 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Provably Unlearnable Examples via Bayes Error Optimisation
Nov 11, 2025



The recent success of machine learning models, especially large-scale classifiers and language models, relies heavily on training with massive data. These data are often collected from online sources. This raises serious concerns about the protection of user data, as individuals may not have given consent for their data to be used in training. To address this concern, recent studies introduce the concept of unlearnable examples, i.e., data instances that appear natural but are intentionally altered to prevent models from effectively learning from them. While existing methods demonstrate empirical effectiveness, they typically rely on heuristic trials and lack formal guarantees. Besides, when unlearnable examples are mixed with clean data, as is often the case in practice, their unlearnability disappears. In this work, we propose a novel approach to constructing unlearnable examples by systematically maximising the Bayes error, a measurement of irreducible classification error. We develop an optimisation-based approach and provide an efficient solution using projected gradient ascent. Our method provably increases the Bayes error and remains effective when the unlearning examples are mixed with clean samples. Experimental results across multiple datasets and model architectures are consistent with our theoretical analysis and show that our approach can restrict data learnability, effectively in practice.
PRUNE: A Patching Based Repair Framework for Certiffable Unlearning of Neural Networks
May 10, 2025It is often desirable to remove (a.k.a. unlearn) a speciffc part of the training data from a trained neural network model. A typical application scenario is to protect the data holder's right to be forgotten, which has been promoted by many recent regulation rules. Existing unlearning methods involve training alternative models with remaining data, which may be costly and challenging to verify from the data holder or a thirdparty auditor's perspective. In this work, we provide a new angle and propose a novel unlearning approach by imposing carefully crafted "patch" on the original neural network to achieve targeted "forgetting" of the requested data to delete. Speciffcally, inspired by the research line of neural network repair, we propose to strategically seek a lightweight minimum "patch" for unlearning a given data point with certiffable guarantee. Furthermore, to unlearn a considerable amount of data points (or an entire class), we propose to iteratively select a small subset of representative data points to unlearn, which achieves the effect of unlearning the whole set. Extensive experiments on multiple categorical datasets demonstrates our approach's effectiveness, achieving measurable unlearning while preserving the model's performance and being competitive in efffciency and memory consumption compared to various baseline methods.
RedTest: Towards Measuring Redundancy in Deep Neural Networks Effectively
Nov 15, 2024



Deep learning has revolutionized computing in many real-world applications, arguably due to its remarkable performance and extreme convenience as an end-to-end solution. However, deep learning models can be costly to train and to use, especially for those large-scale models, making it necessary to optimize the original overly complicated models into smaller ones in scenarios with limited resources such as mobile applications or simply for resource saving. The key question in such model optimization is, how can we effectively identify and measure the redundancy in a deep learning model structure. While several common metrics exist in the popular model optimization techniques to measure the performance of models after optimization, they are not able to quantitatively inform the degree of remaining redundancy. To address the problem, we present a novel testing approach, i.e., RedTest, which proposes a novel testing metric called Model Structural Redundancy Score (MSRS) to quantitatively measure the degree of redundancy in a deep learning model structure. We first show that MSRS is effective in both revealing and assessing the redundancy issues in many state-of-the-art models, which urgently calls for model optimization. Then, we utilize MSRS to assist deep learning model developers in two practical application scenarios: 1) in Neural Architecture Search, we design a novel redundancy-aware algorithm to guide the search for the optimal model structure and demonstrate its effectiveness by comparing it to existing standard NAS practice; 2) in the pruning of large-scale pre-trained models, we prune the redundant layers of pre-trained models with the guidance of layer similarity to derive less redundant ones of much smaller size. Extensive experimental results demonstrate that removing such redundancy has a negligible effect on the model utility.
LLMScan: Causal Scan for LLM Misbehavior Detection
Oct 23, 2024



Despite the success of Large Language Models (LLMs) across various fields, their potential to generate untruthful, biased and harmful responses poses significant risks, particularly in critical applications. This highlights the urgent need for systematic methods to detect and prevent such misbehavior. While existing approaches target specific issues such as harmful responses, this work introduces LLMScan, an innovative LLM monitoring technique based on causality analysis, offering a comprehensive solution. LLMScan systematically monitors the inner workings of an LLM through the lens of causal inference, operating on the premise that the LLM's `brain' behaves differently when misbehaving. By analyzing the causal contributions of the LLM's input tokens and transformer layers, LLMScan effectively detects misbehavior. Extensive experiments across various tasks and models reveal clear distinctions in the causal distributions between normal behavior and misbehavior, enabling the development of accurate, lightweight detectors for a variety of misbehavior detection tasks.
Towards Certified Probabilistic Robustness with High Accuracy
Sep 02, 2023Adversarial examples pose a security threat to many critical systems built on neural networks (such as face recognition systems, and self-driving cars). While many methods have been proposed to build robust models, how to build certifiably robust yet accurate neural network models remains an open problem. For example, adversarial training improves empirical robustness, but they do not provide certification of the model's robustness. On the other hand, certified training provides certified robustness but at the cost of a significant accuracy drop. In this work, we propose a novel approach that aims to achieve both high accuracy and certified probabilistic robustness. Our method has two parts, i.e., a probabilistic robust training method with an additional goal of minimizing variance in terms of divergence and a runtime inference method for certified probabilistic robustness of the prediction. The latter enables efficient certification of the model's probabilistic robustness at runtime with statistical guarantees. This is supported by our training objective, which minimizes the variance of the model's predictions in a given vicinity, derived from a general definition of model robustness. Our approach works for a variety of perturbations and is reasonably efficient. Our experiments on multiple models trained on different datasets demonstrate that our approach significantly outperforms existing approaches in terms of both certification rate and accuracy.
Fairness Testing of Deep Image Classification with Adequacy Metrics
Dec 01, 2021


As deep image classification applications, e.g., face recognition, become increasingly prevalent in our daily lives, their fairness issues raise more and more concern. It is thus crucial to comprehensively test the fairness of these applications before deployment. Existing fairness testing methods suffer from the following limitations: 1) applicability, i.e., they are only applicable for structured data or text without handling the high-dimensional and abstract domain sampling in the semantic level for image classification applications; 2) functionality, i.e., they generate unfair samples without providing testing criterion to characterize the model's fairness adequacy. To fill the gap, we propose DeepFAIT, a systematic fairness testing framework specifically designed for deep image classification applications. DeepFAIT consists of several important components enabling effective fairness testing of deep image classification applications: 1) a neuron selection strategy to identify the fairness-related neurons; 2) a set of multi-granularity adequacy metrics to evaluate the model's fairness; 3) a test selection algorithm for fixing the fairness issues efficiently. We have conducted experiments on widely adopted large-scale face recognition applications, i.e., VGGFace and FairFace. The experimental results confirm that our approach can effectively identify the fairness-related neurons, characterize the model's fairness, and select the most valuable test cases to mitigate the model's fairness issues.
Automatic Fairness Testing of Neural Classifiers through Adversarial Sampling
Jul 29, 2021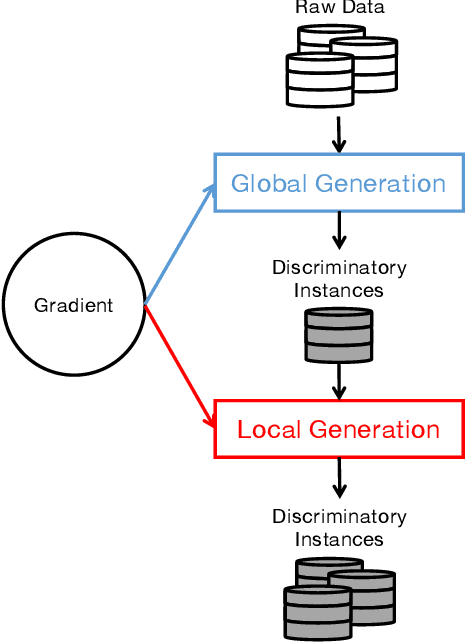

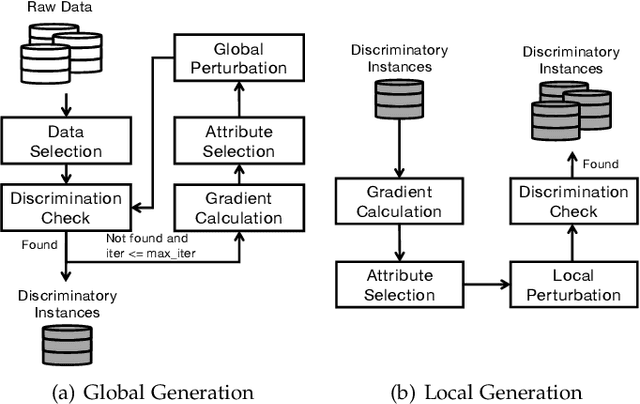
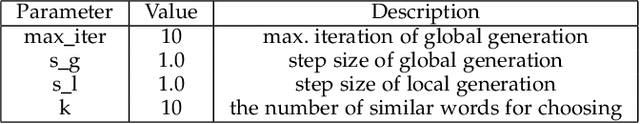
Although deep learning has demonstrated astonishing performance in many applications, there are still concerns about its dependability. One desirable property of deep learning applications with societal impact is fairness (i.e., non-discrimination). Unfortunately, discrimination might be intrinsically embedded into the models due to the discrimination in the training data. As a countermeasure, fairness testing systemically identifies discriminatory samples, which can be used to retrain the model and improve the model's fairness. Existing fairness testing approaches however have two major limitations. Firstly, they only work well on traditional machine learning models and have poor performance (e.g., effectiveness and efficiency) on deep learning models. Secondly, they only work on simple structured (e.g., tabular) data and are not applicable for domains such as text. In this work, we bridge the gap by proposing a scalable and effective approach for systematically searching for discriminatory samples while extending existing fairness testing approaches to address a more challenging domain, i.e., text classification. Compared with state-of-the-art methods, our approach only employs lightweight procedures like gradient computation and clustering, which is significantly more scalable and effective. Experimental results show that on average, our approach explores the search space much more effectively (9.62 and 2.38 times more than the state-of-the-art methods respectively on tabular and text datasets) and generates much more discriminatory samples (24.95 and 2.68 times) within a same reasonable time. Moreover, the retrained models reduce discrimination by 57.2% and 60.2% respectively on average.
There is Limited Correlation between Coverage and Robustness for Deep Neural Networks
Nov 14, 2019
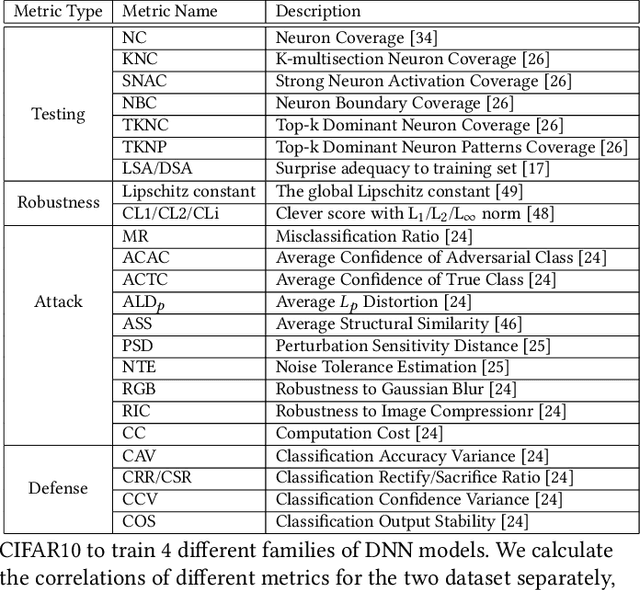
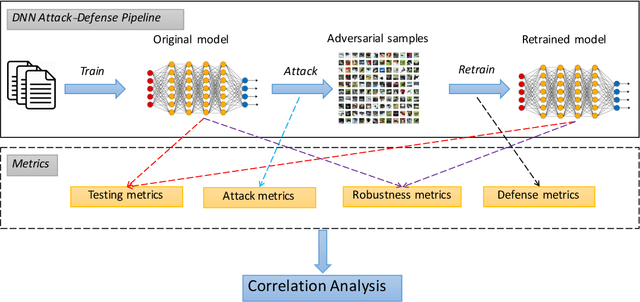

Deep neural networks (DNN) are increasingly applied in safety-critical systems, e.g., for face recognition, autonomous car control and malware detection. It is also shown that DNNs are subject to attacks such as adversarial perturbation and thus must be properly tested. Many coverage criteria for DNN since have been proposed, inspired by the success of code coverage criteria for software programs. The expectation is that if a DNN is a well tested (and retrained) according to such coverage criteria, it is more likely to be robust. In this work, we conduct an empirical study to evaluate the relationship between coverage, robustness and attack/defense metrics for DNN. Our study is the largest to date and systematically done based on 100 DNN models and 25 metrics. One of our findings is that there is limited correlation between coverage and robustness, i.e., improving coverage does not help improve the robustness. Our dataset and implementation have been made available to serve as a benchmark for future studies on testing DNN.
Adversarial Sample Detection for Deep Neural Network through Model Mutation Testing
Jan 18, 2019
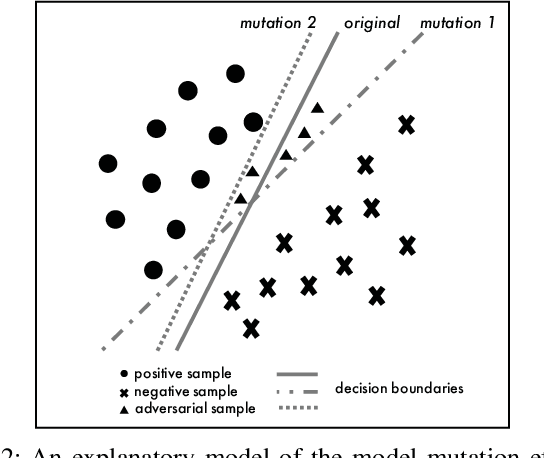
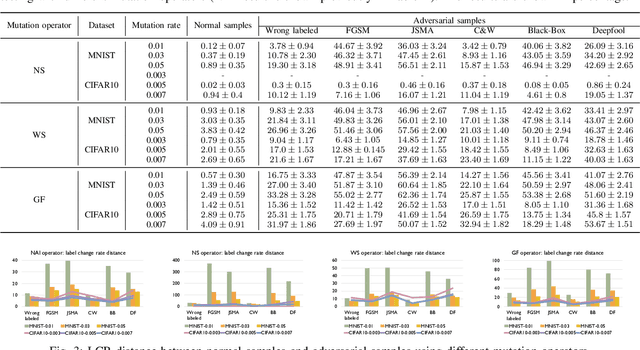
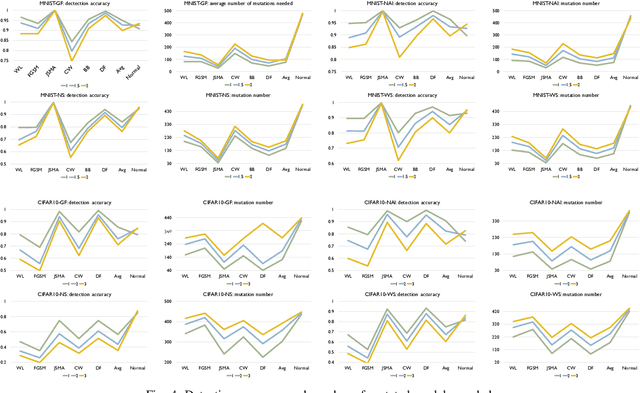
Deep neural networks (DNN) have been shown to be useful in a wide range of applications. However, they are also known to be vulnerable to adversarial samples. By transforming a normal sample with some carefully crafted human imperceptible perturbations, even highly accurate DNN make wrong decisions. Multiple defense mechanisms have been proposed which aim to hinder the generation of such adversarial samples. However, a recent work show that most of them are ineffective. In this work, we propose an alternative approach to detect adversarial samples at runtime. Our main observation is that adversarial samples are much more sensitive than normal samples if we impose random mutations on the DNN. We thus first propose a measure of `sensitivity' and show empirically that normal samples and adversarial samples have distinguishable sensitivity. We then integrate statistical hypothesis testing and model mutation testing to check whether an input sample is likely to be normal or adversarial at runtime by measuring its sensitivity. We evaluated our approach on the MNIST and CIFAR10 datasets. The results show that our approach detects adversarial samples generated by state-of-the-art attacking methods efficiently and accurately.
Detecting Adversarial Samples for Deep Neural Networks through Mutation Testing
May 17, 2018



Recently, it has been shown that deep neural networks (DNN) are subject to attacks through adversarial samples. Adversarial samples are often crafted through adversarial perturbation, i.e., manipulating the original sample with minor modifications so that the DNN model labels the sample incorrectly. Given that it is almost impossible to train perfect DNN, adversarial samples are shown to be easy to generate. As DNN are increasingly used in safety-critical systems like autonomous cars, it is crucial to develop techniques for defending such attacks. Existing defense mechanisms which aim to make adversarial perturbation challenging have been shown to be ineffective. In this work, we propose an alternative approach. We first observe that adversarial samples are much more sensitive to perturbations than normal samples. That is, if we impose random perturbations on a normal and an adversarial sample respectively, there is a significant difference between the ratio of label change due to the perturbations. Observing this, we design a statistical adversary detection algorithm called nMutant (inspired by mutation testing from software engineering community). Our experiments show that nMutant effectively detects most of the adversarial samples generated by recently proposed attacking methods. Furthermore, we provide an error bound with certain statistical significance along with the detection.