the Artificial Intelligence Velocimetry-Thermometry (AIVT) method to infer hidden temperature fields from experimental turbulent velocity data. This physics-informed machine learning method enables us to infer continuous temperature fields using only sparse velocity data, hence eliminating the need for direct temperature measurements. Specifically, AIVT is based on physics-informed Kolmogorov-Arnold Networks (not neural networks) and is trained by optimizing a combined loss function that minimizes the residuals of the velocity data, boundary conditions, and the governing equations. We apply AIVT to a unique set of experimental volumetric and simultaneous temperature and velocity data of Rayleigh-B\'enard convection (RBC) that we acquired by combining Particle Image Thermometry and Lagrangian Particle Tracking. This allows us to compare AIVT predictions and measurements directly. We demonstrate that we can reconstruct and infer continuous and instantaneous velocity and temperature fields from sparse experimental data at a fidelity comparable to direct numerical simulations (DNS) of turbulence. This, in turn, enables us to compute important quantities for quantifying turbulence, such as fluctuations, viscous and thermal dissipation, and QR distribution. This paradigm shift in processing experimental data using AIVT to infer turbulent fields at DNS-level fidelity is a promising avenue in breaking the current deadlock of quantitative understanding of turbulence at high Reynolds numbers, where DNS is computationally infeasible.
A comprehensive and FAIR comparison between MLP and KAN representations for differential equations and operator networks
Jun 05, 2024



Kolmogorov-Arnold Networks (KANs) were recently introduced as an alternative representation model to MLP. Herein, we employ KANs to construct physics-informed machine learning models (PIKANs) and deep operator models (DeepOKANs) for solving differential equations for forward and inverse problems. In particular, we compare them with physics-informed neural networks (PINNs) and deep operator networks (DeepONets), which are based on the standard MLP representation. We find that although the original KANs based on the B-splines parameterization lack accuracy and efficiency, modified versions based on low-order orthogonal polynomials have comparable performance to PINNs and DeepONet although they still lack robustness as they may diverge for different random seeds or higher order orthogonal polynomials. We visualize their corresponding loss landscapes and analyze their learning dynamics using information bottleneck theory. Our study follows the FAIR principles so that other researchers can use our benchmarks to further advance this emerging topic.
Learning in PINNs: Phase transition, total diffusion, and generalization
Mar 27, 2024



We investigate the learning dynamics of fully-connected neural networks through the lens of gradient signal-to-noise ratio (SNR), examining the behavior of first-order optimizers like Adam in non-convex objectives. By interpreting the drift/diffusion phases in the information bottleneck theory, focusing on gradient homogeneity, we identify a third phase termed ``total diffusion", characterized by equilibrium in the learning rates and homogeneous gradients. This phase is marked by an abrupt SNR increase, uniform residuals across the sample space and the most rapid training convergence. We propose a residual-based re-weighting scheme to accelerate this diffusion in quadratic loss functions, enhancing generalization. We also explore the information compression phenomenon, pinpointing a significant saturation-induced compression of activations at the total diffusion phase, with deeper layers experiencing negligible information loss. Supported by experimental data on physics-informed neural networks (PINNs), which underscore the importance of gradient homogeneity due to their PDE-based sample inter-dependence, our findings suggest that recognizing phase transitions could refine ML optimization strategies for improved generalization.
Residual-based attention and connection to information bottleneck theory in PINNs
Jul 01, 2023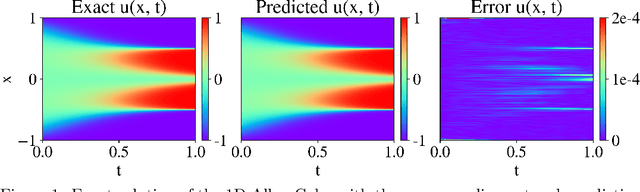
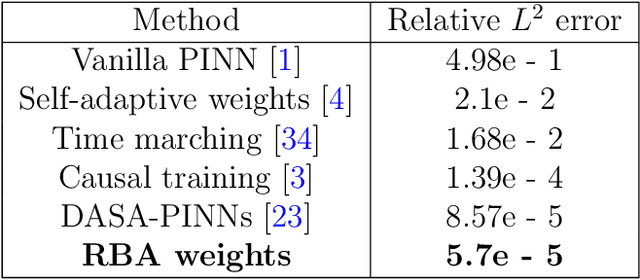
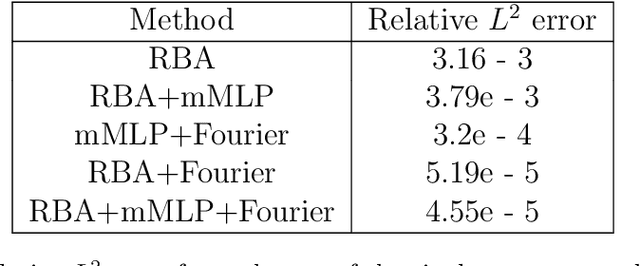
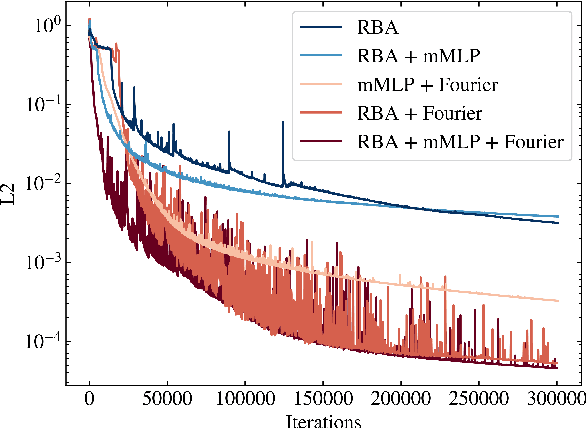
Driven by the need for more efficient and seamless integration of physical models and data, physics-informed neural networks (PINNs) have seen a surge of interest in recent years. However, ensuring the reliability of their convergence and accuracy remains a challenge. In this work, we propose an efficient, gradient-less weighting scheme for PINNs, that accelerates the convergence of dynamic or static systems. This simple yet effective attention mechanism is a function of the evolving cumulative residuals and aims to make the optimizer aware of problematic regions at no extra computational cost or adversarial learning. We illustrate that this general method consistently achieves a relative $L^{2}$ error of the order of $10^{-5}$ using standard optimizers on typical benchmark cases of the literature. Furthermore, by investigating the evolution of weights during training, we identify two distinct learning phases reminiscent of the fitting and diffusion phases proposed by the information bottleneck (IB) theory. Subsequent gradient analysis supports this hypothesis by aligning the transition from high to low signal-to-noise ratio (SNR) with the transition from fitting to diffusion regimes of the adopted weights. This novel correlation between PINNs and IB theory could open future possibilities for understanding the underlying mechanisms behind the training and stability of PINNs and, more broadly, of neural operators.