 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Ownership Verification in Contrastive Pre-trained Models
Feb 11, 2025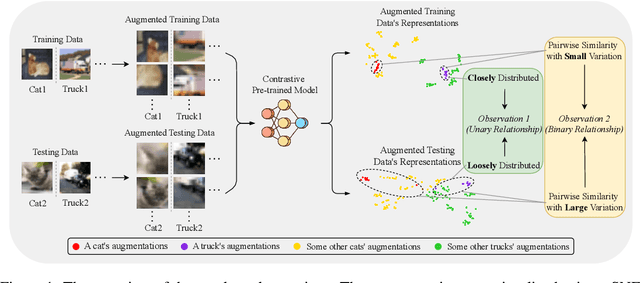
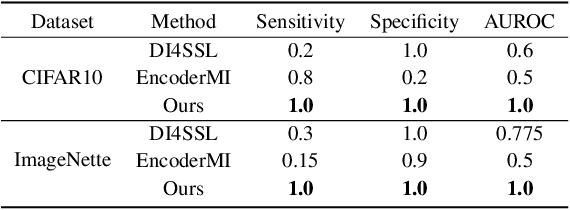
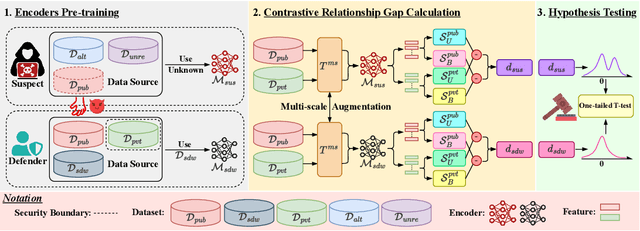
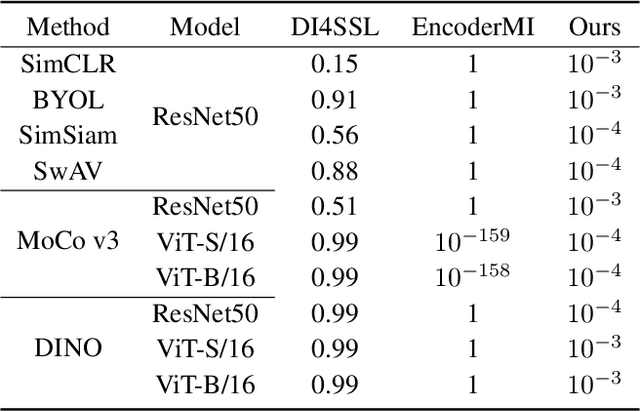
High-quality open-source datasets, which necessitate substantial efforts for curation, has become the primary catalyst for the swift progress of deep learning. Concurrently, protecting these datasets is paramount for the well-being of the data owner. Dataset ownership verification emerges as a crucial method in this domain, but existing approaches are often limited to supervised models and cannot be directly extended to increasingly popular unsupervised pre-trained models. In this work, we propose the first dataset ownership verification method tailored specifically for self-supervised pre-trained models by contrastive learning. Its primary objective is to ascertain whether a suspicious black-box backbone has been pre-trained on a specific unlabeled dataset, aiding dataset owners in upholding their rights. The proposed approach is motivated by our empirical insights that when models are trained with the target dataset, the unary and binary instance relationships within the embedding space exhibit significant variations compared to models trained without the target dataset. We validate the efficacy of this approach across multiple contrastive pre-trained models including SimCLR, BYOL, SimSiam, MOCO v3, and DINO. The results demonstrate that our method rejects the null hypothesis with a $p$-value markedly below $0.05$, surpassing all previous methodologies. Our code is available at https://github.com/xieyc99/DOV4CL.
LG-CAV: Train Any Concept Activation Vector with Language Guidance
Oct 14, 2024



Concept activation vector (CAV) has attracted broad research interest in explainable AI, by elegantly attributing model predictions to specific concepts. However, the training of CAV often necessitates a large number of high-quality images, which are expensive to curate and thus limited to a predefined set of concepts. To address this issue, we propose Language-Guided CAV (LG-CAV) to harness the abundant concept knowledge within the certain pre-trained vision-language models (e.g., CLIP). This method allows training any CAV without labeled data, by utilizing the corresponding concept descriptions as guidance. To bridge the gap between vision-language model and the target model, we calculate the activation values of concept descriptions on a common pool of images (probe images) with vision-language model and utilize them as language guidance to train the LG-CAV. Furthermore, after training high-quality LG-CAVs related to all the predicted classes in the target model, we propose the activation sample reweighting (ASR), serving as a model correction technique, to improve the performance of the target model in return. Experiments on four datasets across nine architectures demonstrate that LG-CAV achieves significantly superior quality to previous CAV methods given any concept, and our model correction method achieves state-of-the-art performance compared to existing concept-based methods. Our code is available at https://github.com/hqhQAQ/LG-CAV.
Transition Propagation Graph Neural Networks for Temporal Networks
Apr 15, 2023
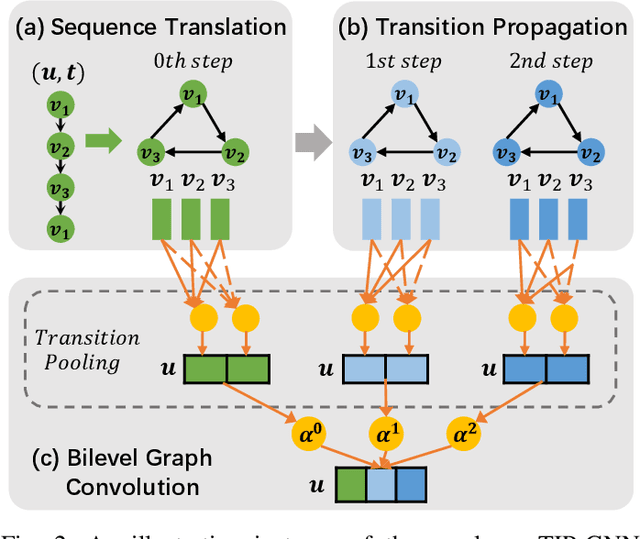
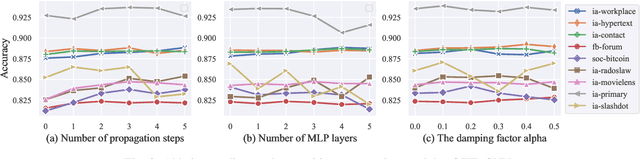
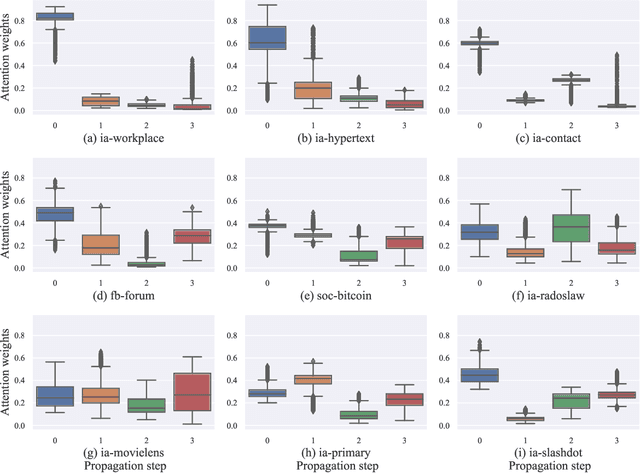
Researchers of temporal networks (e.g., social networks and transaction networks) have been interested in mining dynamic patterns of nodes from their diverse interactions. Inspired by recently powerful graph mining methods like skip-gram models and Graph Neural Networks (GNNs), existing approaches focus on generating temporal node embeddings sequentially with nodes' sequential interactions. However, the sequential modeling of previous approaches cannot handle the transition structure between nodes' neighbors with limited memorization capacity. Detailedly, an effective method for the transition structures is required to both model nodes' personalized patterns adaptively and capture node dynamics accordingly. In this paper, we propose a method, namely Transition Propagation Graph Neural Networks (TIP-GNN), to tackle the challenges of encoding nodes' transition structures. The proposed TIP-GNN focuses on the bilevel graph structure in temporal networks: besides the explicit interaction graph, a node's sequential interactions can also be constructed as a transition graph. Based on the bilevel graph, TIP-GNN further encodes transition structures by multi-step transition propagation and distills information from neighborhoods by a bilevel graph convolution. Experimental results over various temporal networks reveal the efficiency of our TIP-GNN, with at most 7.2\% improvements of accuracy on temporal link prediction. Extensive ablation studies further verify the effectiveness and limitations of the transition propagation module. Our code is available at \url{https://github.com/doujiang-zheng/TIP-GNN}.
Temporal Aggregation and Propagation Graph Neural Networks for Dynamic Representation
Apr 15, 2023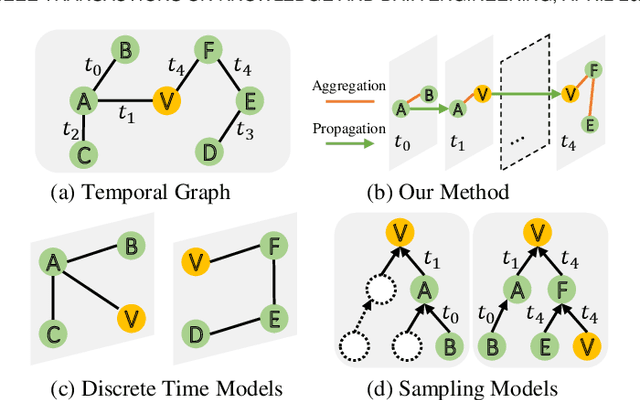
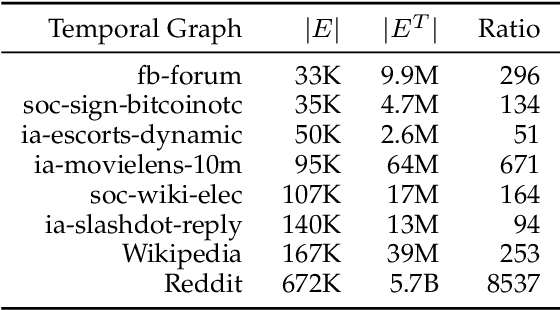
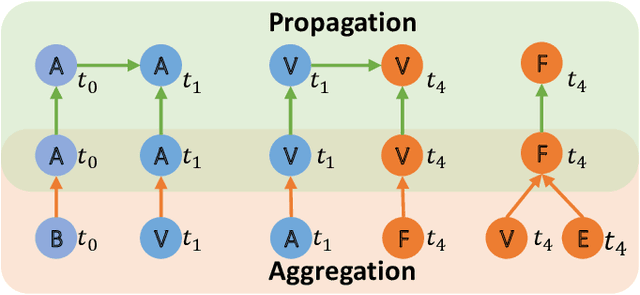
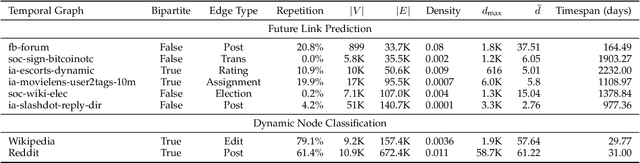
Temporal graphs exhibit dynamic interactions between nodes over continuous time, whose topologies evolve with time elapsing. The whole temporal neighborhood of nodes reveals the varying preferences of nodes. However, previous works usually generate dynamic representation with limited neighbors for simplicity, which results in both inferior performance and high latency of online inference. Therefore, in this paper, we propose a novel method of temporal graph convolution with the whole neighborhood, namely Temporal Aggregation and Propagation Graph Neural Networks (TAP-GNN). Specifically, we firstly analyze the computational complexity of the dynamic representation problem by unfolding the temporal graph in a message-passing paradigm. The expensive complexity motivates us to design the AP (aggregation and propagation) block, which significantly reduces the repeated computation of historical neighbors. The final TAP-GNN supports online inference in the graph stream scenario, which incorporates the temporal information into node embeddings with a temporal activation function and a projection layer besides several AP blocks. Experimental results on various real-life temporal networks show that our proposed TAP-GNN outperforms existing temporal graph methods by a large margin in terms of both predictive performance and online inference latency. Our code is available at \url{https://github.com/doujiang-zheng/TAP-GNN}.
Learning Dynamic Preference Structure Embedding From Temporal Networks
Nov 23, 2021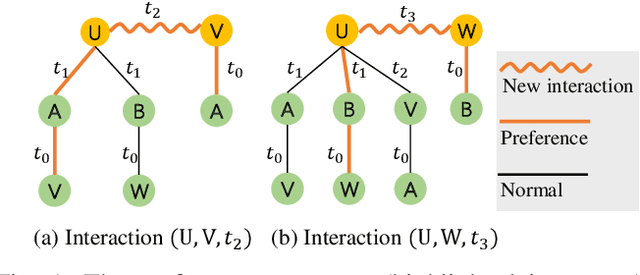
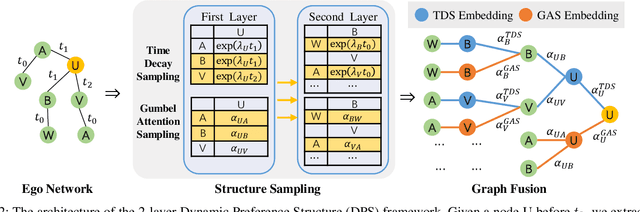
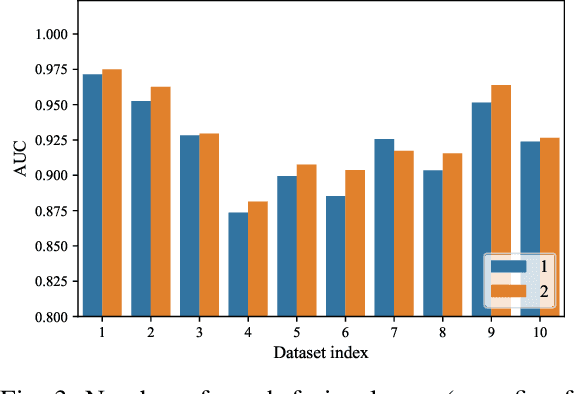
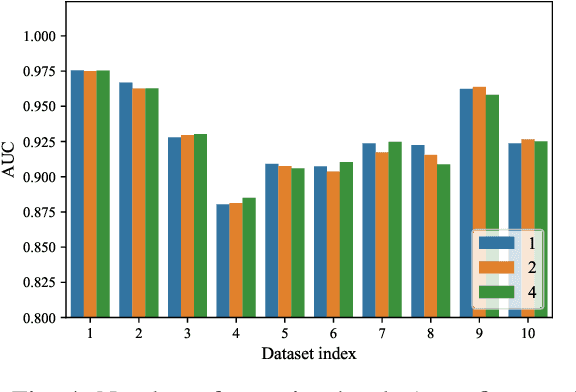
The dynamics of temporal networks lie in the continuous interactions between nodes, which exhibit the dynamic node preferences with time elapsing. The challenges of mining temporal networks are thus two-fold: the dynamic structure of networks and the dynamic node preferences. In this paper, we investigate the dynamic graph sampling problem, aiming to capture the preference structure of nodes dynamically in cooperation with GNNs. Our proposed Dynamic Preference Structure (DPS) framework consists of two stages: structure sampling and graph fusion. In the first stage, two parameterized samplers are designed to learn the preference structure adaptively with network reconstruction tasks. In the second stage, an additional attention layer is designed to fuse two sampled temporal subgraphs of a node, generating temporal node embeddings for downstream tasks. Experimental results on many real-life temporal networks show that our DPS outperforms several state-of-the-art methods substantially owing to learning an adaptive preference structure. The code will be released soon at https://github.com/doujiang-zheng/Dynamic-Preference-Structure.
Automatic Fairness Testing of Neural Classifiers through Adversarial Sampling
Jul 29, 2021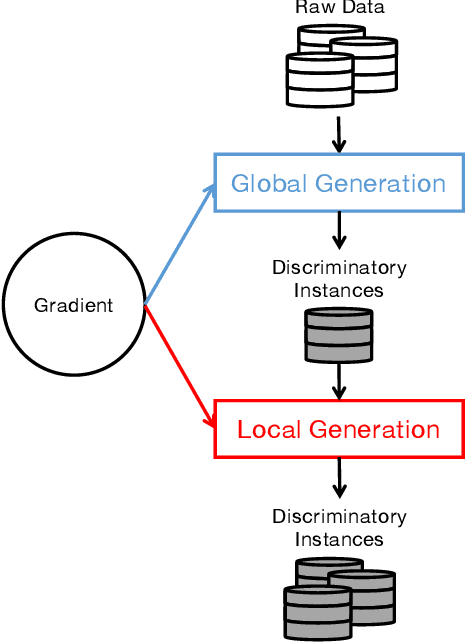

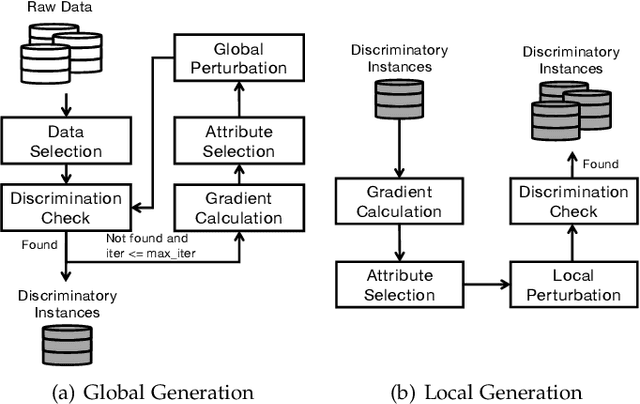
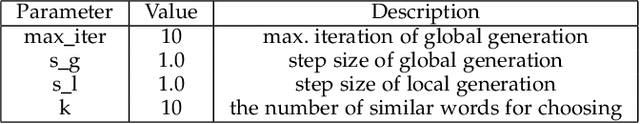
Although deep learning has demonstrated astonishing performance in many applications, there are still concerns about its dependability. One desirable property of deep learning applications with societal impact is fairness (i.e., non-discrimination). Unfortunately, discrimination might be intrinsically embedded into the models due to the discrimination in the training data. As a countermeasure, fairness testing systemically identifies discriminatory samples, which can be used to retrain the model and improve the model's fairness. Existing fairness testing approaches however have two major limitations. Firstly, they only work well on traditional machine learning models and have poor performance (e.g., effectiveness and efficiency) on deep learning models. Secondly, they only work on simple structured (e.g., tabular) data and are not applicable for domains such as text. In this work, we bridge the gap by proposing a scalable and effective approach for systematically searching for discriminatory samples while extending existing fairness testing approaches to address a more challenging domain, i.e., text classification. Compared with state-of-the-art methods, our approach only employs lightweight procedures like gradient computation and clustering, which is significantly more scalable and effective. Experimental results show that on average, our approach explores the search space much more effectively (9.62 and 2.38 times more than the state-of-the-art methods respectively on tabular and text datasets) and generates much more discriminatory samples (24.95 and 2.68 times) within a same reasonable time. Moreover, the retrained models reduce discrimination by 57.2% and 60.2% respectively on average.
Contrastive Model Inversion for Data-Free Knowledge Distillation
May 18, 2021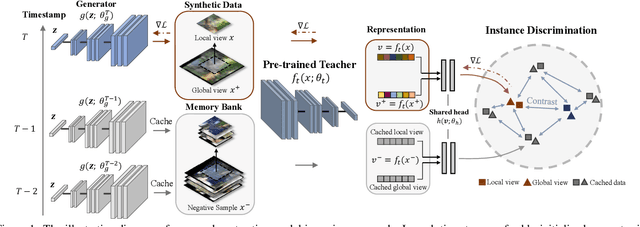
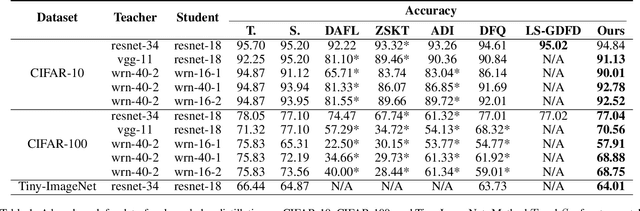


Model inversion, whose goal is to recover training data from a pre-trained model, has been recently proved feasible. However, existing inversion methods usually suffer from the mode collapse problem, where the synthesized instances are highly similar to each other and thus show limited effectiveness for downstream tasks, such as knowledge distillation. In this paper, we propose Contrastive Model Inversion~(CMI), where the data diversity is explicitly modeled as an optimizable objective, to alleviate the mode collapse issue. Our main observation is that, under the constraint of the same amount of data, higher data diversity usually indicates stronger instance discrimination. To this end, we introduce in CMI a contrastive learning objective that encourages the synthesizing instances to be distinguishable from the already synthesized ones in previous batches. Experiments of pre-trained models on CIFAR-10, CIFAR-100, and Tiny-ImageNet demonstrate that CMI not only generates more visually plausible instances than the state of the arts, but also achieves significantly superior performance when the generated data are used for knowledge distillation. Code is available at \url{https://github.com/zju-vipa/DataFree}.
KDExplainer: A Task-oriented Attention Model for Explaining Knowledge Distillation
May 12, 2021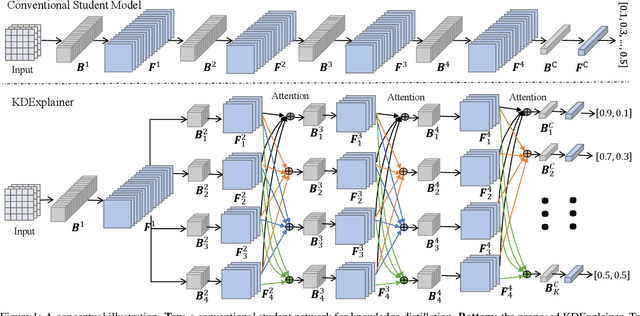
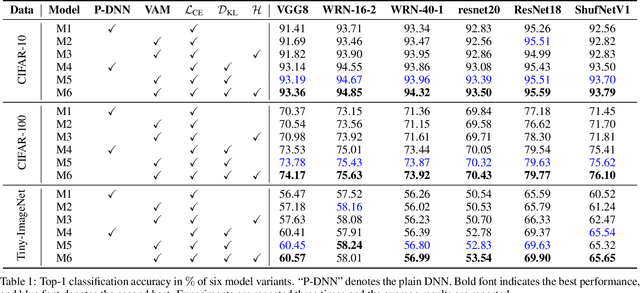
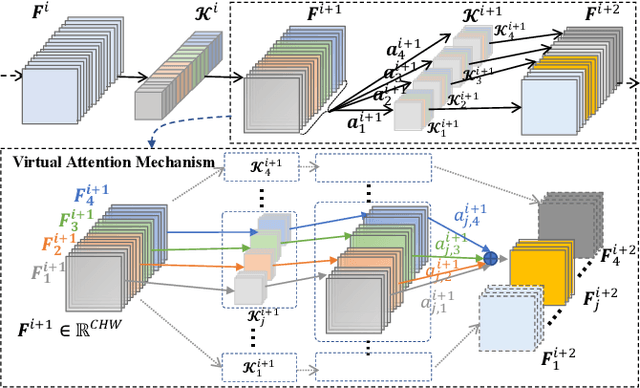
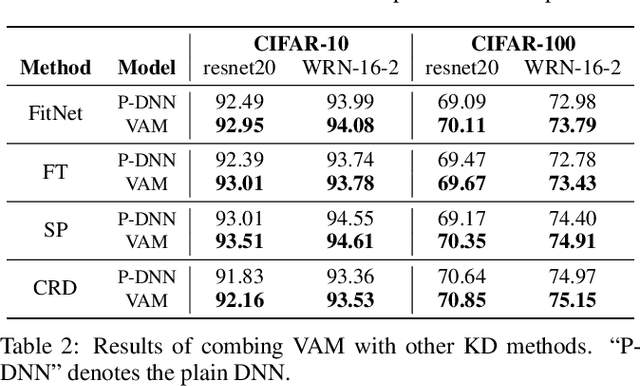
Knowledge distillation (KD) has recently emerged as an efficacious scheme for learning compact deep neural networks (DNNs). Despite the promising results achieved, the rationale that interprets the behavior of KD has yet remained largely understudied. In this paper, we introduce a novel task-oriented attention model, termed as KDExplainer, to shed light on the working mechanism underlying the vanilla KD. At the heart of KDExplainer is a Hierarchical Mixture of Experts (HME), in which a multi-class classification is reformulated as a multi-task binary one. Through distilling knowledge from a free-form pre-trained DNN to KDExplainer, we observe that KD implicitly modulates the knowledge conflicts between different subtasks, and in reality has much more to offer than label smoothing. Based on such findings, we further introduce a portable tool, dubbed as virtual attention module (VAM), that can be seamlessly integrated with various DNNs to enhance their performance under KD. Experimental results demonstrate that with a negligible additional cost, student models equipped with VAM consistently outperform their non-VAM counterparts across different benchmarks. Furthermore, when combined with other KD methods, VAM remains competent in promoting results, even though it is only motivated by vanilla KD. The code is available at https://github.com/zju-vipa/KDExplainer.