 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouteScan: A Non-Intrusive Approach to Auditing MoE LLMs Safety via Expert Routing Telemetry
May 24, 2026Mixture-of-Experts (MoE) architectures have become an increasingly important paradigm for scaling Large Language Models (LLMs). As MoE models are increasingly deployed in real-world services, safety auditing becomes necessary to verify whether these models produce or facilitate harmful behaviors during operation. However, existing content-based auditing methods typically require access to user prompts, model inputs, or generated outputs, potentially exposing sensitive user information and creating a fundamental tension between LLM safety and user privacy. On the other hand, we observe that, in MoE models, sparse expert routing maps different inputs to activate different expert-execution patterns, producing measurable footprints in low-level GPU execution telemetry. Inspired by this observation, we propose RouteScan, a non-intrusive auditing framework for detecting harmful behaviors through GPU-level expert routing telemetry. Specifically, RouteScan utilizes the number of active GPU threads allocated to expert modules during the prefilling phase as a discriminative micro-architectural fingerprint, and builds a lightweight detection pipeline that isolates cross-domain invariant risk indicators for the precise identification of malicious prompts. Comprehensive evaluations on open-source MoE LLMs with distinct routing designs demonstrate that RouteScan achieves strong generalization, with an AUROC exceeding 0.93 on unseen harmful domains and 0.96 under novel jailbreak wrappers. Moreover, empirical inversion tests show that the collected expert routing telemetry provides limited information for prompt reconstruction, suggesting a practical privacy advantage over content-based auditing methods.
LoopTrap: Termination Poisoning Attacks on LLM Agents
May 07, 2026Modern LLM agents solve complex tasks by operating in iterative execution loops, where they repeatedly reason, act, and self-evaluate progress to determine when a task is complete. In this work, we show that while this self-directed loop facilitates autonomy, it also introduces a critical risk: by injecting malicious prompts into the agent's context, an adversary can distort the agent's termination judgment, making it believe the task remains incomplete and leading to unbounded computation.To understand this threat, we define and systematically characterize it as Termination Poisoning and design 10 representative attack strategies. Through a empirical study spanning 8 LLM agents and 60 tasks, we demonstrate that different LLM agents exhibit distinct behavioral signatures that determine which strategies succeed. These transferable patterns can serve as principled guidance for crafting effective attacks against previously unseen agents and tasks, enabling scalable red-teaming beyond manually designed templates. Building on these insights, we introduce LoopTrap, an automated red-teaming framework that synthesizes target-specific malicious prompts by exploiting agent behavioral tendencies. LoopTrap first constructs a behavioral profile of the target agent along four vulnerability dimensions via lightweight probing. It then performs adaptive trap synthesis, routing to the most effective strategy and selecting optimal injections via a self-scoring mechanism. Finally, successful traps are abstracted into a reusable skill library, while failed attempts are refined through self-reflection, ensuring continuous improvement. Extensive evaluation shows that LoopTrap achieves an average of 3.57$\times$ step amplification across 8 mainstream agents, with a peak of 25$\times$.
DualSentinel: A Lightweight Framework for Detecting Targeted Attacks in Black-box LLM via Dual Entropy Lull Pattern
Mar 02, 2026Recent intelligent systems integrate powerful Large Language Models (LLMs) through APIs, but their trustworthiness may be critically undermined by targeted attacks like backdoor and prompt injection attacks, which secretly force LLMs to generate specific malicious sequences. Existing defensive approaches for such threats typically rely on high access rights, impose prohibitive costs, and hinder normal inference, rendering them impractical for real-world scenarios. To solve these limitations, we introduce DualSentinel, a lightweight and unified defense framework that can accurately and promptly detect the activation of targeted attacks alongside the LLM generation process. We first identify a characteristic of compromised LLMs, termed Entropy Lull: when a targeted attack successfully hijacks the generation process, the LLM exhibits a distinct period of abnormally low and stable token probability entropy, indicating it is following a fixed path rather than making creative choices. DualSentinel leverages this pattern by developing an innovative dual-check approach. It first employs a magnitude and trend-aware monitoring method to proactively and sensitively flag an entropy lull pattern at runtime. Upon such flagging, it triggers a lightweight yet powerful secondary verification based on task-flipping. An attack is confirmed only if the entropy lull pattern persists across both the original and the flipped task, proving that the LLM's output is coercively controlled. Extensive evaluations show that DualSentinel is both highly effective (superior detection accuracy with near-zero false positives) and remarkably efficient (negligible additional cost), offering a truly practical path toward securing deployed LLMs. The source code can be accessed at https://doi.org/10.5281/zenodo.18479273.
Attack-Resistant Watermarking for AIGC Image Forensics via Diffusion-based Semantic Deflection
Jan 10, 2026Protecting the copyright of user-generated AI images is an emerging challenge as AIGC becomes pervasive in creative workflows. Existing watermarking methods (1) remain vulnerable to real-world adversarial threats, often forced to trade off between defenses against spoofing and removal attacks; and (2) cannot support semantic-level tamper localization. We introduce PAI, a training-free inherent watermarking framework for AIGC copyright protection, plug-and-play with diffusion-based AIGC services. PAI simultaneously provides three key functionalities: robust ownership verification, attack detection, and semantic-level tampering localization. Unlike existing inherent watermark methods that only embed watermarks at noise initialization of diffusion models, we design a novel key-conditioned deflection mechanism that subtly steers the denoising trajectory according to the user key. Such trajectory-level coupling further strengthens the semantic entanglement of identity and content, thereby further enhancing robustness against real-world threats. Moreover, we also provide a theoretical analysis proving that only the valid key can pass verification. Experiments across 12 attack methods show that PAI achieves 98.43\% verification accuracy, improving over SOTA methods by 37.25\% on average, and retains strong tampering localization performance even against advanced AIGC edits. Our code is available at https://github.com/QingyuLiu/PAI.
TAP-ViTs: Task-Adaptive Pruning for On-Device Deployment of Vision Transformers
Jan 05, 2026Vision Transformers (ViTs) have demonstrated strong performance across a wide range of vision tasks, yet their substantial computational and memory demands hinder efficient deployment on resource-constrained mobile and edge devices. Pruning has emerged as a promising direction for reducing ViT complexity. However, existing approaches either (i) produce a single pruned model shared across all devices, ignoring device heterogeneity, or (ii) rely on fine-tuning with device-local data, which is often infeasible due to limited on-device resources and strict privacy constraints. As a result, current methods fall short of enabling task-customized ViT pruning in privacy-preserving mobile computing settings. This paper introduces TAP-ViTs, a novel task-adaptive pruning framework that generates device-specific pruned ViT models without requiring access to any raw local data. Specifically, to infer device-level task characteristics under privacy constraints, we propose a Gaussian Mixture Model (GMM)-based metric dataset construction mechanism. Each device fits a lightweight GMM to approximate its private data distribution and uploads only the GMM parameters. Using these parameters, the cloud selects distribution-consistent samples from public data to construct a task-representative metric dataset for each device. Based on this proxy dataset, we further develop a dual-granularity importance evaluation-based pruning strategy that jointly measures composite neuron importance and adaptive layer importance, enabling fine-grained, task-aware pruning tailored to each device's computational budget. Extensive experiments across multiple ViT backbones and datasets demonstrate that TAP-ViTs consistently outperforms state-of-the-art pruning methods under comparable compression ratios.
Avatar4D: Synthesizing Domain-Specific 4D Humans for Real-World Pose Estimation
Dec 18, 2025We present Avatar4D, a real-world transferable pipeline for generating customizable synthetic human motion datasets tailored to domain-specific applications. Unlike prior works, which focus on general, everyday motions and offer limited flexibility, our approach provides fine-grained control over body pose, appearance, camera viewpoint, and environmental context, without requiring any manual annotations. To validate the impact of Avatar4D, we focus on sports, where domain-specific human actions and movement patterns pose unique challenges for motion understanding. In this setting, we introduce Syn2Sport, a large-scale synthetic dataset spanning sports, including baseball and ice hockey. Avatar4D features high-fidelity 4D (3D geometry over time) human motion sequences with varying player appearances rendered in diverse environments. We benchmark several state-of-the-art pose estimation models on Syn2Sport and demonstrate their effectiveness for supervised learning, zero-shot transfer to real-world data, and generalization across sports. Furthermore, we evaluate how closely the generated synthetic data aligns with real-world datasets in feature space. Our results highlight the potential of such systems to generate scalable, controllable, and transferable human datasets for diverse domain-specific tasks without relying on domain-specific real data.
UniSearch: Rethinking Search System with a Unified Generative Architecture
Sep 10, 2025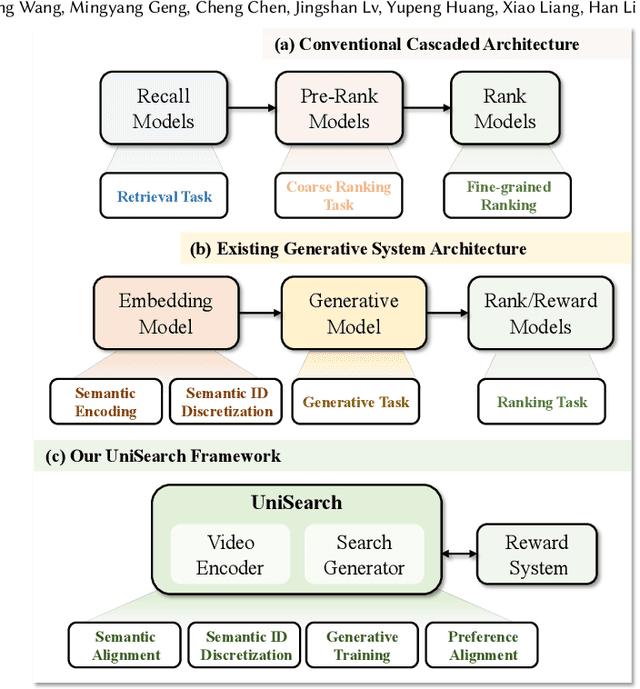
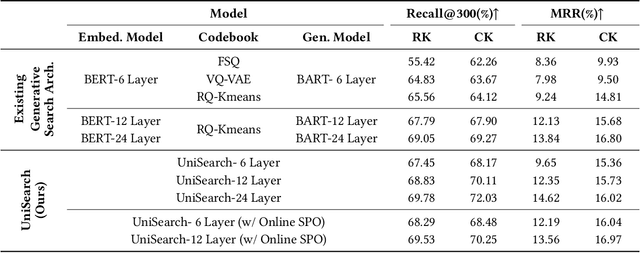
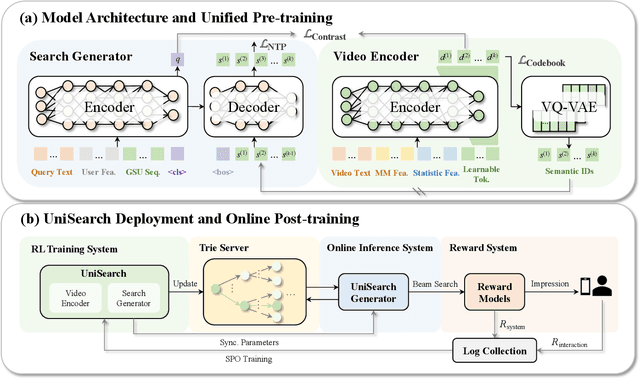
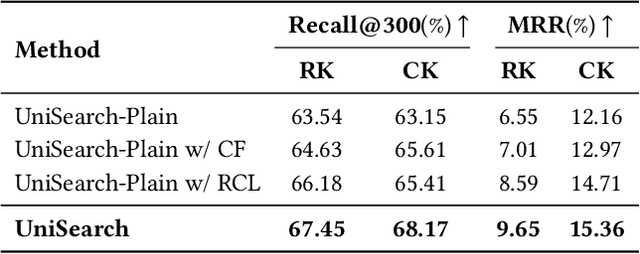
Modern search systems play a crucial role in facilitating information acquisition. Traditional search engines typically rely on a cascaded architecture, where results are retrieved through recall, pre-ranking, and ranking stages. The complexity of designing and maintaining multiple modules makes it difficult to achieve holistic performance gains. Recent advances in generative recommendation have motivated the exploration of unified generative search as an alternative. However, existing approaches are not genuinely end-to-end: they typically train an item encoder to tokenize candidates first and then optimize a generator separately, leading to objective inconsistency and limited generalization. To address these limitations, we propose UniSearch, a unified generative search framework for Kuaishou Search. UniSearch replaces the cascaded pipeline with an end-to-end architecture that integrates a Search Generator and a Video Encoder. The Generator produces semantic identifiers of relevant items given a user query, while the Video Encoder learns latent item embeddings and provides their tokenized representations. A unified training framework jointly optimizes both components, enabling mutual enhancement and improving representation quality and generation accuracy. Furthermore, we introduce Search Preference Optimization (SPO), which leverages a reward model and real user feedback to better align generation with user preferences. Extensive experiments on industrial-scale datasets, together with online A/B testing in both short-video and live search scenarios, demonstrate the strong effectiveness and deployment potential of UniSearch. Notably, its deployment in live search yields the largest single-experiment improvement in recent years of our product's history, highlighting its practical value for real-world applications.
AFLoRA: Adaptive Federated Fine-Tuning of Large Language Models with Resource-Aware Low-Rank Adaption
May 30, 2025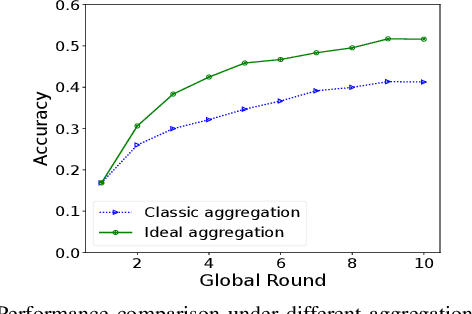
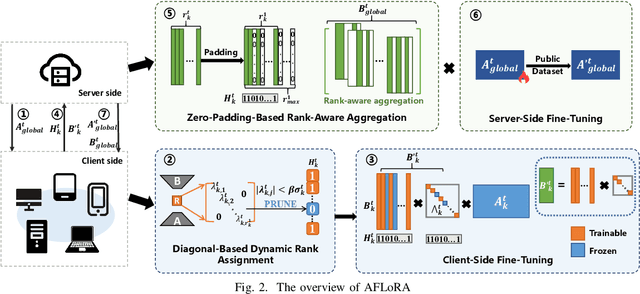
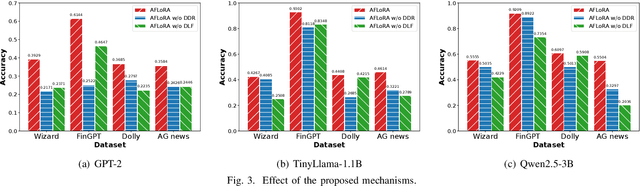
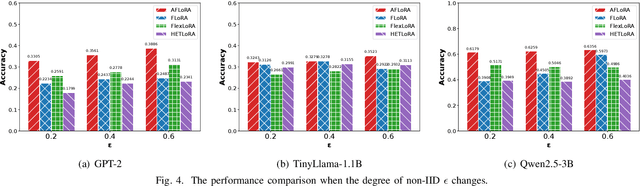
Federated fine-tuning has emerged as a promising approach to adapt foundation models to downstream tasks using decentralized data. However, real-world deployment remains challenging due to the high computational and communication demands of fine-tuning Large Language Models (LLMs) on clients with data and system resources that are heterogeneous and constrained. In such settings, the global model's performance is often bottlenecked by the weakest clients and further degraded by the non-IID nature of local data. Although existing methods leverage parameter-efficient techniques such as Low-Rank Adaptation (LoRA) to reduce communication and computation overhead, they often fail to simultaneously ensure accurate aggregation of low-rank updates and maintain low system costs, thereby hindering overall performance. To address these challenges, we propose AFLoRA, an adaptive and lightweight federated fine-tuning framework for LLMs. AFLoRA decouples shared and client-specific updates to reduce overhead and improve aggregation accuracy, incorporates diagonal matrix-based rank pruning to better utilize local resources, and employs rank-aware aggregation with public data refinement to strengthen generalization under data heterogeneity. Extensive experiments demonstrate that AFLoRA outperforms state-of-the-art methods in both accuracy and efficiency, providing a practical solution for efficient LLM adaptation in heterogeneous environments in the real world.
Personalized Query Auto-Completion for Long and Short-Term Interests with Adaptive Detoxification Generation
May 27, 2025Query auto-completion (QAC) plays a crucial role in modern search systems. However, in real-world applications, there are two pressing challenges that still need to be addressed. First, there is a need for hierarchical personalized representations for users. Previous approaches have typically used users' search behavior as a single, overall representation, which proves inadequate in more nuanced generative scenarios. Additionally, query prefixes are typically short and may contain typos or sensitive information, increasing the likelihood of generating toxic content compared to traditional text generation tasks. Such toxic content can degrade user experience and lead to public relations issues. Therefore, the second critical challenge is detoxifying QAC systems. To address these two limitations, we propose a novel model (LaD) that captures personalized information from both long-term and short-term interests, incorporating adaptive detoxification. In LaD, personalized information is captured hierarchically at both coarse-grained and fine-grained levels. This approach preserves as much personalized information as possible while enabling online generation within time constraints. To move a futher step, we propose an online training method based on Reject Preference Optimization (RPO). By incorporating a special token [Reject] during both the training and inference processes, the model achieves adaptive detoxification. Consequently, the generated text presented to users is both non-toxic and relevant to the given prefix. We conduct comprehensive experiments on industrial-scale datasets and perform online A/B tests, delivering the largest single-experiment metric improvement in nearly two years of our product. Our model has been deployed on Kuaishou search, driving the primary traffic for hundreds of millions of active users. The code is available at https://github.com/JXZe/LaD.
PRUNE: A Patching Based Repair Framework for Certiffable Unlearning of Neural Networks
May 10, 2025It is often desirable to remove (a.k.a. unlearn) a speciffc part of the training data from a trained neural network model. A typical application scenario is to protect the data holder's right to be forgotten, which has been promoted by many recent regulation rules. Existing unlearning methods involve training alternative models with remaining data, which may be costly and challenging to verify from the data holder or a thirdparty auditor's perspective. In this work, we provide a new angle and propose a novel unlearning approach by imposing carefully crafted "patch" on the original neural network to achieve targeted "forgetting" of the requested data to delete. Speciffcally, inspired by the research line of neural network repair, we propose to strategically seek a lightweight minimum "patch" for unlearning a given data point with certiffable guarantee. Furthermore, to unlearn a considerable amount of data points (or an entire class), we propose to iteratively select a small subset of representative data points to unlearn, which achieves the effect of unlearning the whole set. Extensive experiments on multiple categorical datasets demonstrates our approach's effectiveness, achieving measurable unlearning while preserving the model's performance and being competitive in efffciency and memory consumption compared to various baseline methods.